
Massimo Bardetti
857 posts

Massimo Bardetti
@MassimoBardetti
After many twist and turns, I found may way home. CTO at https://t.co/uu1wd71Fbk, working on frontier language models based on cognitive science research.
Oakland, CA Katılım Mayıs 2014
538 Takip Edilen297 Takipçiler

GM!
And here it is!!!
Made this little Christmas scene using Blender and Grok Imagine 🎄
Sometimes Toby doesn’t do much — just walks, listens, and lets the lights do the talking.
Music by my friend @xDominithx ✨
Still one of my favorite winter moods.
English
Massimo Bardetti retweetledi

At NEMES nemes.app, we're building a future where young hackers can create DIY brain wave kits.
Imagine, teenagers exploring their own cognition through games, just like Neha's pioneering research.
English
Massimo Bardetti retweetledi
I recently spoke at @gamesforum in SF
I discussed how curriculum should adapt to each student. I learned that great games need years of experiments. Ads must fit the game's story. Metrics like ARPUU and ROAS are vital. Segmentation is also key to understanding players.

English
First time writing a C++ lambda function and using the auto keyword.
Its like writing Javascript...
This is to test the MLX library mlx::compile functionality.
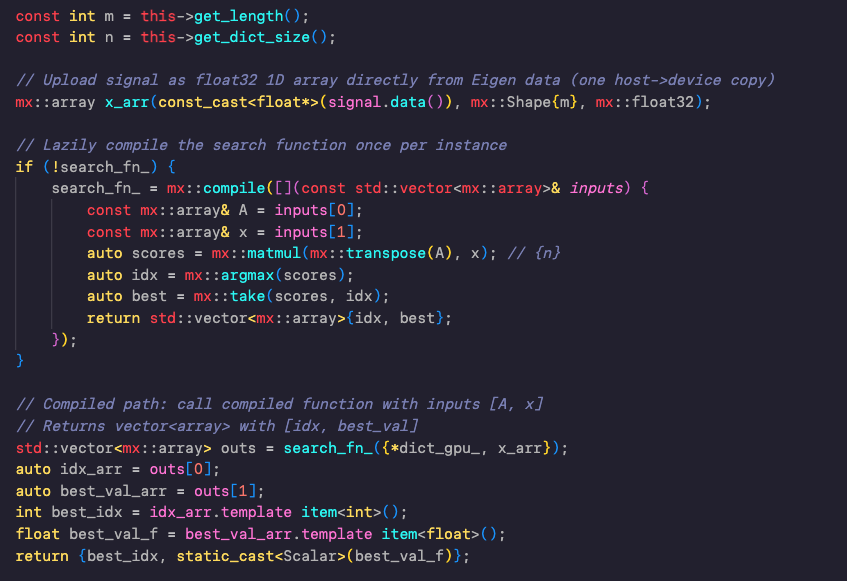
English
Blog post with performance results here :
byron-the-bulb.github.io/act/2025/10/18…
English
I used NVidia ncu to profile my test code, and discovered how the two implementations differ slightly.
Seems like the arg_reduce_general + gather of MLX is not as fast as iamax (multipass?) of cuBLAS.
For now, this is how far I got to.. more to come as I take a look at the MLX kernels.

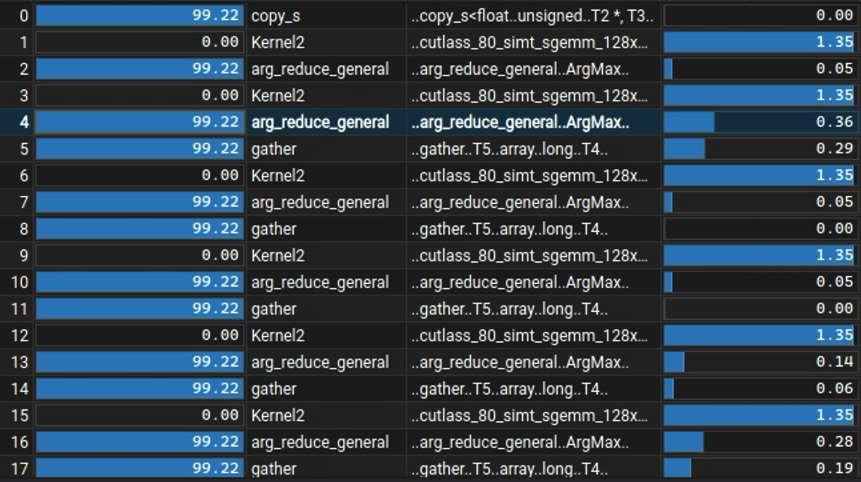
English
Continuing my side quest into the Apple MLX library...
First I wanted to test mlx::compile from c++, then I wanted to compare the performance of the mlx CUDA backend with a cuBLAS version of the algorithm.
The core algorithm is quite simple, a matmul and a argmax, the two versions are in the picture.
My test results showed the cuBLAS version performing approximately 20% faster than MLX with CUDA... I wanted to know why.
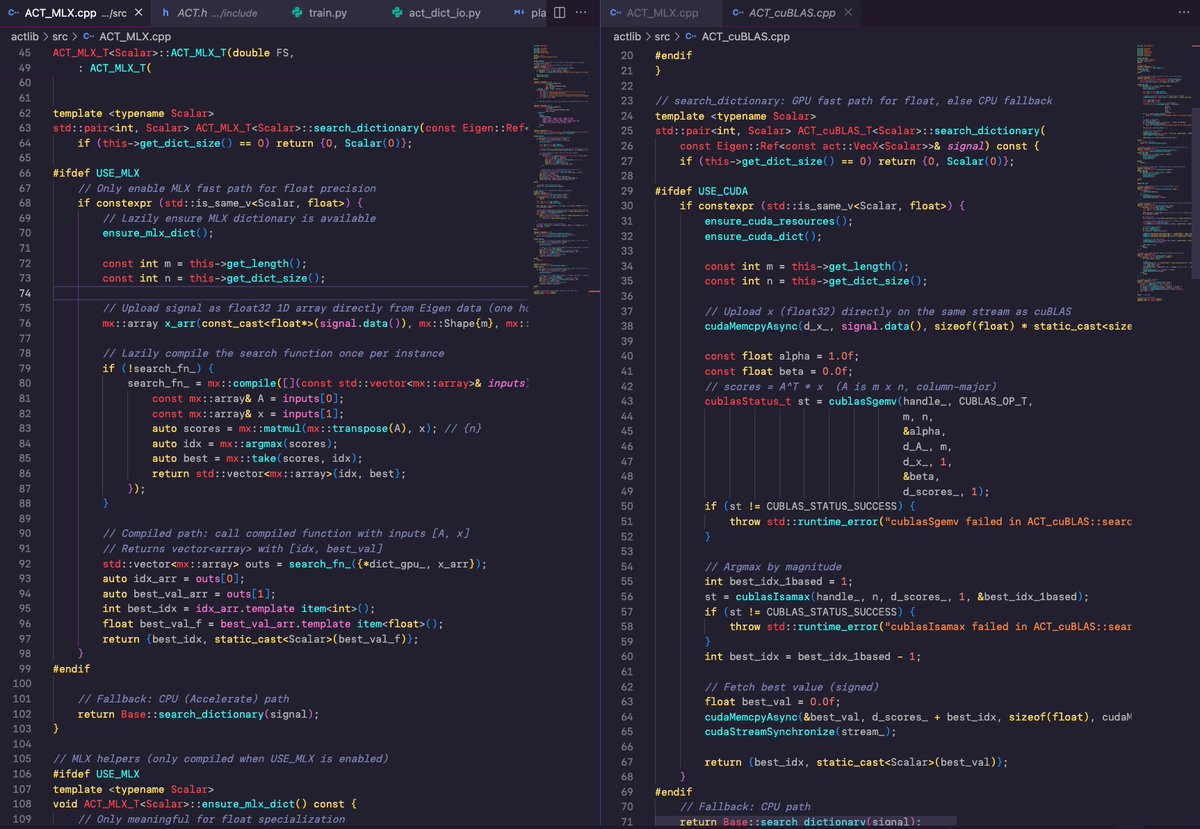
English
This is a very interesting paper which formalizes the way myself, and probably many other AI engineers, been optimizing the prompt context.... by just changing sections of it.
I, very early on, realized that having an orchestrator LLM rewrite the whole prompt, is just moving the problem up one level.
On a positive note I hope that AI agents will expand out of the systems engineering and MLOps/DevOps field, and begin to be formalized and be used to replicate human brain models from cognitive science.
Robert Youssef@rryssf_
RIP fine-tuning ☠️ This new Stanford paper just killed it. It’s called 'Agentic Context Engineering (ACE)' and it proves you can make models smarter without touching a single weight. Instead of retraining, ACE evolves the context itself. The model writes, reflects, and edits its own prompt over and over until it becomes a self-improving system. Think of it like the model keeping a growing notebook of what works. Each failure becomes a strategy. Each success becomes a rule. The results are absurd: +10.6% better than GPT-4–powered agents on AppWorld. +8.6% on finance reasoning. 86.9% lower cost and latency. No labels. Just feedback. Everyone’s been obsessed with “short, clean” prompts. ACE flips that. It builds long, detailed evolving playbooks that never forget. And it works because LLMs don’t want simplicity, they want *context density. If this scales, the next generation of AI won’t be “fine-tuned.” It’ll be self-tuned. We’re entering the era of living prompts.
English
Massimo Bardetti retweetledi

New in-depth blog post time: "Inside NVIDIA GPUs: Anatomy of high performance matmul kernels". If you want to deeply understand how one writes state of the art matmul kernels in CUDA read along.
(Remember matmul is the single most important operation that transformers execute both during training and inference. Most of NVIDIA compute is spent on it. Gaining 1% in efficiency translates to massive savings in the order of many nuclear reactors :P)
I, yet again, realized i underestimated the effort. 😅 Here is one more booklet (lol). 47 figures!
I covered:
* The fundamentals of the GPU architecture with an emphasis on the memory hierarchy, building mental models for GMEM, SMEM, and L1/L2, and then connecting them to the CUDA programming model. Along the way we also looked at the "speed of light," how it's bounded by power, with hardware reality leaking into our model.
* PTX/SASS, and how to steer the compiler into generating what we actually want (is that loop being unrolled, are we using vectorized loads like LDG.128, etc.). I've annotated one PTX/SASS example for a simple matmul kernel in excruciating detail. Even if you're new to compilers you should find this useful.
(i actually found various inefficiencies in both compilers - fun!)
* Many core concepts such as tile/wave quantization, occupancy, ILP (instruction-level parallelism), roofline model, etc. Also building intuition around fundamental equivalences: dot product as a sum of partial outer products, why square tiles are the right shape for high arithmetic intensity, etc.
* The warp tiling method - which is near SOTA assuming you can't use tensor cores, TMA, async mem instructions, and bf16. Just maximizing GPU's performance using nothing but CUDA cores, registers and shared memory.
* Finally, we step into Hopper (H100): TMA, swizzling, tensor cores and the wgmma instruction, async load/store pipelines, scheduling policies like Hilbert curves, clusters with TMA multicast, faster PTX barriers, and more.
As always lots of examples, lots of visuals. This is the first time i could see warp tiling kernel and be like "oh i get it completely". I just needed my mental image transformed into an actual image.
A few years ago I was really inspired by @Si_Boehm's excellent blog post on how matmul works, but I also found it had several errors, some unclear explanations, and it was quite outdated. Building on @pranjalssh amazing work (who did a great job building sota kernels for H100) and my own research, this is the final result.
---
Again a huge thank you to @Hyperstackcloud (GPU cloud) for giving me an H100 (PCIe) node to run some of the experiments and analysis that i needed to write this up.
Also a big thank you to my friends Aroun (who did a very thorough review of the post; Aroun's doing cool GPU/AI stuff at Magic and was previously GPU architect at Apple and Imagine, he's one of the best GPU people i know and we worked together on llm.c w/ @karpathy) and the amazing @marksaroufim! (PyTorch) for taking the time during weekend when they didn't have to. :)

English
GIF
Alameda, CA 🇺🇸 English

some personal news:
@max_maksutovic and I are joining @Prafulfillment to build a collar that allows you to talk to dogs!
super excited to be working on this!!
English
@YayaSoumah @PlaguePoppets @jedhathaway The project had to be paused. I am working towards reviving it soon.
English

English
Here is a sneak peek of the very first @PlaguePoppets animation short.
Created by artist @JuliAdamsArt, directed by @jedhathaway and produced by yours truly.
Built on #UnrealEngine5 !
Check out the main Plague Poppets account for ways that you can help us finish this episode.
Donate, buy or NFTs, and follow us to stay updated on the project!
English
@ChShersh I already know that I should not have said "cross-compile"...
x.com/MassimoBardett…
Massimo Bardetti@MassimoBardetti
The Apple MLX library is very handy! It has Apple Metal and CUDA backends, and can be easily cross-compiled on MacOS and Linux. Here is my implementation of a matching pursuit dictionary search, which is a greedy inner product of a source signal over a multi dimensional matrix of atoms. The code compiled effortlessly on my Macbook Pro M1 Max, and a Ubuntu Linux Intel i9 with NVidia RTX4090 GPU, with the GPU branching fully working. I tested it successfully on a dictionary of 600K atoms (1.1GB in memory).
English

Call to action:
If you’ve seen a C++ post I haven’t replied to, let me know.
I’ll fix it.
English
Ah! I probably should have not said "cross-compiled", but "cross-platform"
Cross compilation was never my goal, its hard enough to do without GPU specifics.
The gist is that the project builds and executes on both platforms without changing the code or gnarly pre-processor directives.
One Makefile, here is MacOS vs Linux branching.

English

@MassimoBardetti cross compile something easily on mac when you are not even able to cross compile arm bin on x86? easily sounds dubious...
English
The Apple MLX library is very handy! It has Apple Metal and CUDA backends, and can be easily cross-compiled on MacOS and Linux.
Here is my implementation of a matching pursuit dictionary search, which is a greedy inner product of a source signal over a multi dimensional matrix of atoms.
The code compiled effortlessly on my Macbook Pro M1 Max, and a Ubuntu Linux Intel i9 with NVidia RTX4090 GPU, with the GPU branching fully working.
I tested it successfully on a dictionary of 600K atoms (1.1GB in memory).

English
I don't know... yet.
When I started the ACT project I thought I was going to learn to write CUDA kernels, but I stopped at MLX because I can code and test on my Mac, then build on Linux/CUDA without much fussing around.
I am still interested in learning to write CUDA DSLs, so I will probably give it a go soon. Will post my profiling results here.
English

@MassimoBardetti Can you do inline PTX for the cuda path? Also, how does it compare to using triton/cute-dsl in terms of perf?
English
@MinChonChiSF Yup, it falls back to BLAS on CPU, which is desirable if precision is required over speed, as it can use double64 vs. float32.
Alameda, CA 🇺🇸 English

@MassimoBardetti Interesting use of MLX for matching pursuit. I see the #ifdef USE_MLX block.
English
@ProbioticFarmer Will do.
Did you try to build your project with the cuda backend? Wondering how it compares in performance with the non-MLX implementation.
Alameda, CA 🇺🇸 English

@MassimoBardetti open source for the win
lmk if you need any help with the deterministic implementation. i have the full openai style endpoint code in the repo now so it should be pretty easy
English
I had to Google that... this was in the summary :
"Appearance on the trace: The signal begins with low frequency and amplitude, which gradually increase over time. This creates a "chirp" sound when the signal is converted to audio."
So, yes, potentially, the algorithm could be used to detect those chirps among a noisy signal.
I have a page that has an interactive chirplet workbench with audio playback here :
byron-the-bulb.github.io/act/2025/09/18…
Alameda, CA 🇺🇸 English

@MassimoBardetti Hmm.
Is this basically the same problem as figuring out the source of a particular gravitational wave trace?
Sounds like something similar...
English
@EdwardRaffML Can't comment on that yet. Our next step is to try to use this library for feature extraction from EEG signals and train a model ... I am tempted to use C++ with MLX instead of the usual python sauce.
Alameda, CA 🇺🇸 English

@MassimoBardetti How’s the autodiff work in the c++ api? Equally transparent?
English
@ProbioticFarmer Nice! TIL LLMs are non deterministic because of batch size.
Actually, that TM article may explain a small variance in signal-to-noise ratio that I am seeing across runs. Thanks.
Alameda, CA 🇺🇸 English
@MassimoBardetti that is hot
github.com/ProbioticFarme…
English
@jg_zap The proof is in the pudding. Clone the repo and try to build and run on both platforms.
I could use some feedback on installation instructions.
github.com/nemes-inc/ACT-…
Alameda, CA 🇺🇸 English

@MassimoBardetti - si lo q dices es verdad, estamos ante otra revolución próximamente
Español