Sabitlenmiş Tweet

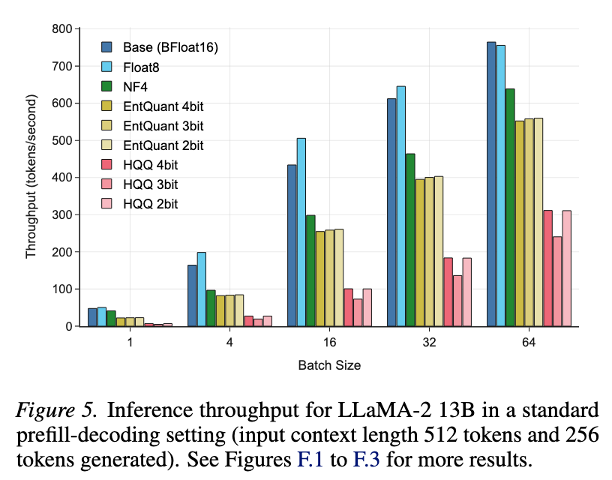
The LLM compression community is obsessed with quantizing to ever lower bit-widths.
But below 4 bits, returns start diminishing, requiring many tricks & hacks to prevent collapse.
What if 8-bit + smarter compression beats the low-bit race?
📢 Thrilled to introduce EntQuant …
English