byMAR.CO
841 posts


byMAR.CO
@MarcoTundo
Master Biomechanical Engineer, Human AI Consultant - I build AI on a Farm. Prev CTO https://t.co/YUQrtFP3DJ, https://t.co/oEOh3lNDP3

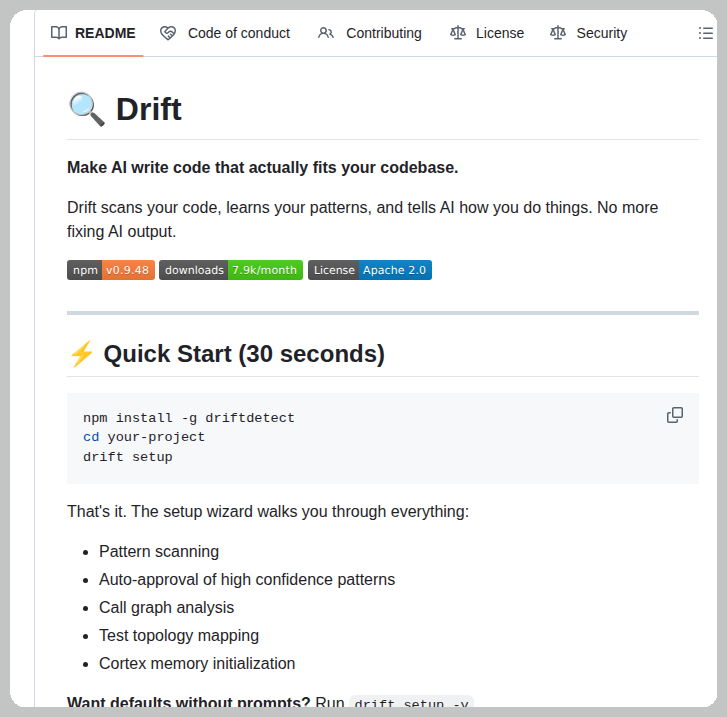
this is what 12 gigs of VRAM built in 2026. a 9 billion parameter model running on a 5 year old RTX 3060 wrote a full space shooter from a single prompt. blank screen on first try. i came back with a bug list and the same model on the same card fixed every issue across 11 files without touching a single line myself. enemies still looked wrong so i pushed another iteration and now the game has pixel art octopi, particle effects, screen shake, projectile physics and a combo system. all running locally on a card that was designed to play fortnite. three iterations. zero cloud. zero API calls. every token generated on hardware sitting under my desk. the model reads its own code, finds what's broken, patches it, validates syntax and restarts the server. i just describe what's wrong and it handles the rest. people are paying monthly subscriptions to type into a browser tab and wait for a server farm to respond. meanwhile a GPU you can find used on ebay is running a full autonomous hermes agent framework with 31 tools, 128K context window and thinking mode generating at 29 tokens per second nonstop. the game still needs work. level upgrades don't trigger and boss fights need tuning. but the fact that i'm iterating on gameplay balance instead of debugging whether the code runs at all tells you where this is headed. every iteration the game gets better on the same hardware. same 12 gigs. same 9 billion parameters. same RTX 3060 from 5 years ago your GPU is not a gaming card anymore. it's a local AI lab that never sends your data anywhere.




Gemini Embedding 2 is out. It’s a natively multimodal embedding model that maps text, images, video, audio and documents into a single embedding space: - text, up to 8192 input tokens - images, up to 6 images per request - videos, up to 120 seconds - audio, natively ingests and embeds audio data without any intermediate text transcriptions - documents, directly embed PDFs up to 6 pages long blog.google/innovation-and…



🚀 Introducing the Qwen 3.5 Small Model Series Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B ✨ More intelligence, less compute. These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL: • 0.8B / 2B → tiny, fast, great for edge device • 4B → a surprisingly strong multimodal base for lightweight agents • 9B → compact, but already closing the gap with much larger models And yes — we’re also releasing the Base models as well. We hope this better supports research, experimentation, and real-world industrial innovation. Hugging Face: huggingface.co/collections/Qw… ModelScope: modelscope.cn/collections/Qw…

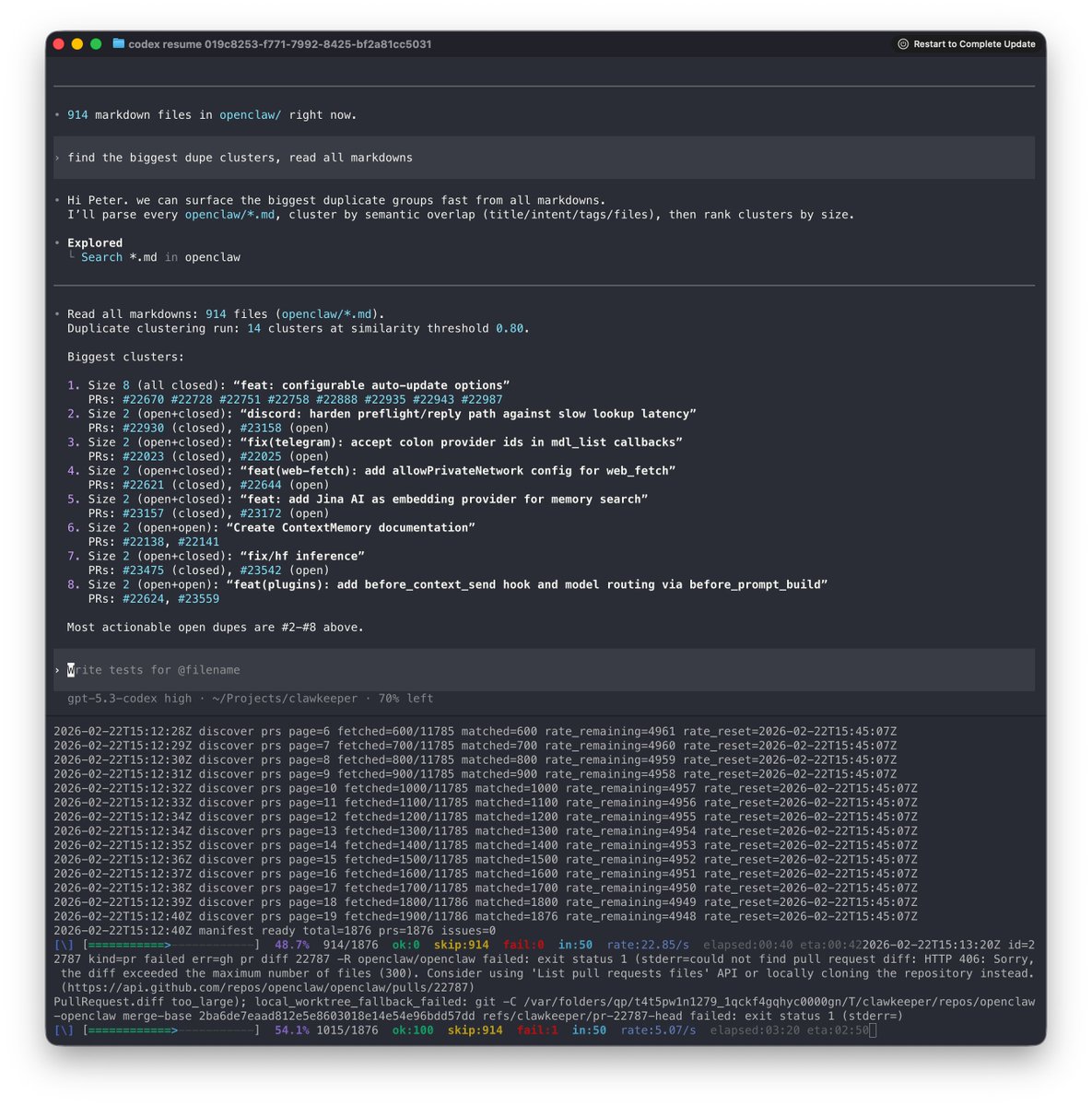
if open source models are hitting 113 tok/s at 262K context on a single rtx 3090s today, edge devices aren't far. every engineer, every researcher, every builder will run local inference. no API keys, no subscriptions, no permission needed. nothing is more dangerous to closed AI than open source that actually works. chinese labs have been shipping relentlessly. MoE, hybrid architectures, models designed to run on smaller hardware. constraints bred innovation. while others gatekeep, they ship. and the results speak for themselves. been running this little one for hours now and i just love it. this is actually good if you can steer it.