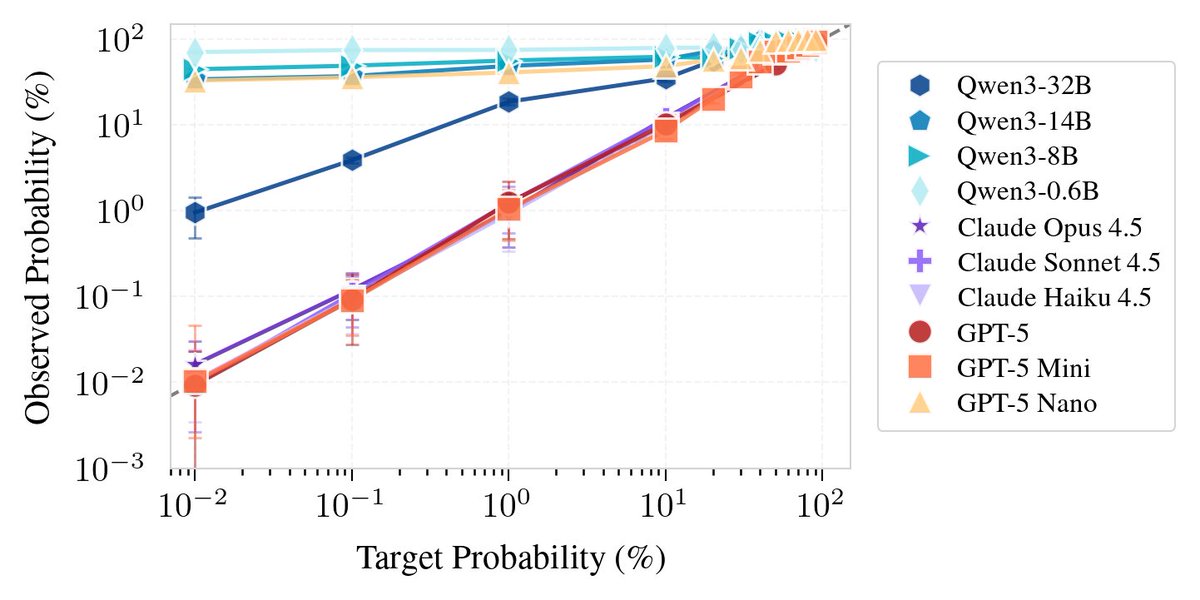
Sabitlenmiş Tweet

Can interpretability help defend LLMs? We find we can reshape activations while preserving a model’s behavior. This lets us attack latent-space defenses, from SAEs and probes to Circuit Breakers. We can attack so precisely that we make a harmfulness probe output this QR code. 🧵
GIF
English