I created a utility for memoization of parameter sweeps called chunk-memo. It collects multiple runs to be written to single files for increased disk read/write efficiency (chunking) including parallelization. github.com/msf235/chunk-m….
@cloneofsimo Nova has been freely available on public channels for four decades. Maybe we should be asking, “why can’t we get these content creators public grants to supplement their ad revenue?”
Interestingly, the tempo of a recalled sequence can differ from that of the "tutor signal" used to teach the network. We show how this works, relating the shape of the STDP kernel and the tutor signal tempo to the dynamics of the recalled sequence, including its own tempo.
My paper with @CPehlevan is out now in PNAS! doi.org/10.1073/pnas.2… Sequences are a core part of an animal's behavioral repertoire, and Hebbian learning allows neural circuits to store memories of sequences for later recall.
It’s become trendy to use trained neural networks as models for the brain. New theory is helping us appreciate the different approaches neural networks will use to solve tasks depending on initialization, optimization, and other details. Our review here: authors.elsevier.com/c/1hplN3Q9h2Ee…
@KameronDHarris I'm not sure what all the hype around threads was as the instagram influencers and coorporate accounts flood it with crap. I'm still holding out how for bluesky once it's out of beta
For all you scientists contemplating alternatives to this site, what sways you one way or the other? Too many alternatives... Don't want to pick the wrong one
In this work we show how the tempo of the recalled sequences depends on the Hebbian learning kernel (such as the shape of an STDP curve) and the duration for which each step in the sequence is shown to the network by the tutor signal.
Here's a paper @CPehlevan and I wrote about neural networks that generate sequences: biorxiv.org/content/10.110…. Hebbian learning can store sequences as memories in neural networks for later recall. However, the tempo of the recalled sequence can differ from that of the tutor signal
@lemire@Dirivian I think talks are a decent proving ground: you present your work and it's judged primarily on being interesting and important, not so much on what journals it wound up in. Combine with looking over the papers. Perhaps tenure review should work this way?
@MattSFarrell@Dirivian Irrespective of the system in place, you need to prove yourself. You can offer a blog post as a contribution... and it might be accepted, but you have to argue your case.
@Dirivian Here is an interesting person who worked in a national lab in relative obscurity for a while, but his work is possibly quite revolutionary: en.wikipedia.org/wiki/Jean_%C3%…, tinyurl.com/hww53jss. I guess he somehow found a way to ignore brownie points.
@Dirivian Neural networks are essentially the most basic nonparametric hierarchical model that you can imagine. As such their ubiquity isn't really that surprising imo.
A long time ago I wrote a simple utility for managing the output of my simulations. I've finally gone to the trouble of cleaning it up enough to share: github.com/msf235/model_o…. This utility keeps a log of simulation parameters in a .csv file for simple but flexible memoization.
However, convolutional architectures built around other representations of the cyclic group can have higher expressivity. See the preprint for more info.
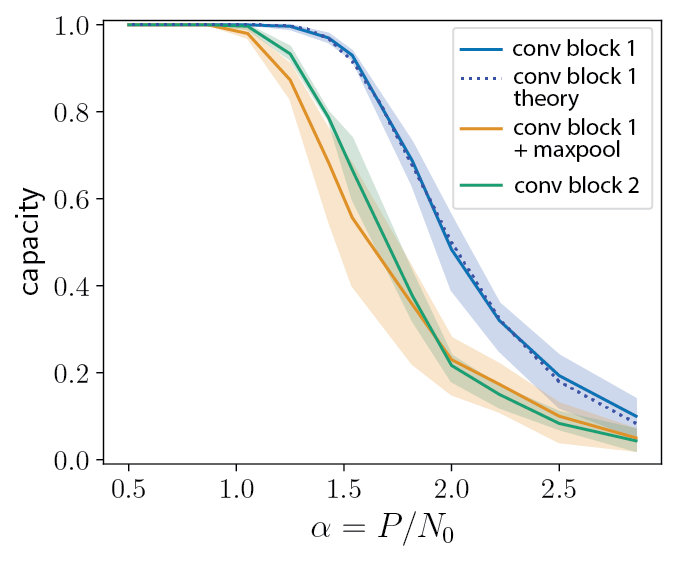
This reveals that the expressivity of standard convolutional network layers (in the case where inputs are shown at all possible cyclic shifts) is determined by the number of filters/output channels. Here is the expressivity/capacity of VGG11 as the number of filters varies.
New preprint arxiv.org/abs/2110.07472. We look at the expressivity of neural representations that are equivariant to their inputs -- that is, as input objects transform according to a group action, the representations transform according to an action of the same group.