Sabitlenmiş Tweet

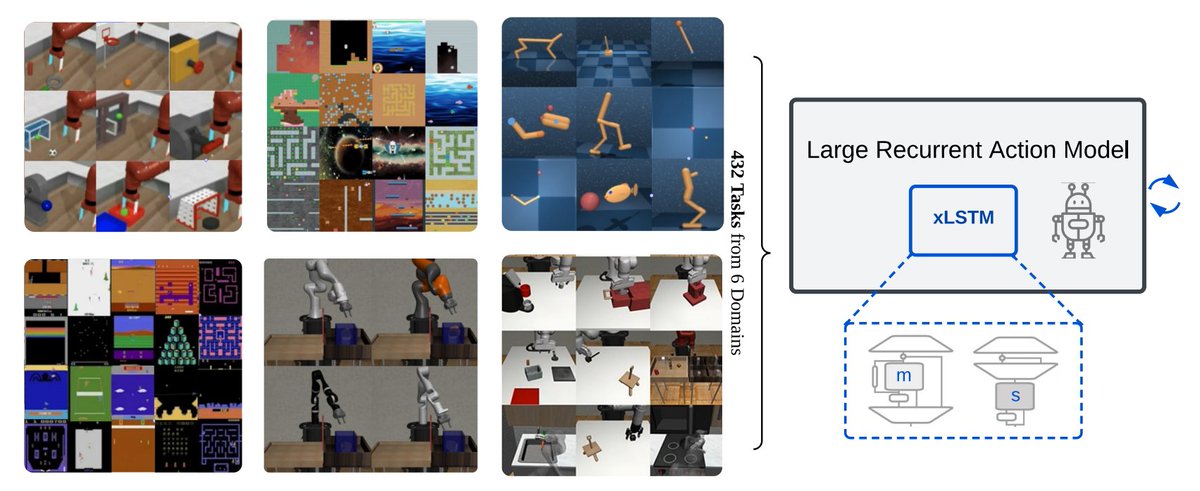
Transformers can be slow for real-time applications like robotics. We study if modern recurrent architectures, like xLSTM and Mamba, can be faster alternatives. Experiments on 432 tasks show that they compare favourably in terms of performance and speed 🎃 arxiv.org/abs/2410.22391
English