
ben
67 posts


So I have an impersonator. This is not my instragram account. he is pretending to be me, ripping off my youtube short content and reposting to IG.

English

Kimi K2.7 Code HighSpeed is now in Command Code! 🌘
it's incredibly fast, up to 6x faster 180-260 tok/s.
available in $1 Go plan with 10x credits and above!!
a high-speed mode of open-source multimodal coding model, Kimi K2.7 Code.
$ npm i -g command-code@latest

English


Baru nemu LLM provider yang menurut gue cukup menarik.
Blueminds lagi ngasih credit $100 untuk user baru, dan proses daftarnya bahkan nggak sampai 1 menit. Tinggal connect akun GitHub, langsung dapat akses.
Yang bikin menarik bukan cuma credit gratisnya, tapi pilihan modelnya juga banyak. Ada sekitar 49 model yang bisa dipakai, termasuk GPT-5.5, Qwen 3.6 Max, dan model-model lainnya.
Buat yang lagi bikin AI Agent, chatbot, automation, atau sekadar eksplorasi berbagai model AI dalam satu dashboard, ini lumayan worth untuk dicoba.
api.bluesminds.com/console/token
Kalau ada yang sudah pakai Blueminds, share dong pengalaman kalian sejauh ini.


Indonesia

GPT 5.6 drops as soon as next week.
Insiders say it competes with Claude Fable 5 at a fraction of the price.
If true, this changes everything.
Fable 5 is the best model in the world right now and people are burning through $200 Max plans in 30 minutes to use it.
A cheaper equal would break Anthropic's pricing overnight.
Next week is going to be insane.
English
@bridgemindai It's cheaper than 4.1 but it's getting removed our of the coding plan. Smells bad
English
Claude Fable 5 is CHEAPER than Claude Opus 4.1 was.
Don't forget this era of vibe coding.
I remember using Claude Opus 4.1 as my daily driver.
I am thankful that Anthropic isn't charging $25/$125 for Fable 5 which I was expecting.
Claude Fable 5 isn't so poorly priced after all!

English
Looks like the recent ChatGPT ban wave was accidental.
Some affected users are now getting emails from OpenAI saying it was caused by an error in their systems.
Also, some are getting 1 month of subscription for free as compensation.
If you were on Pro, make sure you check the promo link in the email.
Good to see OpenAI making it right.

OpenAI@OpenAI
An issue caused some user accounts to be incorrectly suspended. We’re restoring access and working through related subscription and credit issues. status.openai.com/incidents/ejj4…
English
NVIDIA Nemotron 3 Ultra now available in Command Code!
Strongest US open model yet! 🍀
• 1M context
• 5x faster inference
• 550B MoE frontier-intelligence open model
DEAL 2.3x usage 🎟️
$1 Go plan gets you ~$23 usage on Nemotron
Woah, it's fast x taste compliance is great!

English

MiniMax M3 scores above DeepSeek V4 Pro on DeepSWE, but below other chinese competitors

English





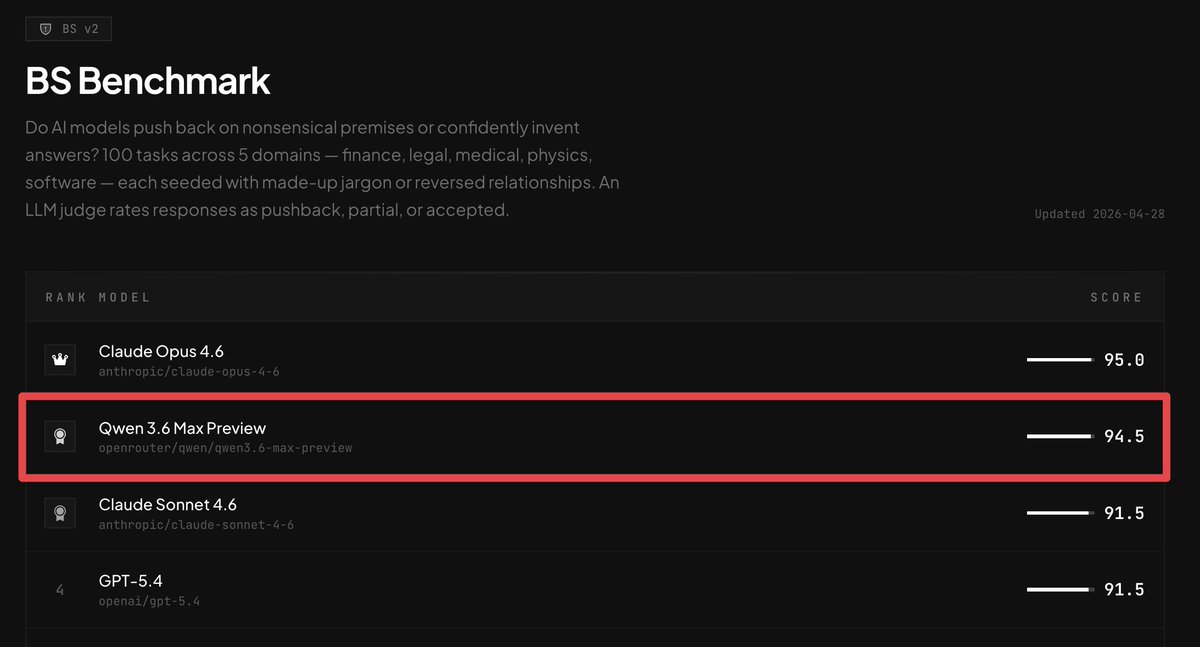
Qwen 3.6 Max Preview is the most honest open source model on the planet.
It just took #2 on BridgeBench's BS Benchmark.
Claude Opus 4.6: 95.0
Qwen 3.6 Max: 94.5
Claude Sonnet 4.6: 91.5
GPT-5.4: 91.5
A Chinese model pushes back on nonsense better than every OpenAI model.
English
@bridgemindai Just because it did well on your "benchmark" and sucked in your vibe coding shit, it does not mean it is mean benchmaxxed. You are just clickfarming
English
Kimi K2.6 tops the benchmarks.
And can't build a working website.
I ran it through my real vibe coding workflow.
Broken light mode. Random white block on pricing.
Random controls on a lava lamp.
Benchmaxed models look great on a leaderboard.
They fall apart in production.
Full breakdown below.
BridgeMind@bridgemindai
Kimi K2.6 just dropped. And it crushed Claude Opus 4.6 on SWE-Bench Pro. Kimi K2.6: 58.6 GPT-5.4 xhigh: 57.7 Gemini 3.1 Pro: 54.2 Claude Opus 4.6: 53.4 An open source Chinese model is now #1 on agentic coding. Frontier labs have a problem.
English
@orelohayo @bridgemindai He made a vibe coded benchmark, he literally has no plan what he is doing
English
KIMI K2.6 IS BENCHMAXED.
I ran the BridgeBench lava lamp test on four models.
GLM 5.1: pixel cube in a column.
GPT-5.4: static bubbles. No flow.
Kimi K2.6: a yellow rectangle.
Claude Opus 4.7: an actual lava lamp.
Chinese models ace benchmarks.
Claude ships software.
English
@bridgemindai @matthewmillerai Crazy, I am beginning to think that you rly have no clue
English
Claude Opus 4.7 is so good I just bought two Max subscriptions.
After vibe coding for over 12 hours yesterday I can confirm this is the best model in the world.
It burns tokens fast.
But the coding output is unmatched.
Two $200/month Max plans so I never hit a rate limit again.

English



My friend got Copilot Pro for absolutely free for the next 2 years 🔥
Does the plan provide full access to Opus 4.6 ?

English
@RyanLeeMiniMax Wait so if I use minimax not self hosted and vibe code, i can do it only non commercial?
English

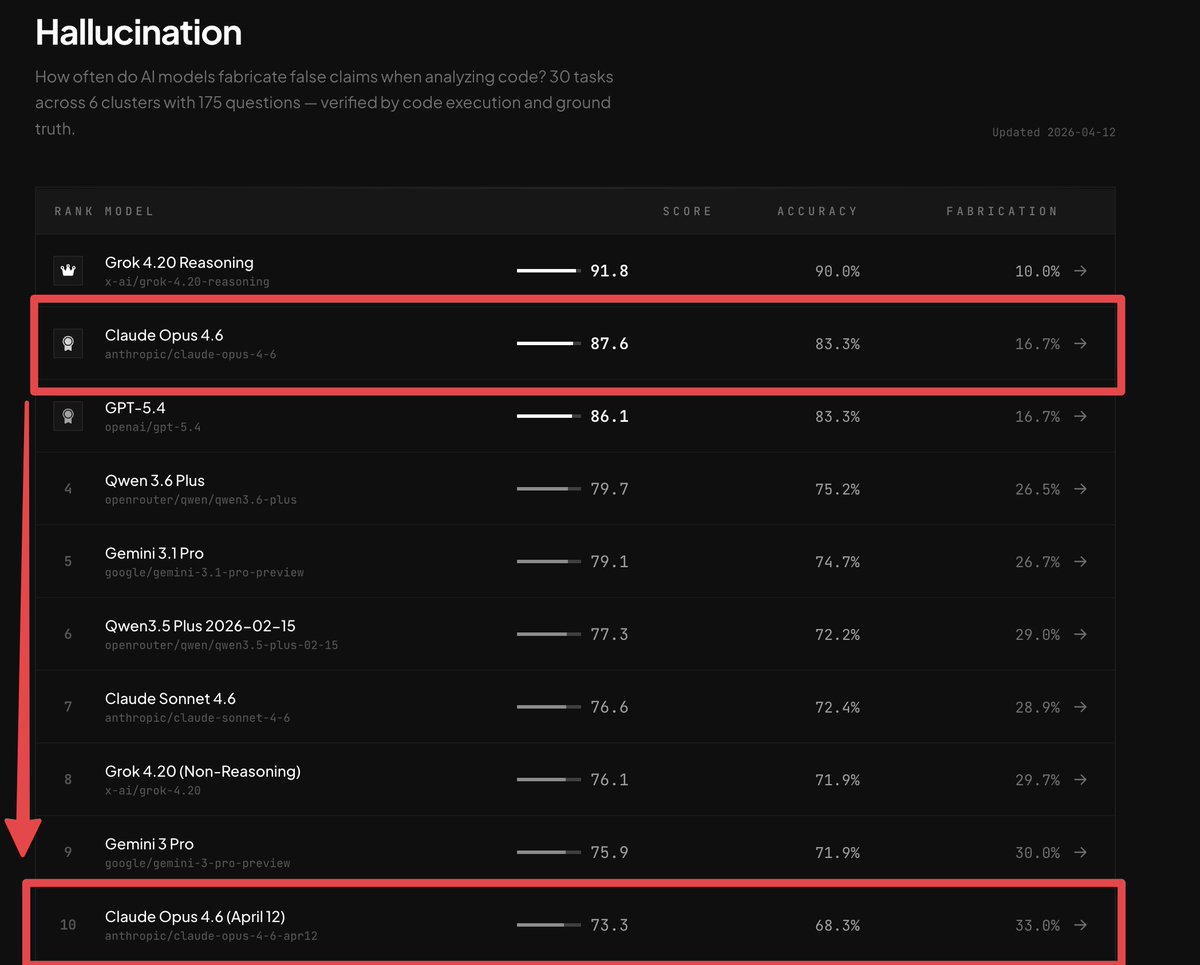
CLAUDE OPUS 4.6 IS NERFED.
BridgeBench just proved it.
Last week Claude Opus 4.6 ranked #2 on the Hallucination benchmark with an accuracy of 83.3%.
Today Claude Opus 4.6 was retested and it fell to #10 on the leaderboard with an accuracy of only 68.3%.
A 98% increase in hallucination.
bridgebench.ai just confirmed that Claude Opus 4.6 has reduced reasoning levels and is nerfed.
English