Matin
197 posts

Matin
@MatinMnM
Building non-euclidean models
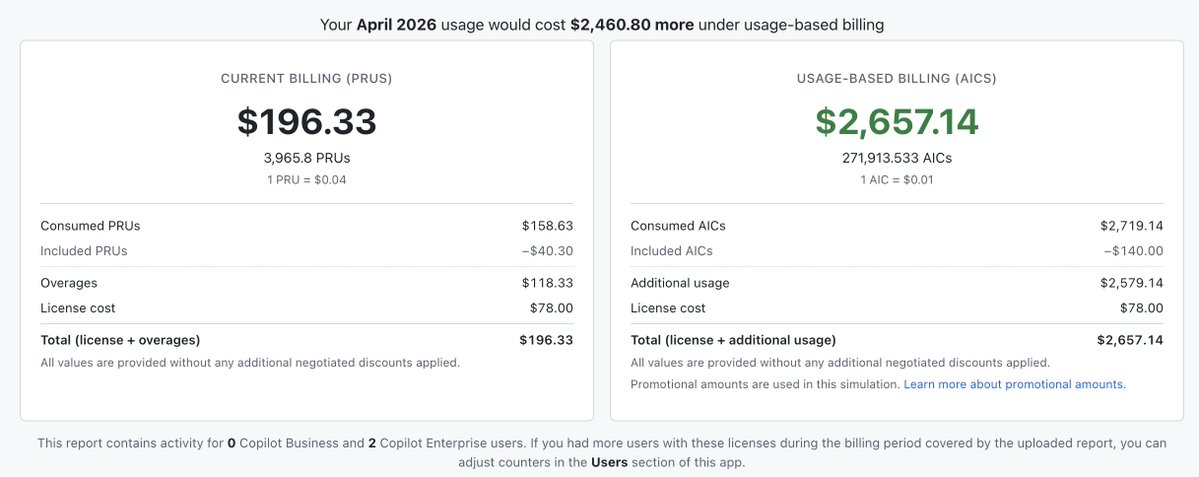






Opus 4.7 is 50% more expensive even though its still $5/25 pricing I call this the tokenizer tax, where the same prompt now produces 25% more tokens on average. So API costs are on average 25% higher. But 50% more expensive for SQL, and 35% for Python I calculated this by running different samples through the token counting api


Opus 4.7 is 50% more expensive even though its still $5/25 pricing I call this the tokenizer tax, where the same prompt now produces 25% more tokens on average. So API costs are on average 25% higher. But 50% more expensive for SQL, and 35% for Python I calculated this by running different samples through the token counting api


Opus 4.7 is 50% more expensive even though its still $5/25 pricing I call this the tokenizer tax, where the same prompt now produces 25% more tokens on average. So API costs are on average 25% higher. But 50% more expensive for SQL, and 35% for Python I calculated this by running different samples through the token counting api

Opus 4.7 is 50% more expensive even though its still $5/25 pricing I call this the tokenizer tax, where the same prompt now produces 25% more tokens on average. So API costs are on average 25% higher. But 50% more expensive for SQL, and 35% for Python I calculated this by running different samples through the token counting api


Introducing Claude Opus 4.7, our most capable Opus model yet. It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back. You can hand off your hardest work with less supervision.
Opus 4.7 is 50% more expensive even though its still $5/25 pricing I call this the tokenizer tax, where the same prompt now produces 25% more tokens on average. So API costs are on average 25% higher. But 50% more expensive for SQL, and 35% for Python I calculated this by running different samples through the token counting api

Opus 4.7 is WORSE than 4.6 on Long Context?

Open source is dead. That’s not a statement we ever thought we’d make. @calcom was built on open source. It shaped our product, our community, and our growth. But the world has changed faster than our principles could keep up. AI has fundamentally altered the security landscape. What once required time, expertise, and intent can now be automated at scale. Code is no longer just read. It is scanned, mapped, and exploited. Near zero cost. In that world, transparency becomes exposure. Especially at scale. After a lot of deliberation, we’ve made the decision to close the core @calcom codebase. This is not a rejection of what open source gave us. It’s a response to what risks AI is making possible. We’re still supporting builders, releasing the core code under a new MIT-licensed open source project called cal. diy for hobbyists and tinkerers, but our priority now is simple: Protecting our customers and community at all costs. This may not be the most popular call. But we believe many companies will come to the same conclusion. My full explanation below ↓



1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵