
Ruotian Ma retweetledi

Can AI agents autonomously explore, synthesize, and discover knowledge like researchers? 🤖🔬
Introducing a comprehensive survey on Deep Research (DR) systems, where LLMs evolve from passive text generators into autonomous agents capable of long-horizon reasoning and verifiable knowledge creation.
🗺️ Three-phase roadmap:
1⃣ Agentic Search → Precise evidence acquisition
2⃣ Integrated Research → Multi-source synthesis & reporting
3⃣ Full-stack AI Scientist → Hypothesis generation & discovery
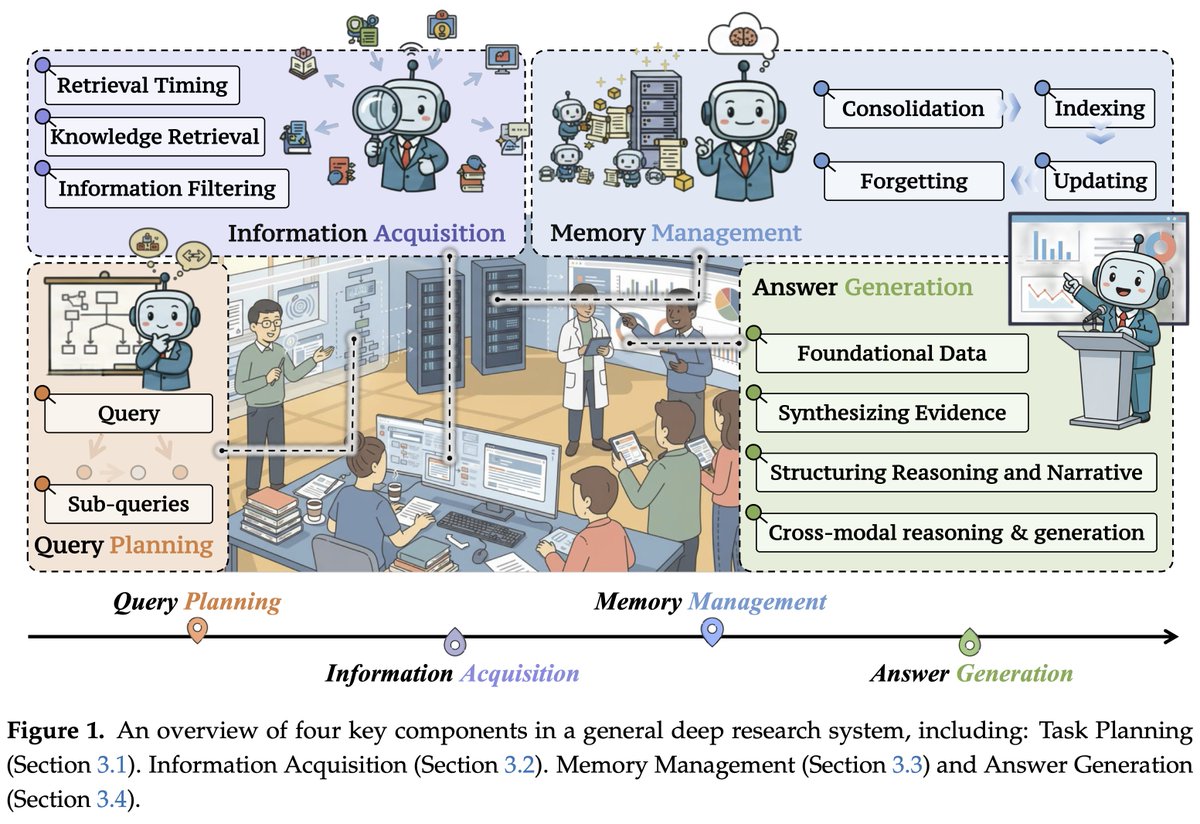
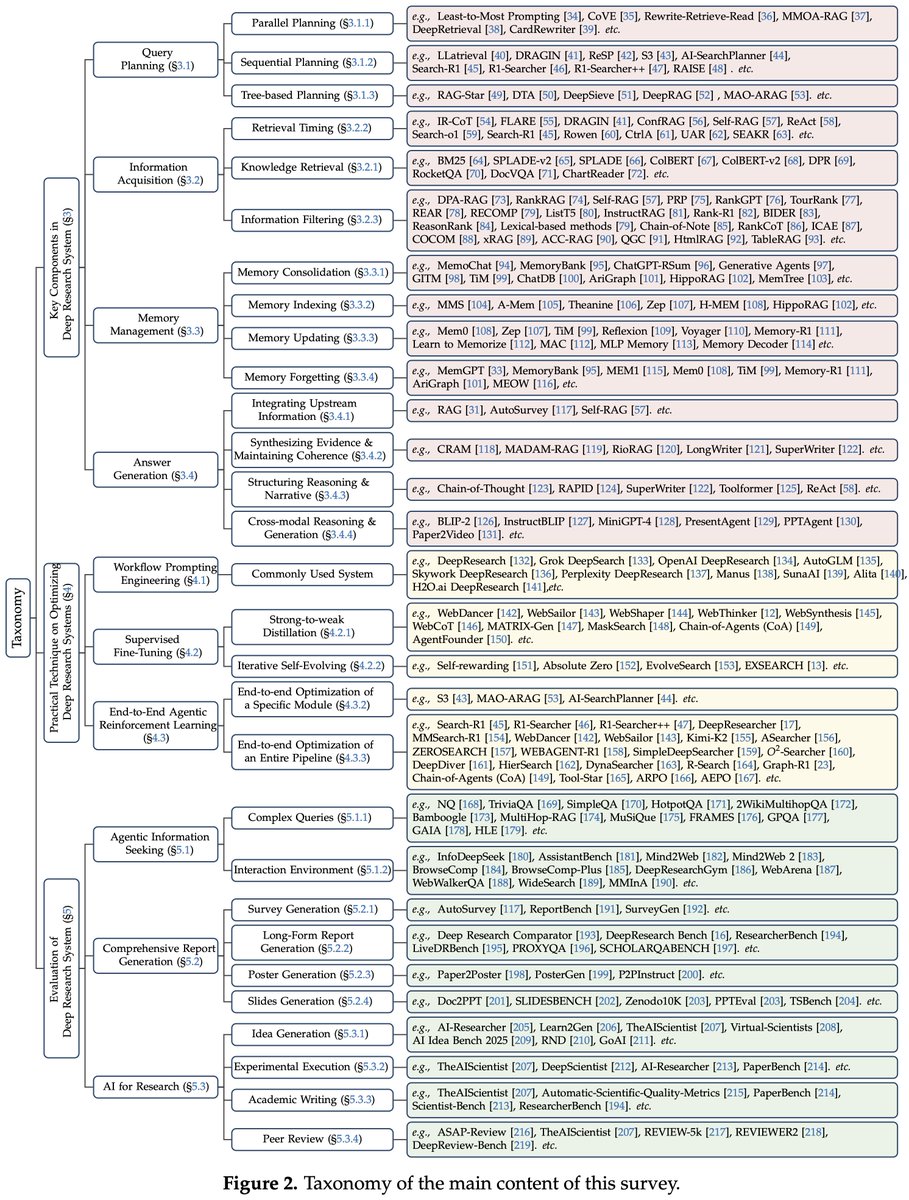
🔧 Four foundational components:
1⃣ Query Planning: Decompose complex questions (parallel, sequential, tree-based).
2⃣ Information Acquisition: Dynamically retrieve from web search, APIs, & multimodal sources.
3⃣ Memory Management: Store, update, and prune context over long horizons.
4⃣ Answer Generation: Synthesize verifiable, cited reports.
🚀 Three optimization paradigms:
1⃣ Workflow Prompting
2⃣ Supervised Fine-Tuning (SFT)
3⃣ End-to-End Agentic Reinforcement Learning (RL)
📊 Key Insight: DR is not just advanced RAG.
Unlike standard RAG, DR enables:
✅ Flexible interaction & tool use beyond static retrieval
✅ Long-horizon planning with autonomous workflows
✅ Reliable, verifiable, and structured outputs
📈 As the field evolves, we are committed to continuously updating this survey to reflect the latest progress!
🧑💻 Project: github.com/mangopy/Deep-R…
📃 Paper: preprints.org/manuscript/202…

English











