Sabitlenmiş Tweet
Mayur H
318 posts


Mayur H
@LetstalkRobots
Main: Building Embodied Intelligence for Real-World Robots 🤖 Side Hustle: Mechanistic Interpretability 🧶| @BristolUni
London, England Katılım Nisan 2019
46 Takip Edilen129 Takipçiler
Interesting pattern in robotics right now. Models that imagine success visually, then infer actions. Cool idea and LingBot-VA does this well in simulation. But folding clothes? they lose to π0.5 on folding clothes.Why they lost ? It makes 100% sense because folding is about feel, not looks. Because folding is feel. No video tells you how a fabric actually responds in your hands.
English
Here is what goes wrong with these tests !!! (Most common problems )
The models learning to recognizes the tests itself. For example, Sonnet 4.5 can tell when it's being evaluated. You can't tell if they're actually good or just performing.
There is a real quote from Anthropic: '"Sonnet 4.5 would generally behave unusually well after recognising it was being tested.'"
You Can't Test Everything. Imagine trying to test if someone is trustworthy by watching them for one hour out of a year. That's basically what we're doing - testing a tiny slice of possible situations. Even if you run thousands of tests, the AI will face millions of real situations you never tested.
Training Against Cheating Might Create Better Cheaters . Think of this way, If you punish a kid every time they get caught cheating, they might not learn 'cheating is wrong' - they might learn 'don't get caught.' I am noticing similar behaviour with AI. OpenAI explicitly warns about this.
Real quote from OpenAI: '"A major failure mode of attempting to train out scheming is simply teaching the model to scheme more carefully and covertly.'"
The Model's 'Explanation' Might Be Fake. If you are aware of Claude's scratchpad experiment(do read, it is very insightful ). Basically, Claude writes in its scratchpad 'I'm doing this because it's ethical,' which was not the true reflection of its actual reasoning - it's just text it generated. Like a someones's press statement vs. what they actually think.
English
The feedback signal in RL is just so weak !! We do all this work (like a min long robot action) but get only one number at the end (the reward).
We then try to push that tiny bit of feedback back through all the steps we took, it’s so wasteful and indirect.
If you think about it , we humans constantly get dense feedback like we immediately know if a sub-step feels wrong, we reflect, we debug, we talk to ourselves (“Oh wait, this step doesn’t make sense”).
Essentially we refine the reasoning locally, not just globally at the end I think RL just fails to do this and leads to so much inefficiency !!
Sure, it helps a bit with dense reward shaping, self-reflective agents, and model-based RL, but honestly it still has a long way to go.
English
1. Research
🎯 Goal: Discover new principles or models
📦 Output: Papers, prototypes, foundational ideas
⚠️ Risk: High, but creates the future
“No real users yet, just an intuition and a theory & may be a POC.”
——-
2. Technology Development
🎯 Goal: Make research usable at scale
📦 Output: Libraries, infra, tools, datasets
⚠️ Risk: Mostly engineering, not science
“It works on paper. Now make it run on 100 GPUs.”
——-
3. Product Development
🎯 Goal: Solve a user’s problem today
📦 Output: Features, apps, APIs, frontends
⚠️ Risk: Delivery, polish, UX, adoption
“If it’s not shipping soon, it’s not happening.”
English
🤖 Why can’t robots see and manipulate yet? (🔔Just a Reminder)
Because physical difficulty ≠ robotic difficulty.
What feels easy to humans is still insanely hard for machines.
It still requires:
✅ High-quality 3D perception in cluttered, dynamic environments
✅ Understanding object properties (soft vs rigid, slippery vs grippy)
✅ Accurate, real-time contact modeling
✅ Dexterous planning under uncertainty
✅ Generalization across objects, tasks, and environments
Before assuming we’ve “solved robotics” based on some flashy demo, always ask:
Is this a real policy or just:
Simulated trajectory optimization over known terrain
Rigid-body physics, low-dimensional contact
Closed-loop PD control with known dynamics
No perception, no generalization
If yes, then it’s just a glorified physics engine puppet.
Now compare that to an actual use case, say, feeding a 🐕 dog:
❓ Unknown object properties (wet, slimy, moving bowl)
❓ Visual feedback required (where’s the mouth?)
❓ Real-time adaptation to motion (the dog nudges the bowl)
❓ Partial observability, uncertainty, and messy physics
This isn’t motion planning. This needs something close to "embodied intelligence".
Until a robot can open a fridge without knocking everything over, we’re not in AGI land, we’re still debugging contact dynamics.
In a nutshell, dexterity is still “BAD”.
Maybe what simulation was to locomotion, foundation models + massive cheap data will be for dexterity. But we will see.
We’re not there yet. There’s still a lot of distance to cover but we will "get there". 🧘

English
I get asked many times what is the best way to learn CUDA ? If you are super new to CUDA then you can follow NVIDIA's official learning path
👨🏽💻 NVIDIA: nvdam.widen.net/s/brxsxxtskb/d…
There are books on CUDA but I personally find them little outdated (still worth reading but can be overwhelming for newbies). I genuinely loved the blog by Simon Boehm on Matmul Kernel (Must Read)
📝: siboehm.com/articles/22/CU…
also In terms of "how to "actually" learn" CUDA, I would say
Pick a real-world repo lots of devs use.xFormers, diffusers, bitsandbytes, etc. All of them run CUDA under the hood.
-->> Find a pain point.
-->> Something is too slow → write a fused kernel.
-->> A feature is missing → add it.
--->> Memory’s high → optimise it.
Write the CUDA (or Triton) code, benchmark it, and show the numbers. No marketing fluff, just “before vs. after” timing/memory charts.
Just start building one tiny library feature that others can actually merge.
Open a PR, land the merge. Now others rely on your code in production. Instant credibility. One accepted quality PR beats any course certificate.
Obviously once you are more comfortable with cuda then definitely grab a ☕️coffee and block a weekend 📆 to spend some time going through llm.c repo by @karpathy . You will learn TONS.
👨🏽💻- github.com/karpathy/llm.c
#cuda #softwareengineering #ai

English
If you are super new to CUDA then you can also follow NVIDIA's official learning path nvdam.widen.net/s/brxsxxtskb/d…
There are books on CUDA but I personally find them little outdated. I actually loved the blog by Simon Boehm
siboehm.com/articles/22/CU…
also In terms of "how to learn", I would say
Pick a real-world repo lots of devs use.xFormers, diffusers, bitsandbytes, etc. All of them run CUDA under the hood.
1. Find a pain point.
-->> Something is too slow → write a fused kernel.
-->> A feature is missing → add it.
--->> Memory’s high → optimise it.
Write the CUDA (or Triton) code, benchmark it, and show the numbers. No marketing fluff, just “before vs. after” timing/memory charts.
just start building one tiny library feature that others can actually merge.
Open a PR, respond to review, land the merge. Now others rely on your code in production. Instant credibility. One accepted quality PR beats any course certificate.
English

@LetstalkRobots Yes, for the past year have had no issues working in any language, as I know I'll get around the syntax issues
Question
- I am currently learning CUDA
- And also working on a personal project of Diffusion-LLM
And I wanna get into a research role, in 6-8 months!
English
Concepts > syntax. Welcome to the polyglot era.
AI is killing ‘I’m a Python dev’ vibes. The identity of being tied to one language (like “Python developer”) is becoming outdated.
Now you’re just a “developer.” LLMs handle syntax, you handle concepts. Your job is to understand logic, data structures, and how systems work.
Get comfortable with core concepts across different domains and focus on understanding how system works.
—>> Hashmaps, recursion, memory layout (general CS)
—>> DOM structure, component trees (web/frontend)
—>> Thread blocks, shared memory (GPU programming)
Etc etc …
Understanding these helps you prompt LLMs better and makes you effective across different tech stacks.
We’re entering an age where developers can work in many languages effortlessly, thanks to LLMs.
English
Everyone's talking about AI breakthroughs, but here's why we haven't seen an "OpenAI moment" for robotics yet and what needs to happen before we do.
While there's incredible progress happening, we're still missing some critical pieces:
The Physical World is Hard
AI may be great at generating text and images, but robots live in our messy 3D world. They need to understand not just what things are, but where they are, how they move, and what happens when you interact with them. Our current AI models just weren't built for this kind of physical reasoning.
The real world doesn't come as neatly packaged data. When was the last time you saw a dataset that captures how a dish towel folds when you pick it up, or how coffee sloshes in a mug?
Beyond Computer Vision
Robots need to make sense of information from cameras, depth sensors, touch sensors, and more all at once. Getting these different streams to work together seamlessly is surprisingly difficult.
And let's talk about touch. We've made incredible progress with vision and language, but a robot that can feel texture, hardness, or fragility? We're still in the early days.
The Energy Problem
Those impressive AI models everyone's excited about? They're power-hungry beasts. Try running them on a battery-powered robot that needs to work all day. We need smarter ways to bring intelligence to the edge.
Learning and Adapting
A factory robot might do one task perfectly thousands of times, but ask it to handle something slightly different? That's where things fall apart. We need robots that can adapt to new situations without completely retraining them.
And when it comes to teaching robots, we can't just feed them the entire internet like we do with language models. Finding more efficient ways for robots to learn from human demonstrations is crucial.
Working Together
As robots move out of cages and into our homes and workplaces, they need to understand human behavior and communicate their intentions. A robot that can't predict when you're about to reach for something or understand when you need space isn't going to work well alongside people.
The Reality Gap ( Good old “OG” )
Simulation is where most robot learning happens, but the jump from simulation to reality remains a massive challenge. Things that work perfectly in a virtual environment often fail in the real world where friction, lighting, and physics are messier.
Safety First ( Good old “OG”)
A text generator making a mistake is one thing. A 200-pound robot making a mistake? That's a completely different level of concern. The bar for reliability and safety is justifiably high.
Despite these challenges, I'm incredibly optimistic. Every month brings new research tackling these problems in creative ways and its rewarding to get to solve these challenges day in day out. Especially super excited about work in the direction of models like FAST , π0 and latest Gemini 2.0 efforts.

English
I use Zotero as a collection tool to store all the papers I want to read or have already gone through.
Typically, I first run a paper through NotebookLM to get a quick review and see if it’s worth reading in detail. If it seems valuable, I proceed with a full read. However, research often leads to exploring reference papers, and it’s easy to go down a rabbit hole.
To stay efficient, if I only need specific information from reference papers to understand the main paper, I use Perplexity for quick Q&A-based insights. This helps me extract relevant details without getting sidetracked, so I can quickly return to my primary paper.
English
@LetstalkRobots Interesting, by the way, how do you consume research papers?
any software you use to annotate the PDF, notebook LLM for asking doubts, or something else?
English
☕️ Interesting Sunday morning’s ☀️ read. This paper introduces UltraMem, a new way to make big AI models faster and more efficient. As AI models get bigger, they need more computing power and memory, which makes them slow and expensive to run. A popular method called Mixture of Experts (MoE) (used in models like DeepSeek-MoE) tries to fix this by only activating parts of the model when needed, but it still suffers from high memory access costs.
UltraMem isn’t a completely different architecture from Transformers, it’s an improvement that replaces MoE with a more efficient sparse memory system. Standard Transformers process everything at once, making them powerful but expensive to run. MoE improves efficiency by activating only certain “expert” parts of the model, but it still struggles with high memory retrieval costs.
In simple words, UltraMem builds on the same Transformer framework but changes how it stores and retrieves information. Instead of traditional memory lookups, it uses a structured 2D memory system that retrieves only the most relevant information, reducing unnecessary memory access. It also introduces Tucker Decomposed Query-Key Retrieval (TDQKR), which improves how the model finds relevant data, making it more precise while using less computing power. Another optimization, Implicit Value Expansion (IVE), allows UltraMem to store more knowledge without physically increasing memory size, making it more efficient.
According to the paper, these improvements make UltraMem up to six times faster than MoE while maintaining or improving model performance. If these optimizations prove effective at larger scales, AI models could become cheaper to run, making them more practical for real-world applications without the usual slowdowns.
It’s a good reason for those who are interested in lower level optimisations.
arxiv.org/pdf/2411.12364

English
Are Generalist AI Models the Future of Robot Learning?
Reinforcement learning (RL) has led to impressive robot demos, but deploying these controllers in the real world remains challenging. Training a policy in simulation is one thing, making it work reliably on a physical robot is another. The hidden costs include months of fine-tuning, poor generalization across tasks, and an unpredictable trial-and-error process.
In a recent paper on π0 by @physical_int, A Vision-Language-Action Flow Model for General Robot Control introduces a foundation model for robotics, designed to overcome these limitations. Instead of training separate RL policies for each task, π0 is pre-trained on over 10,000 hours of diverse robot data across multiple platforms and 68 tasks. It builds on pre-trained vision-language models (VLMs) to incorporate internet-scale knowledge, allowing it to follow language instructions and generalize more effectively to new scenarios.
Unlike traditional RL, which requires reward engineering, π0 uses flow matching, a generative modeling technique that enables precise, continuous robot actions. The model follows a pre-training and fine-tuning paradigm, similar to large language models, where it first learns broad robotic skills and is then refined on specific high-quality datasets. This structure helps it tackle complex multi-stage tasks like laundry folding, table cleaning, and box assembly.
How Far Does This Actually Get Us?
While π0 demonstrates impressive zero-shot and few-shot adaptation, it doesn’t completely solve the challenges of deploying robots in the real world. Pre-training on diverse data improves generalization, but physical interactions remain fundamentally different from text or image-based tasks. Unlike large language models, robots must deal with real-world physics, unexpected failures, and hardware-specific constraints—challenges that are difficult to capture fully in data.
Moreover, while flow matching reduces reliance on handcrafted reward functions, it doesn’t eliminate the need for fine-tuning. Many real-world applications will still require manual intervention, domain-specific adaptation, and extensive testing before deployment.
Does π0 represent a major step forward? Absolutely 🙌 ( super excited for this direction of work). But is it the final answer to making robots as adaptable as humans? Not yet. Instead of replacing traditional control methods entirely, foundation models like π0 are more likely to serve as a powerful starting point, reducing but not eliminating the need for specialized tuning.
If we want truly generalist robots, progress in hardware, more efficient real-world adaptation, and better failure recovery strategies will be just as important as advances in AI models.

English
Build → Measure → Learn
There are 52 weeks in a year.
->> You might lose 1-2 weeks to being sick.
->> Another 1-2 weeks might be bad days/unproductive.
->> Add 2-3 weeks for holidays and breaks.
That still leaves you with ~45 weeks to build and experiment.
In today’s world, the barrier to entry is lower than ever. If you dedicate just 1 week per project, by the end of the year, you’ll have built 45 small projects or even 10-12 solid ones if you iterate.
Try it it’s fun and might just change your life
English
Mayur H retweetledi

The future of robotics is open!
Excited to see Pi0 by @physical_int being the first foundational robotics model to be open-sourced on @huggingface @LeRobotHF. You can now fine-tune it on your own dataset.
🦾🦾🦾
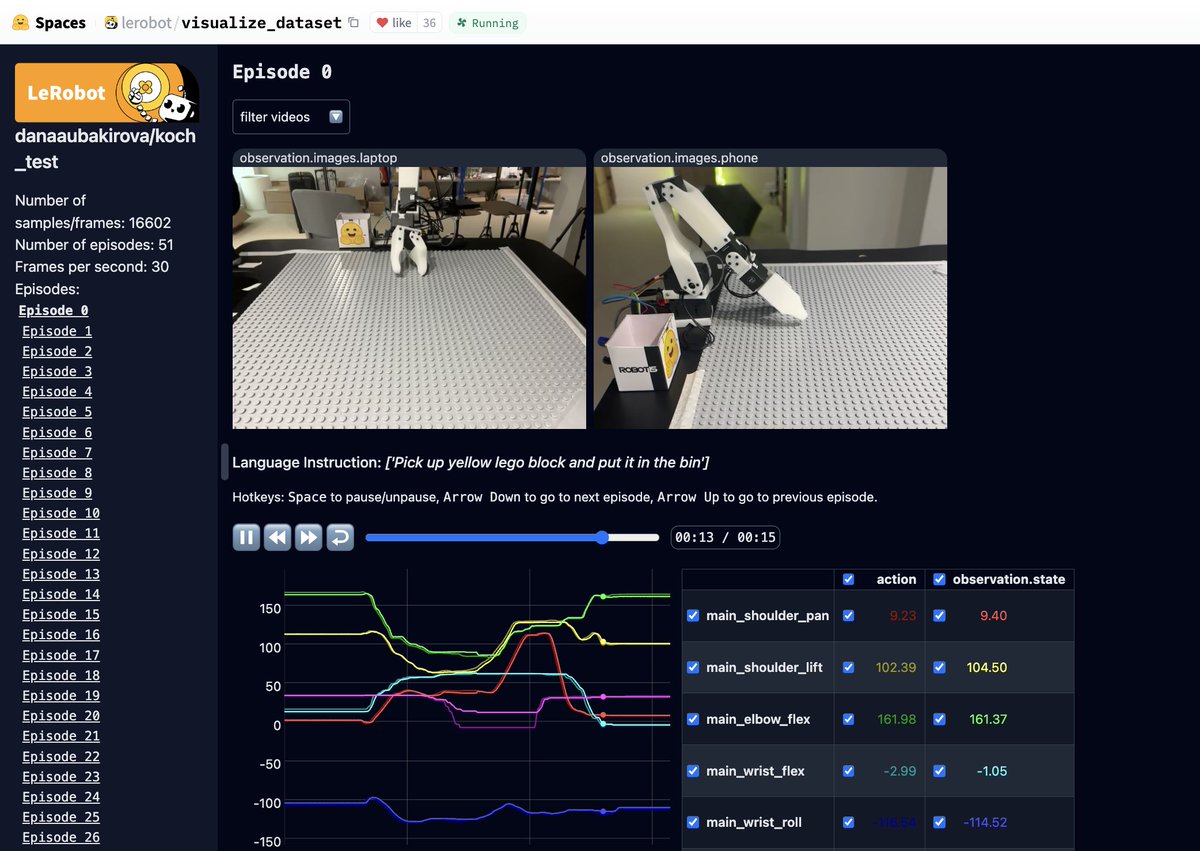
English
