Marco Smith retweetledi

We are entering a new era of on-device automation. ✨
Watch Gemma 4 E4B navigate and drive an iOS simulator directly using Argent. Local models can handle complex interactions and software navigation autonomously.
English
Marco Smith
2.2K posts



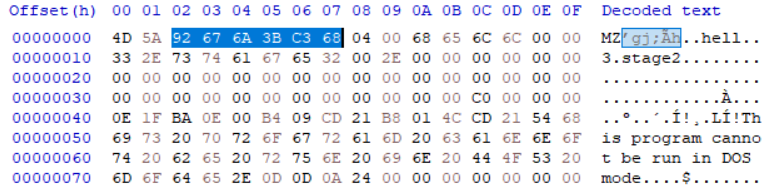
MTP speedup Qwen by 2.5x in Atomic Chat Dense vs MoE models on 2x RTX 5090 Qwen3.6 27B: 51 → 117 tps +137% Qwen3.6 35B-A3B: 218 → 267 tps +25% MTP drafts several tokens ahead and verifies them in one pass. The speedup depends on memory moved per pass. Dense 27B reads all 27B params per token, MoE 35B-A3B only reads 3B active. Dense had way more to save by batching. The baseline tps also differ (218 vs 51) for the same reason from the other side. Token generation is memory-bandwidth bound, and MoE moves ~8x less memory per token, so its baseline is already 4x ahead. ~80% draft acceptance. Zero accuracy loss. ~1 GB extra VRAM. Open-source code and local AI app – in the comments 👇








if it still looks like a language for humans then it isn’t enough of a language for agents