
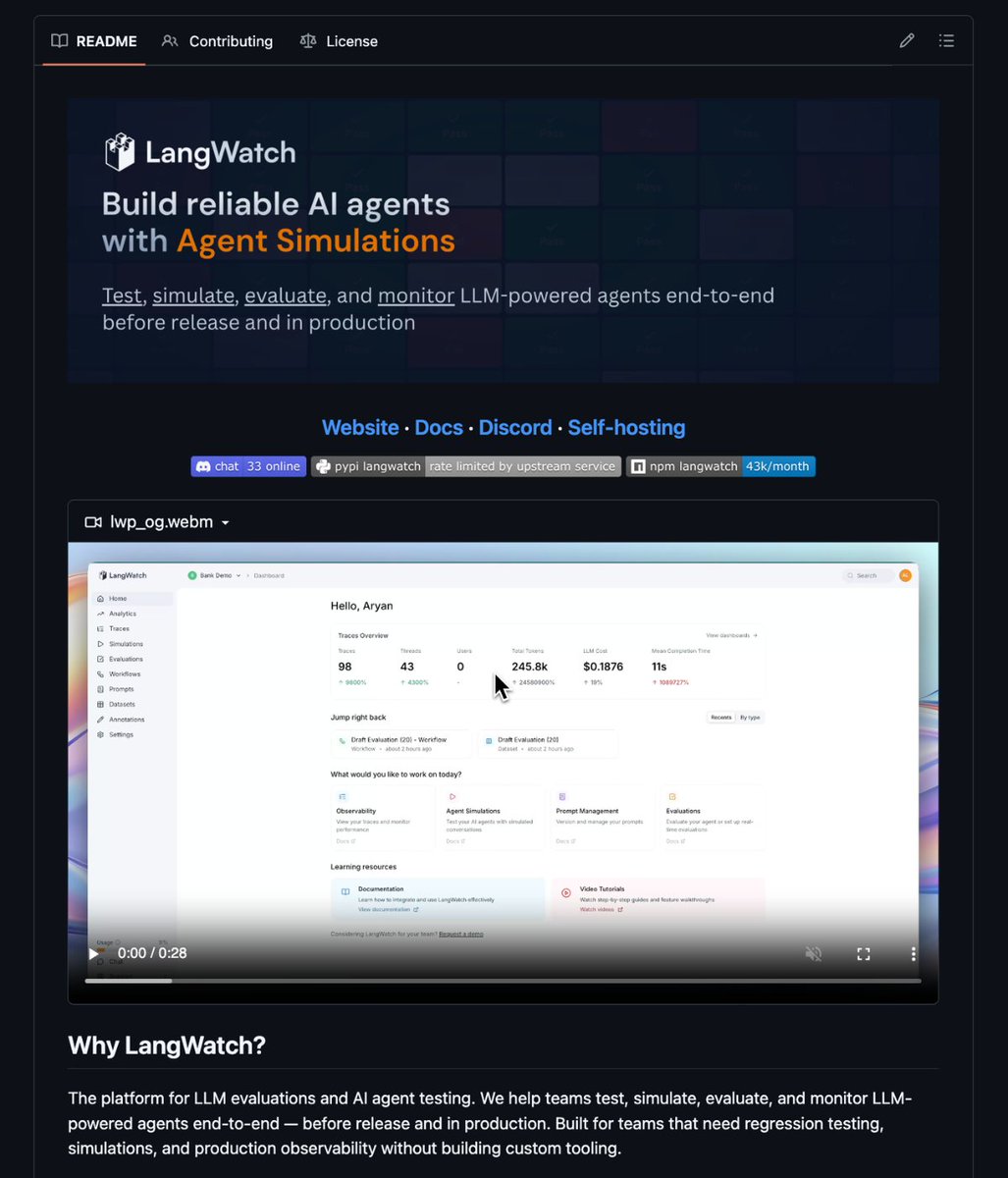
LangWatch
145 posts

LangWatch
@LangWatchAI
Open Source platform for LLM observability, evaluation and agent https://t.co/CrsnEmal2g ➡️ DSPy Optimizations ➡️ Scenario Agent Simulations
Katılım Nisan 2024
218 Takip Edilen613 Takipçiler

@hasantoxr oh interesting. agent eval stacks start to get powerful once traces become reproducible artifacts — curious if langwatch can replay the same agent run across different models or prompt revisions?
English

🚨 BREAKING: Someone just open sourced the missing layer for AI agents and it's genuinely insane.
It's called LangWatch. The complete platform for LLM evaluation and AI agent testing trace, evaluate, simulate, and monitor your agents end-to-end before a single user sees them.
Here's what you actually get:
→ End-to-end agent simulations - run full-stack scenarios (tools, state, user simulator, judge) and pinpoint exactly where your agent breaks, decision by decision
→ Closed eval loop - Trace → Dataset → Evaluate → Optimize prompts → Re-test. Zero glue code, zero tool sprawl
→ Optimization Studio - iterate on prompts and models with real eval data backing every change
→ Annotations & queues - let domain experts label edge cases, catch failures your evals miss
→ GitHub integration - prompt versions live in Git, linked directly to traces
Here's the wild part:
It's OpenTelemetry-native. Framework-agnostic. Works with LangChain, LangGraph, CrewAI, Vercel AI SDK, Mastra, Google ADK. Model-agnostic too OpenAI, Anthropic, Azure, AWS, Groq, Ollama.
Most teams shipping AI agents have zero regression testing. No simulations. No systematic eval loop.
They find out their agent broke when a user tweets about it.
LangWatch fixes that. One docker compose command to self-host.
Full MCP support for Claude Desktop. ISO 27001 certified.
100% Open Source.
(Link in the comments)
English
LangWatch retweetledi

Builder Hour: Token Factory — All Around Agents
Feb 18 · 18:00 CET / 9:00 AM PST
Join Nebius for a live session with:
- New @nebiustf models + UI updates
- @LangWatchAI on testing agents in prod
- Live demos with Claude Code
- Open builder Q&A
(Thread 1/2)

English
LangWatch retweetledi

Nebius Token Factory Builder Hour #2 is here.
🗓️ Feb 18, 2026 (Wed): 9am PST / 12:00 EST / 18:00 CET
Grab your favorite drink, bring your laptop, and join us for an interactive session where we connect, learn, and build together.
In this Builder Hour:
- What's new in Token Factory
- Partner chat with @_rchaves_ Co-Founder & CTO at @LangWatchAI - Live demo on how to test agents and models in pre-production and production
- Builder Chat: Using Open models with @claude_code (Live demo!)
All registrants will receive the recording, session notes, and credits.
👉 See you there: nebius.com/events/webinar…
@nebiusai @nebiustf

English
@openclaw took the AI world by storm last week 🦞
We ran a hackday at LangWatch and now have
Clawdbots living in our Slack boosting eng productivity by checking logs, errors, and reviewing PRs, all in our own infra.But… what is Clawdbot actually doing? Any risky business? 👀
We need observability.Until this weekend, OpenClaw had none. The OSS momentum has been 🔥On Sunday, @LangWatchAI @RedHat independently started adding OTEL to OpenClaw, then quickly teamed up to collaborate instead of competing. Goal: fully OTEL-instrumented OpenClaw, compliant with the OTEL GenAI spec. Work’s ongoing, but you can already use it today 👇
langwatch.ai/blog/instrumen…
English
Same eval power. Much more accessible. And everything finally connects.
Demo below 👇
youtube.com/watch?v=sNzctB…
YouTube
English
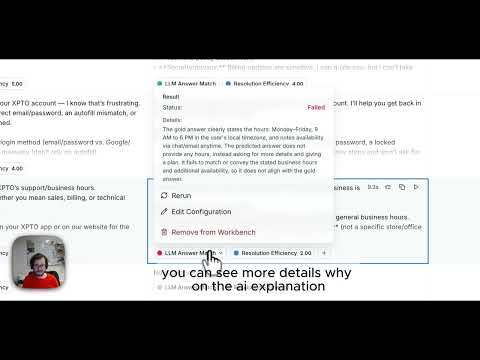
• Run experiments where your data lives, in a single spreadsheet-like workbench
• See inputs, outputs, expected answers, metrics, latency, and cost side-by-side
• Iterate faster on prompts and models and immediately compare results • Add evaluators in seconds (goldens, LLM judges, comparisons, policy checks)
• Understand the why, not just the score, with evaluator explanations
• One flow for PMs and engineers, UI + SDK, fully connected • Inspect real executions end-to-end by jumping straight into traces
• Compare runs over time and share results with stakeholders
English
Everything is coming together.
Proud to announce Evals & Experimentation V3 🚀
Evals and agent testing are still the hardest (and most important) part of building LLM apps.
But the real challenge isn’t running evals — it’s making them usable across the team.
With Evals & Experimentation V3, we focused on that:
English
Read our first and last of the year Monthly Drop in belows link!
Onto a very happy & succesfull 2026, so many exciting things coming up....👀
linkedin.com/pulse/december…
English
LLM evaluations work well for scoring individual outputs. But once you move to agentic systems multi-step reasoning, tool use, and evolving user intent they’re no longer enough.
In our next LangWatch webinar, Ron Kremer from ADC AI Consulting joins our CTO, Rogério Chaves, to explore how simulations and scenario-based evaluations make complex agent behavior measurable.
RSVP: luma.com/vevgrewo

English
LangWatch retweetledi

LangWatch Launch Week Day 5: Better Agents
Today we are officially releasing Better Agents, a CLI tool and a set of standards for building agents the right way.
No, it doesn’t replace your agent framework (Agno, Mastra, LangGraph, etc), it builds on top of them, to push your agent application to professional standards for your team, with agent testing, evaluations, versioned prompts and automatically instrumented.
The way it does it is by making your coding assistant (Cursor, Claude Code, Kilo Code, etc) an expert in both the framework your are using, in writing scenario tests to make sure every new feature is fully tested, and all other agent best practices we’ve seen adopted over the industry in the past 2 years.
Check it out 👇
English
LangWatch retweetledi
Launch Week Day 4 Scenario MCP
Most teams want to test their agents… but writing good tests takes time.
So testing gets skipped until something breaks. Today we’re fixing that. Scenario MCP now auto-writes agent tests inside your editor. In @cursor_ai (and other MCP editors) you can now:
- generate full tests automatically
- validate tool calls + reasoning
- catch regressions early
iterate without leaving your flow. We already made testing agents possible, now it’s effortless.
Docs in comments.
🚀 #launchweek #mcp #aiagents #agentic #devtools

English
@_rchaves_ this is gonna bring #voiceaiagents to the next level! Let's go!
English
LangWatch retweetledi
LangWatch Launch Week Day 3: Testing Voice Agents with LangWatch Scenario in Real Time
Today’s launch won’t be a surprise for those who watched our last webinar, but here it is: Scenario can now test your realtime voice agent by using another real time user simulator voice agent to talk to it.
Essentially, we call your agent, to test different situations and making sure it’s delivering.
Voice agents are a different ballgame, while most voice agents are delivered with a middle layer of more traditional text LLMs (fetching the context, doing RAG etc), there are some challenges specifically to voice which you need to nail if you want your voice agent to succeed:
- Audio quality: user still have a big variety of bad microphones or breaking connections, can your agent ask the user to repeat when key things are missing, or will it hallucinate pretending it understood?
- Interruptions: how does your agent handle interruptions? Is your agent being interrupted too much? Maybe it means it’s overtalking or not doing what the user expects
- Latency: the key thing for voice agents, can it handle scenario A or B in less than 3 seconds?
Now you can test those voice-specific situations end-to-end with Scenario, and listen in the simulated conversation as it happens.
Check out the demo video below 👇
English
Launch Week Day 3 🎤
Voice models made huge leaps this year. But one thing was still missing: a way to test real voice agents automatically, not manually. Today we shipped it. Scenario now supports end-to-end testing for OpenAI Realtime voice agents, real audio, real timing, real behavior. No mocks. No headphones. No guesswork. It passed alpha. Ready for teams.
Blog in the comments
DM if you to learn more!
English
LangWatch retweetledi
LangWatch Launch Week Day 2: RBAC Custom Roles & Permissions
It takes a village to raise an AI Agent to production. You need the AI devs building the agents, the domain experts annotating and validating its quality, the product manager defining the scenarios the agent should follow to deliver its goals, and business measuring the ROI metrics that makes the agent successful.
So, as several enterprises adopt LangWatch and the amount of collaboration increases, a great fine grained control of who-can-see-what and who-can-do-what becomes ever more necessary.
We are glad to announce now this deep access control now for different roles that different people can have in different teams across different organizations on LangWatch.
English