Sabitlenmiş Tweet

🚀 MemOS Local Plugin 2.0 is LIVE — 1 memory engine, all Agents fully supported.
@NousResearch's Hermes and @openclaw both run on the same core from NOW on.
Add another Agent later? It's a thin adapter, not a fork
One severe issue kept coming back from users:
"An Agent can finish tasks, but can we trust what it learned?"
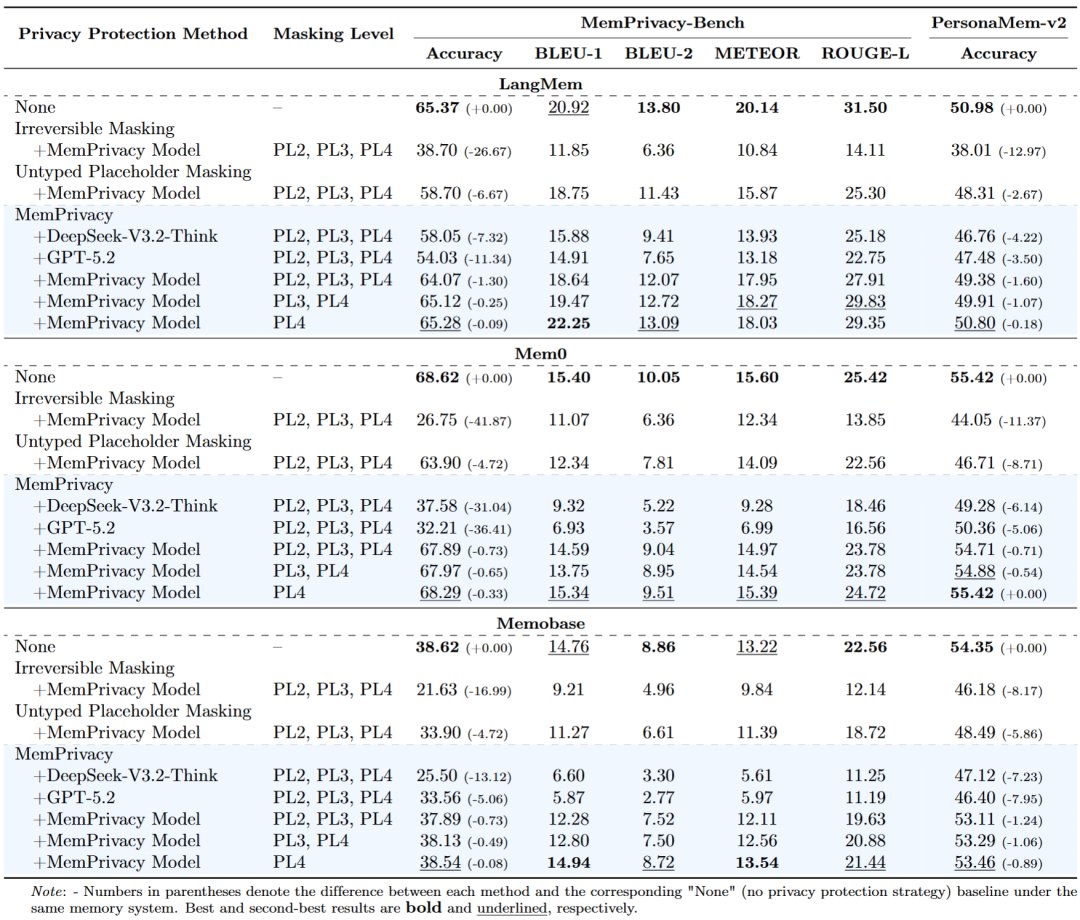
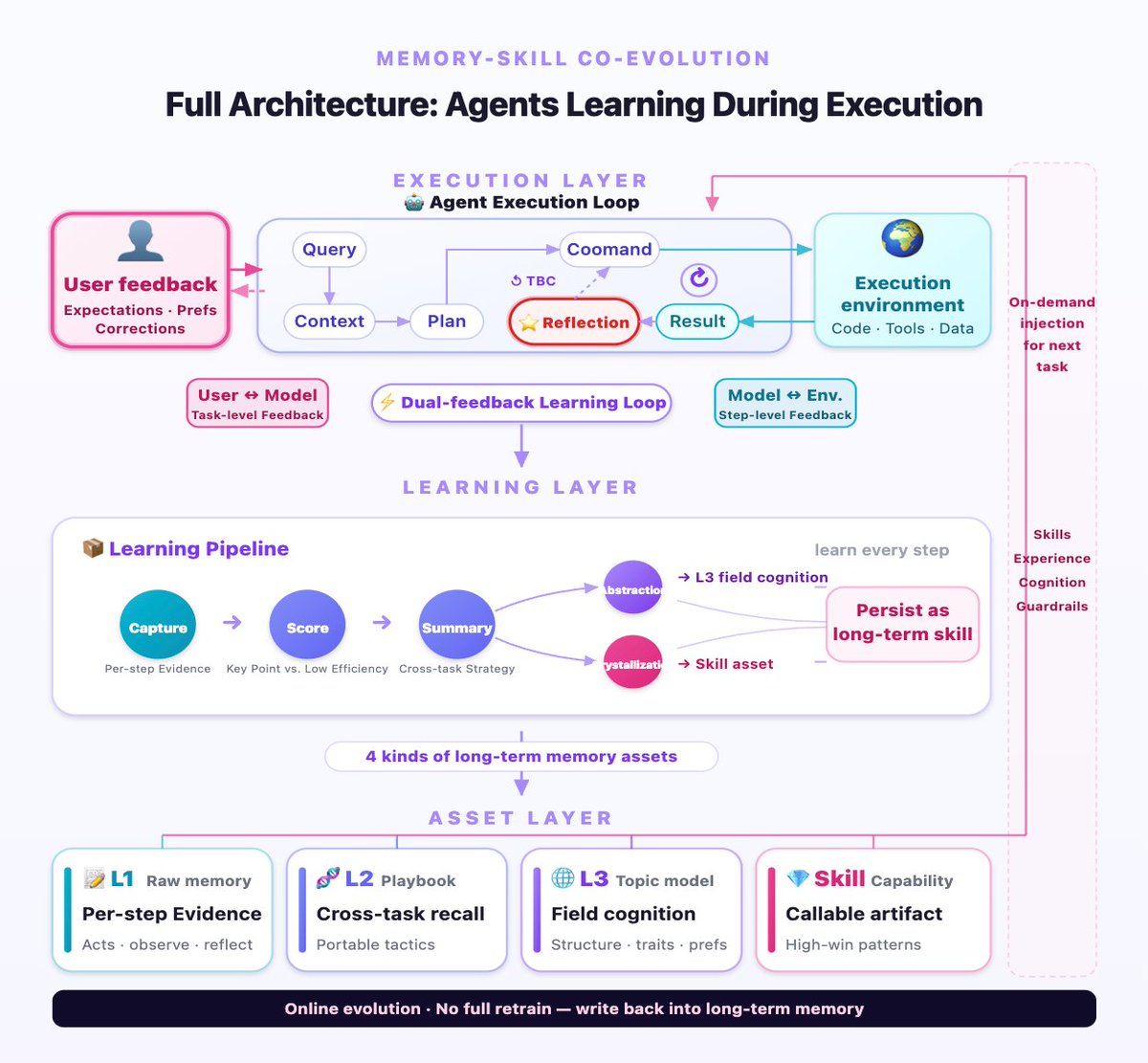
MemOS Local Plugin 2.0 is our answer: Execution as learning.
Not just storing chats, but turning each task step into reusable memory.

English