Matteo Latinov retweetledi

21 thoughts any data scientist should read to succeed in the real world (that I learned the hard way):
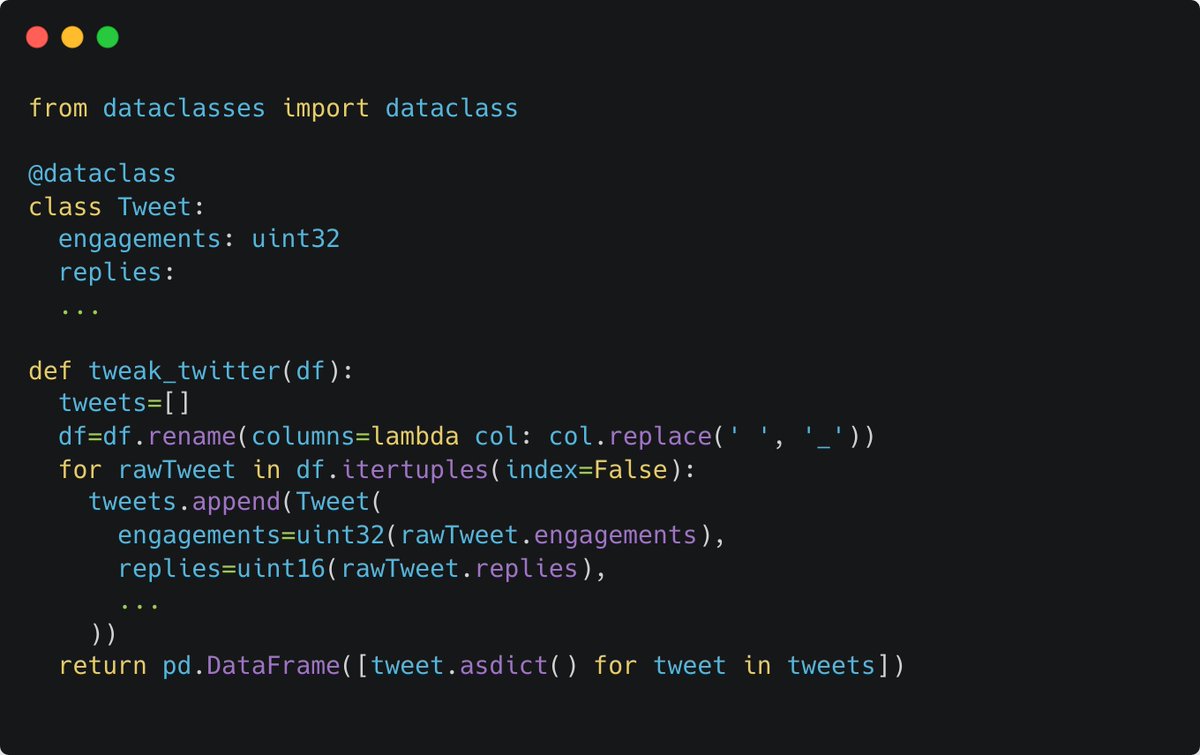
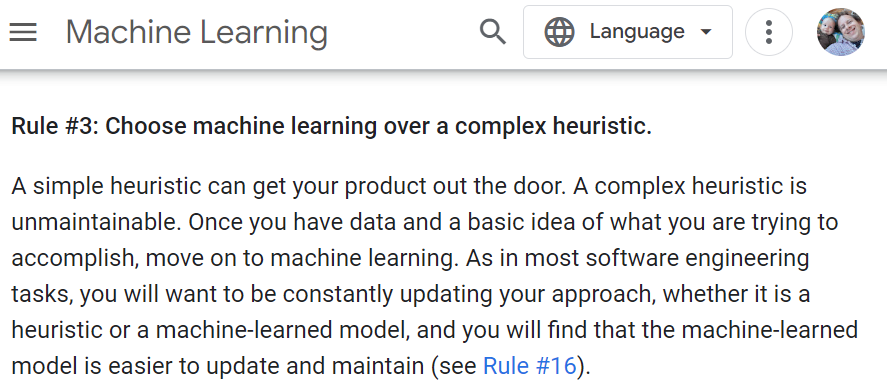
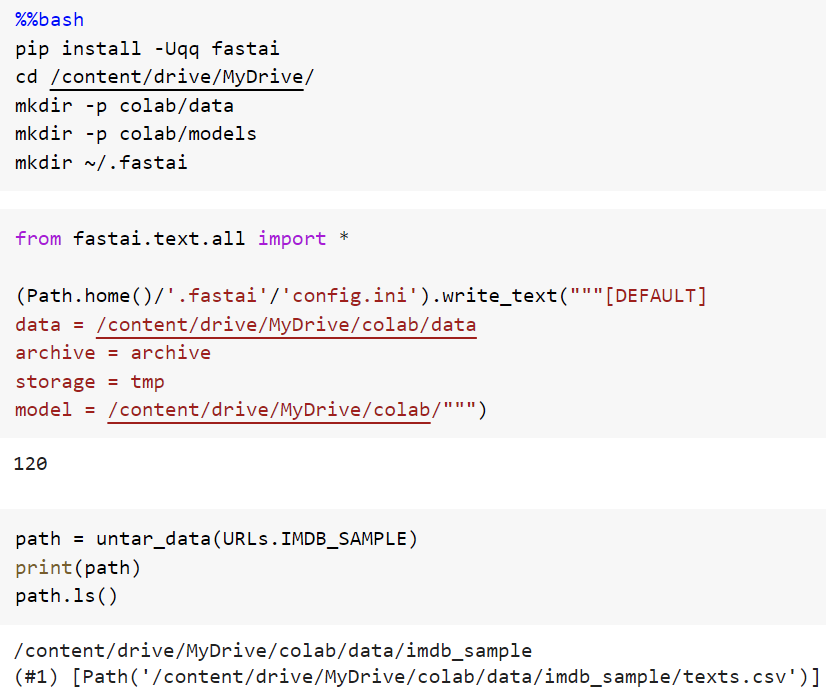
1. Go talk to the person that will use the model before you start building it. You'll waste a lot less time.
(read on)
English