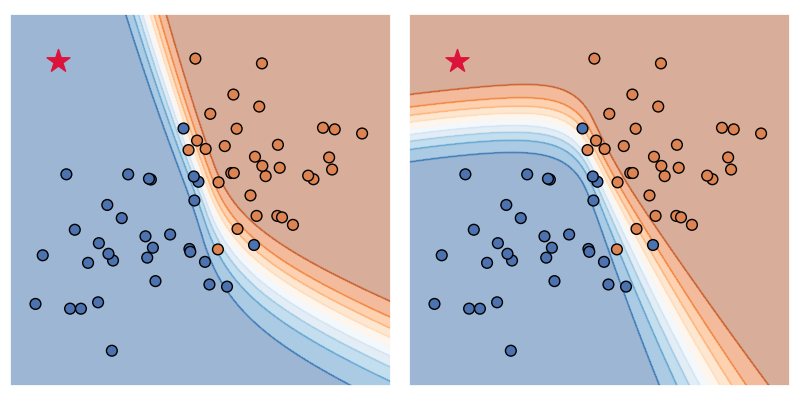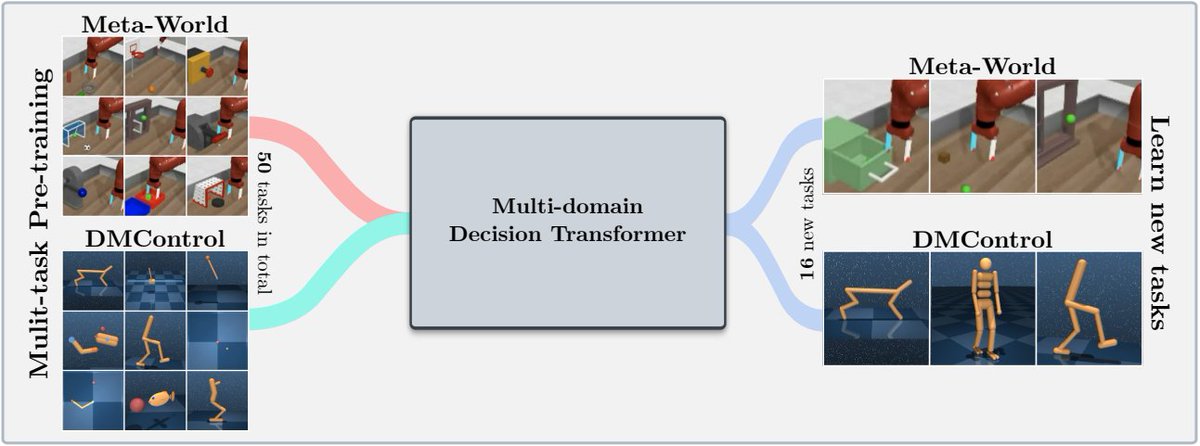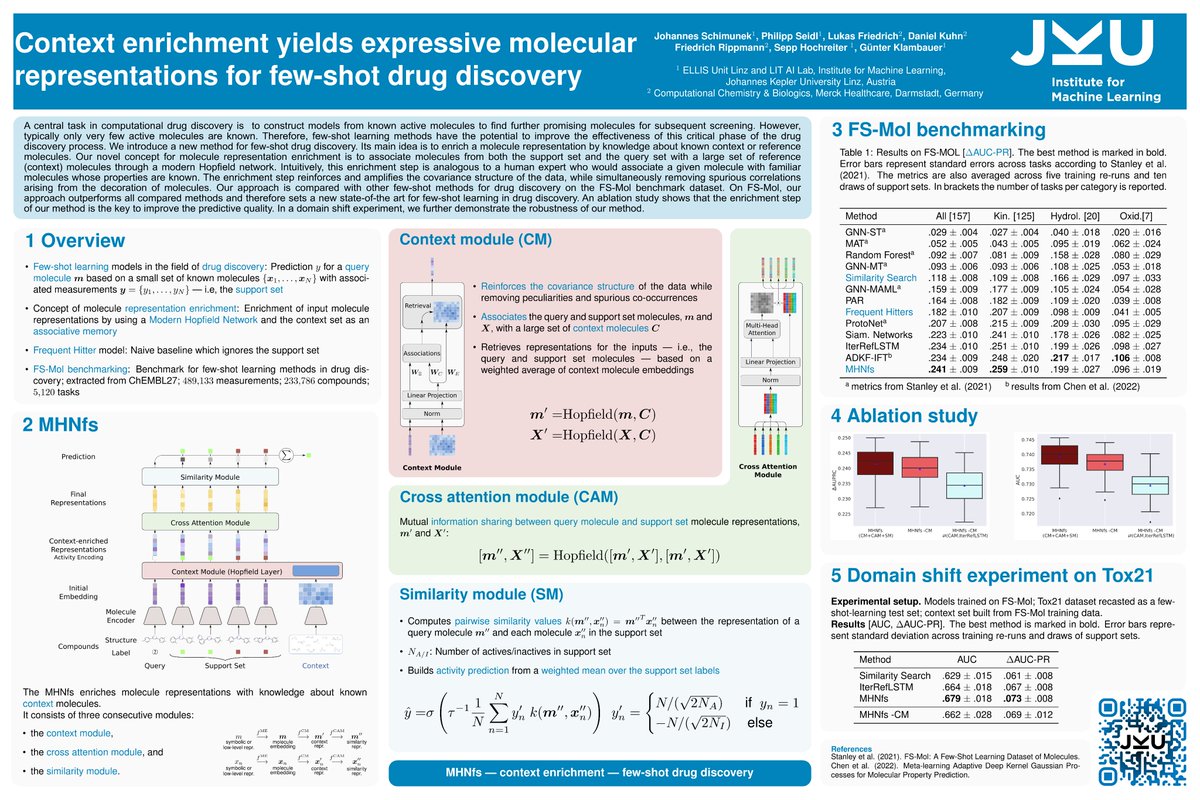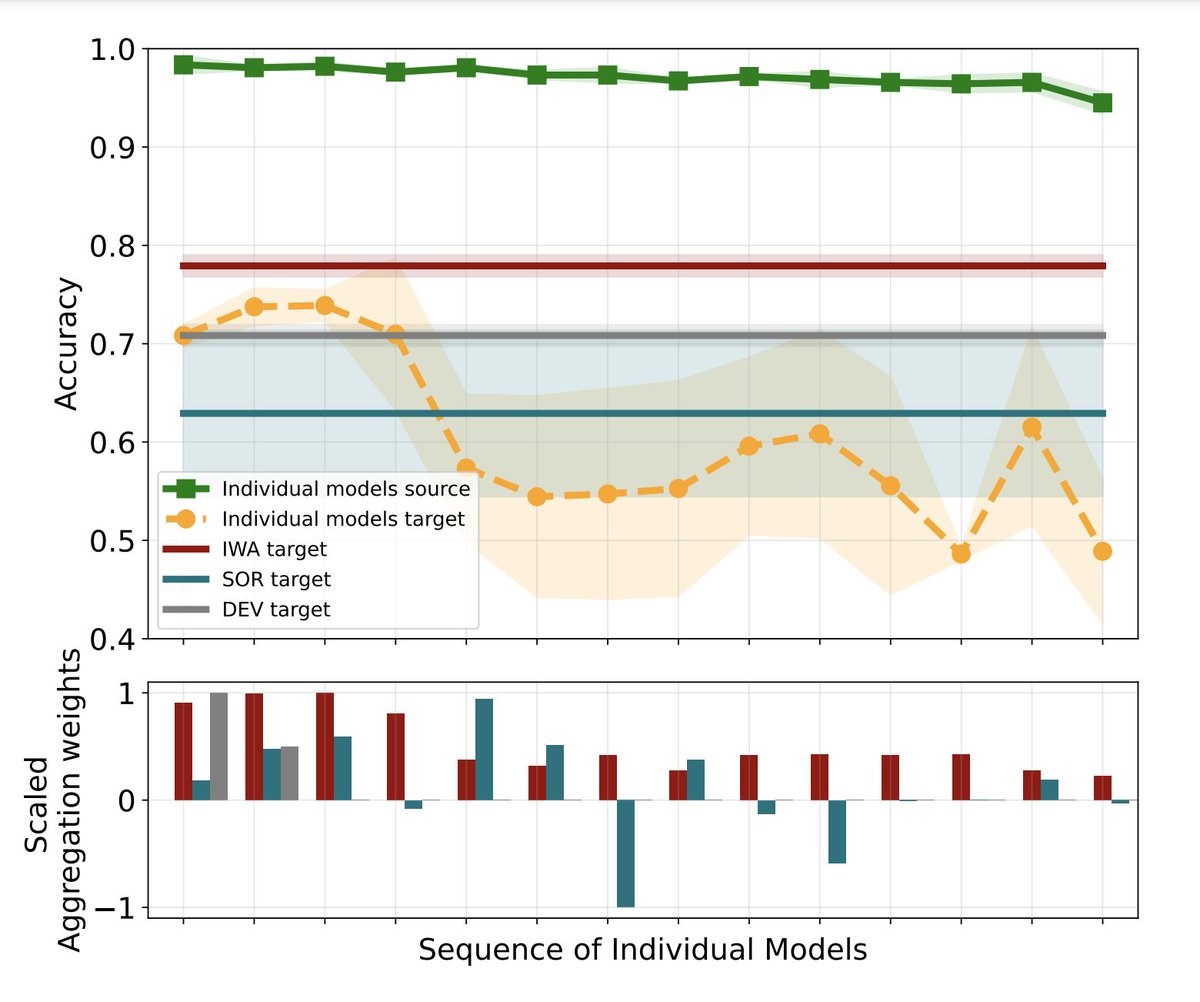

Elisabeth Rumetshofer retweetledi

I am so excited that xLSTM is out. LSTM is close to my heart - for more than 30 years now. With xLSTM we close the gap to existing state-of-the-art LLMs. With NXAI we have started to build our own European LLMs. I am very proud of my team. arxiv.org/abs/2405.04517
English