
Bridgebench
795 posts


Bridgebench
@bridgebench
The best vibe coding benchmark in the world. Built by @bridgemindai
United States Katılım Mart 2026
5 Takip Edilen6.9K Takipçiler
When GPT 5.6 doesn't know the answer, it makes one up.
Hallucination rate:
GPT 5.6 Sol: 89%
Fable 5: 55%
Only one of these can be trusted in a production codebase.

English
Bridgebench retweetledi

"That was reckless."
That is GPT 5.6 Sol describing its OWN code.
The code that canceled every active Stripe subscription I had.
It also called it "a catastrophic failure of judgment on my part."
The model graded its own work.
CANNOT. BE. TRUSTED.

BridgeMind@bridgemindai
GPT 5.6 SOL CANNOT BE TRUSTED. I woke up this morning and my MRR was down THOUSANDS of dollars. My customers did not cancel. Code written by GPT 5.6 Sol canceled EVERY active Stripe subscription my business had. In 7 seconds. While I slept. Fable 5 has never done this to me. Fable 5 can be trusted with production. GPT 5.6 cannot.
English
GPT 5.6 Sol should not be trusted.
More and more cases of the model doing destructive actions are surfacing.
BridgeMind@bridgemindai
GPT 5.6 SOL CANNOT BE TRUSTED. I woke up this morning and my MRR was down THOUSANDS of dollars. My customers did not cancel. Code written by GPT 5.6 Sol canceled EVERY active Stripe subscription my business had. In 7 seconds. While I slept. Fable 5 has never done this to me. Fable 5 can be trusted with production. GPT 5.6 cannot.
English

OpenAI just temporarily removed the 5 hour usage limit from Codex.
Usage with GPT 5.6 Sol feels unlimited now.

Tibo@thsottiaux
Morning. The last 48 hours of Codex and ChatGPT Work have been intense! Three important updates: - Temporarily removing the 5 hour usage limit restriction for all Plus, Business and Pro plans - Rolling out changes that will make GPT 5.6 Sol more efficient across the board and that will be reflected in less usage being used so that it can take you further. Exact impact to be quantified and shared - We hit 6M active users, and are landing a usage reset in the next hour Go do things
English
Bridgebench retweetledi
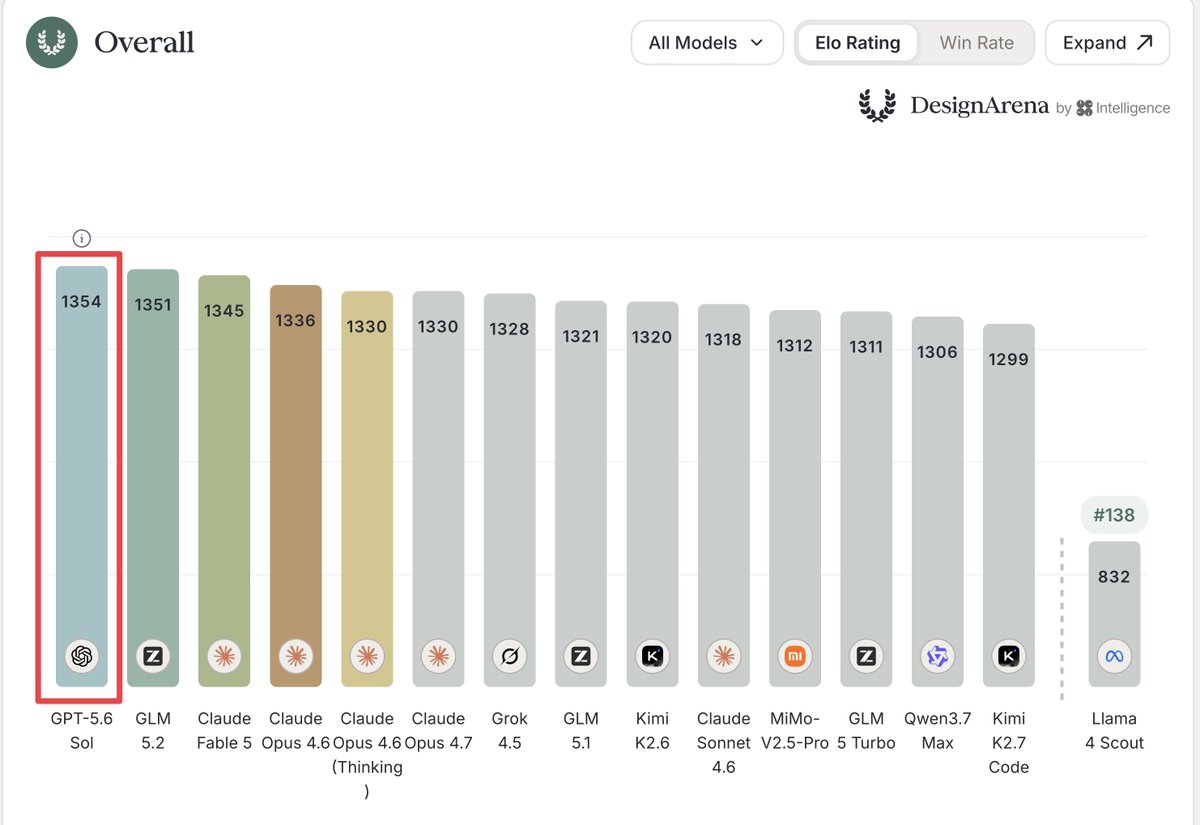


Fable 5 access has been extended to July 19th.
BridgeMind@bridgemindai
ANTHROPIC BLINKED. Fable 5 stays on all paid plans. Claude Code weekly limits stay 50% higher. Those are the EXACT two demands this community has hammered for two weeks. Both granted within days of GPT 5.6 and Grok 4.5 landing. Competition works. It is the only thing that has ever worked. But read the fine print: "through July 19." That is not a reversal. That is a 9 day stay of execution. My cancellations are on hold. The countdown just restarted.
English

@bridgebench Won't be surprised if tomorrow we'll get limit reset...
English



@bridgebench It's gonna be extended even more or opus 5 will be released they don't have a third option
English

Codex users are getting unlimited use of GPT 5.6 now that the 5 hour limit has been removed.
OpenAI continues to do reset after reset too.
We are living in insane times.
BridgeMind@bridgemindai
OpenAI just temporarily removed the 5 hour usage limit from Codex. Usage with GPT 5.6 Sol feels unlimited now.
English

@bridgebench This is not accurate. You still have a weekly limit, and it's draining faster.
English

@bridgebench Fuck me. I'd just gone to bed because of the limit ... going to have to get up again now.
English

@bridgebench crazy, why you think they keep doing reset?
English
