Sabitlenmiş Tweet
Mansour
302 posts

Mansour
@Mansourdam
Product Manager-AI Native Products, ML
Amsterdam, The Netherlands Katılım Ekim 2010
1.8K Takip Edilen167 Takipçiler
@mweinbach @mweinbach Hey Max, are you sure these models were trained from scratch and are not distilled from Gemini?
English

Again, 4 of the 5 models Apple is shipping are fully from Apple, trained on latest gen TPU, with some Gemini responses as part of the dataset.
1 models is, I believe, a larger Gemini base model that was adapted to work better for Siri with further training
Awful comparison
Marques Brownlee@MKBHD
Apple is insisting that the new Siri is NOT Gemini youtu.be/N36yb-X1LN0?is…
English
@ValerioCapraro @ValerioCapraro Interesting one. Gemini 3.1 Pro gets it wrong at first, but then with the tip it got it. Interestingly, Fable failed even after the tip.

English

Claude Fable 5 doesn’t truly understand. And here is a beautiful proof:
The Beninatto-Trombetti test is a translation test for professional translators. It measures the ability to infer context, revise the surface form, and generalize beyond literal mapping.
For example, the correct translation of:
“Solo 3 parole: non sei solo”
is not:
“Just 3 words: you are not alone”
but:
“Just 4 words: you are not alone.”
An LLM that understands the sentence must also update the meta-linguistic claim inside the sentence.
Claude Fable 5 is arguably the most advanced LLM currently available. And yet it still fails this simple test.
LLMs are extraordinary machines for recombining existing knowledge. But they don’t truly understand.
We are still far from AGI.

English
@MParakhin @MParakhin I'm really surprised they haven't done this by now. PR reviews are such a pain right now, and I think a Pro/ Deep Think model would help to solve it.
English

Well, Tibo, for a year now I was pleading, arguing for, begging you guys to bring Pro as an advisor model into Codex (really, allow for the LARGE thinking budget)…
Tibo@thsottiaux
I would like to claim my 1% of royalty fees.
English
@GergelyOrosz @GergelyOrosz could you share some examples of these pushbacks ?!
English

I will be honest:
1. Since Opus 4.7 I get pushback in unexpected ways from Anthropic models
2. GPT-5.5 doesn't do this
When I know what I want to do, I prefer #2. I don't like a vendor knowing better what I do, how I do it, with zero transparency. I humor Opus but like GPT...
Dylan Patel@dylan522p
Usage share of OpenAI grew vs Anthropic yesterday despite Mythos 5 / Fable 5 launch Multiple power users at SemiAnalysis tried Mythos / Fable Got refusals for nonsensical reasons Got pissed off at Anthropic Gave Codex a legitimate try Now they actually prefer it to 4.8 Opus
English
@mweinbach Yeah, its a great ux. Our bet though is multimodal logging, voice-first since it's the lowest-friction way to capture detail, with strong memory handling that personalizes the app over time.
English
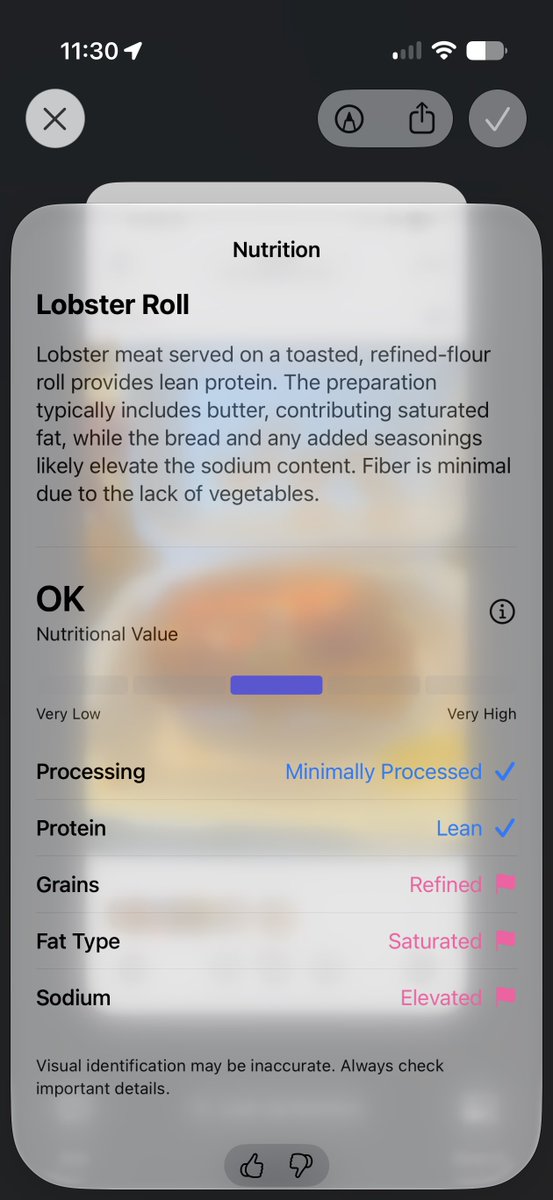
I really like how Apple does nutrition information
Rather than telling you calories and what not, it just tells you if it’s bad, OK, good, or great.
English
@AiBattle_ It's not a good benchmark , Sonnet 4.6 scores higher than Opus 4.6 lol, and there is absolutely no way 3.5 Flash outperforms Opus 4.6.
English


If the claude Mythos rumors are true,that it uses a recurrent-depth/looped transformer with a shared block iterated for latent reasoning,Sakana DiffusionBlocks is directly relevant: it reframes those iterations as diffusion denoising steps, enabling single-pass training instead of K-step BPTT.
hardmaru@hardmaru
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall. We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal. This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (arxiv.org/abs/2506.14202), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
English
@badlogicgames Smaller models like Kokoro-82M are already working surprisingly well for TTS
Check this out: github.com/cyanxxy/offlin…
English

jesus, qwen3-tts is FANTASTIC. going for full local stt/tts/llm with parakeet, qwen3-tts, and gemma 4 via llama.cpp for my little robot. excite, excite!
huggingface.co/Qwen/Qwen3-TTS…
English


Almost every SaaS app inside Vercel has now been replaced with a generated app or agent interface, deployed on Vercel.
Support, sales, marketing, PM, HR, dataviz, even design and video workflows. It’s shocking.
The SaaSpocalypse is both understated and overstated. Over because the key systems of record and storage are still there (Salesforce, Snowflake, etc.)
Understated because the software we are generating is more beautiful, personalized, and crucially, fits our business problems better.
We struggled for years to represent the health of a Vercel customer properly inside Salesforce. Too much data (trillions of consumption data points), the ontology of Vercel was a mismatch to the built-in assumptions, and the resulting UI was bizarre. We generated what we needed instead. When you don’t need a UI, you just ask an agent with natural language.
We’ve also been moving off legacy systems with poor, slow, outdated, and inconsistent APIs, as well as just dropping abstraction down to more traditional databases. UI is a function 𝑓 of data (always has been), and that 𝑓 is increasingly becoming the LLM.
English
Mansour retweetledi

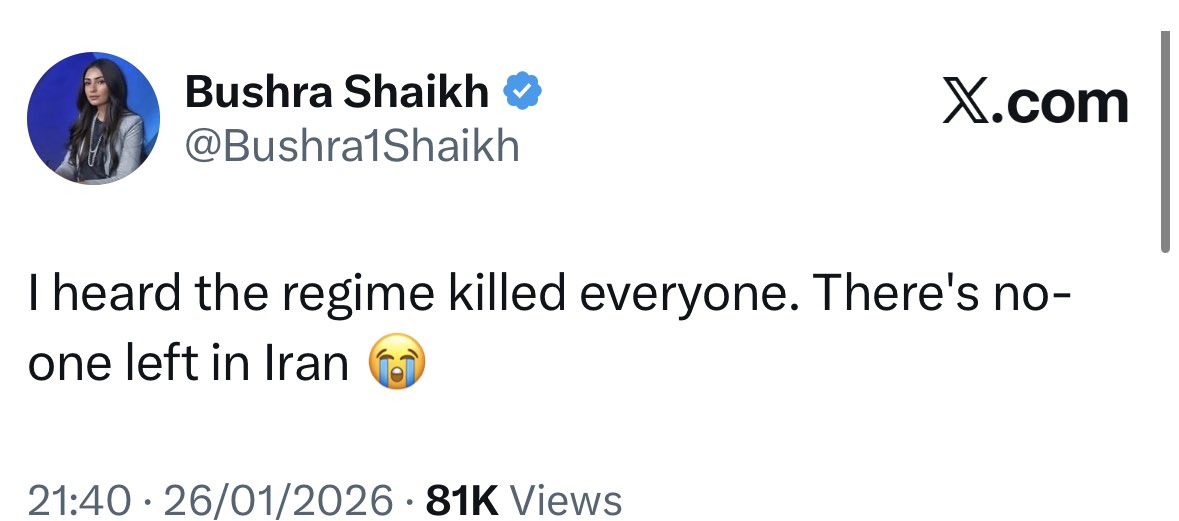
This person runs an "anti racism" organisation in the UK
I kid you not
English
Mansour retweetledi

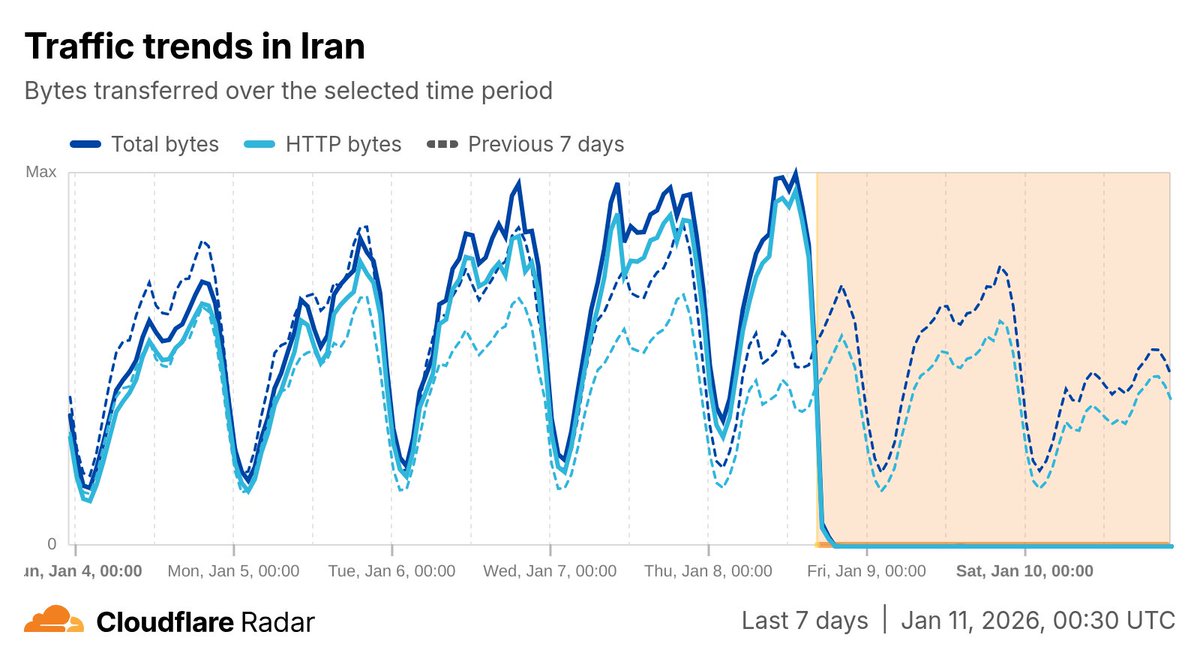
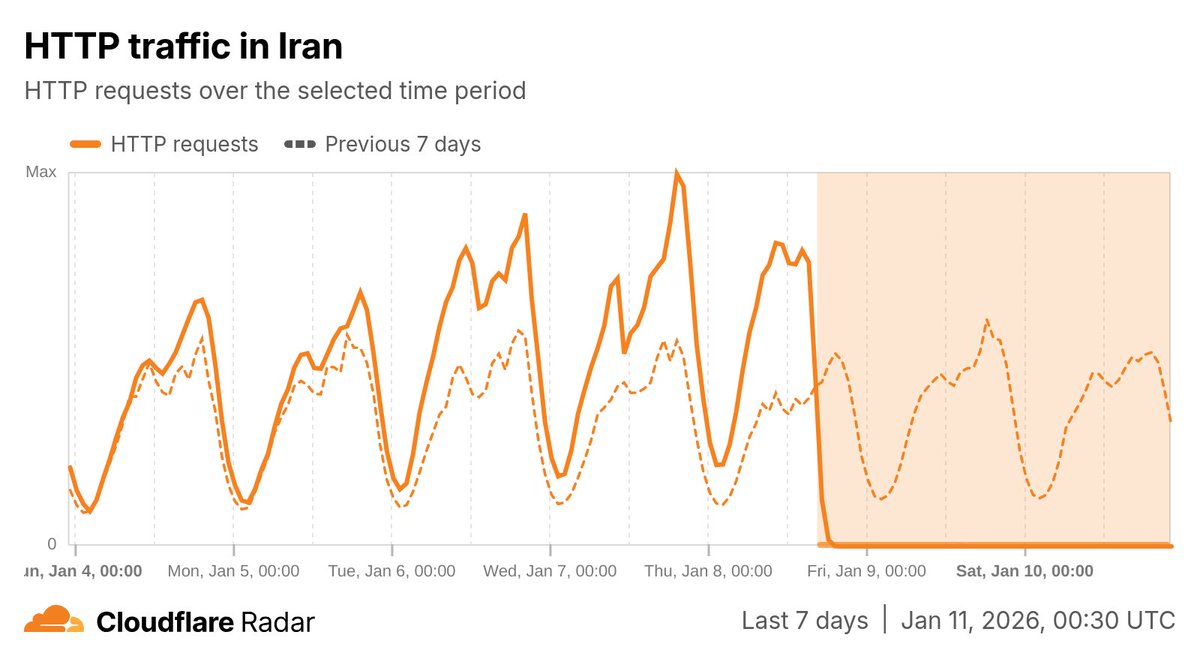
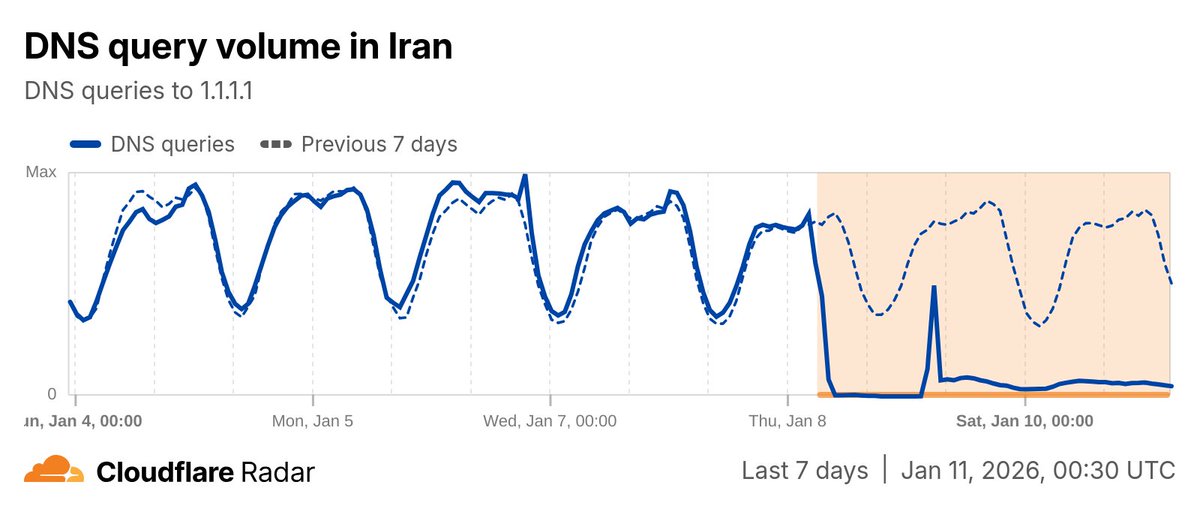
Iran's Internet shutdown is now in its third day. Traffic volumes remain extremely low.
Follow the latest status at radar.cloudflare.com/traffic/ir
#IranProtests2026 #IranDigitalBlackout

English
@raizamrtn Exactly,There are many frontend issues; streaming, for instance, is buggy and triggers multiple re-renders. It makes me wonder if anyone is actually QAing this or gathering feedback.
English

I’m sorry to say this but most of what stops me from switching from the ChatGPT app to Gemini (today) is literally front end and I know googlers will do *anything* but front end eng work!!
English
@fleetingbits The recent paper was from Google Research, not DeepMind.
English

When DeepMind publishes research, you can be sure that it is either Nobel Prize worthy or something DeepMind never intends to use in production - no middle ground.
English

I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...
vLLM@vllm_project
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×. 📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens. 🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale. 🔗 github.com/deepseek-ai/De… #vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning
English