Jeffrey Li 💙💛
7K posts
Jeffrey Li 💙💛
@askerlee
Machine Learning researcher. Veritas.
Singapore Katılım Ocak 2010
1.3K Takip Edilen2.8K Takipçiler



@CSProfKGD My censorship radar (trained on thousands of Chinese posts) rings on "Chinese media coverage" 😂
English

@askerlee Very weird. Perhaps because I just joined the algorithm is sensitive?
English
Currently checking out RedNote. We’re thinking about expanding our #ECCV2026 social media coverage to the platform.

English

测试偏轴投影演示。 Blender 中的基础场景布局 GLB -> 通过 World Labs 详细喷溅 Three.js 发动机 面向追踪的 MediaPipe
xiao hai@xiaowo1800
我用2 个小时复刻了那个用摄像头做3D 非对称全息透视的家伙。 运用的技术: TensorFlow.js (AI 模型)、Three.js、独立双线程线型插值(Lerp Tracking。 运用模型:Claude opus4.6,gemini 3.1pro 只用笔记本自带摄像头,动一下头背景就跟着动,这种感觉太爽了
中文
@himself65 这种话没啥意义,即使不考虑量子效应带来的随机性,和我们关系最大的是地球这个小系统,地球外可能会出现大的扰动让地球的演化改变路径,历史上已经出现多次了,仅看这个系统是没什么确定性的
中文

@VukRosic99 I'm confused. Is the 16mb cap for the total param count? An MoE would have more params than its dense counterpart, won't it?
English

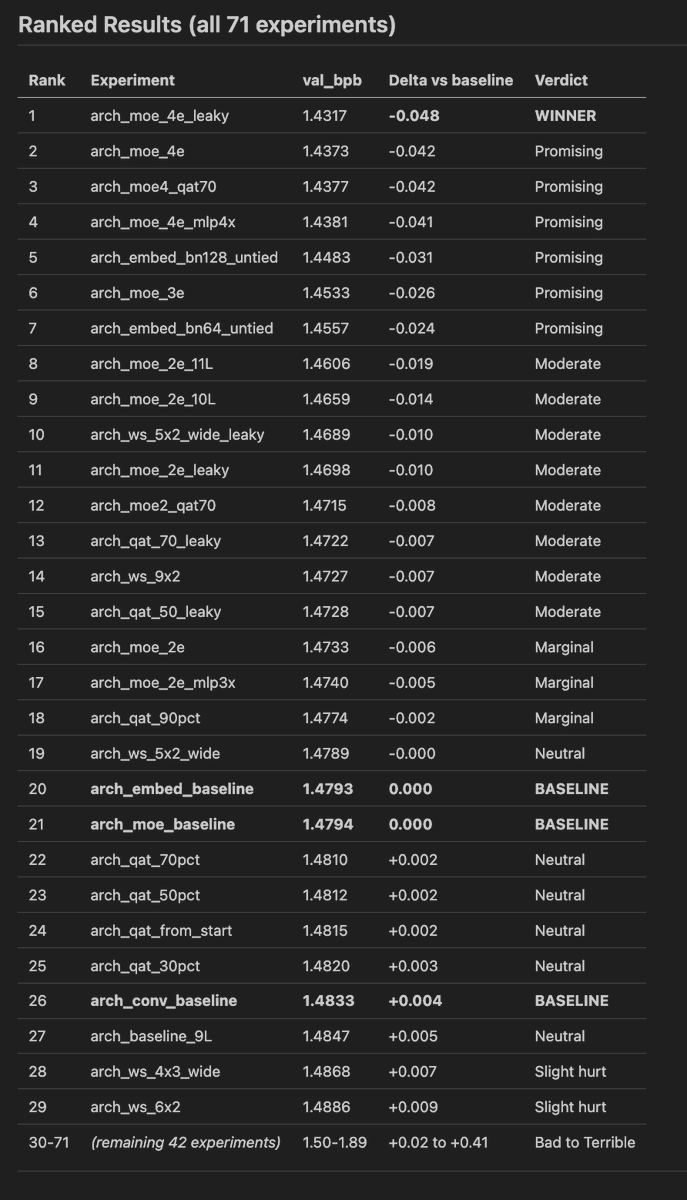
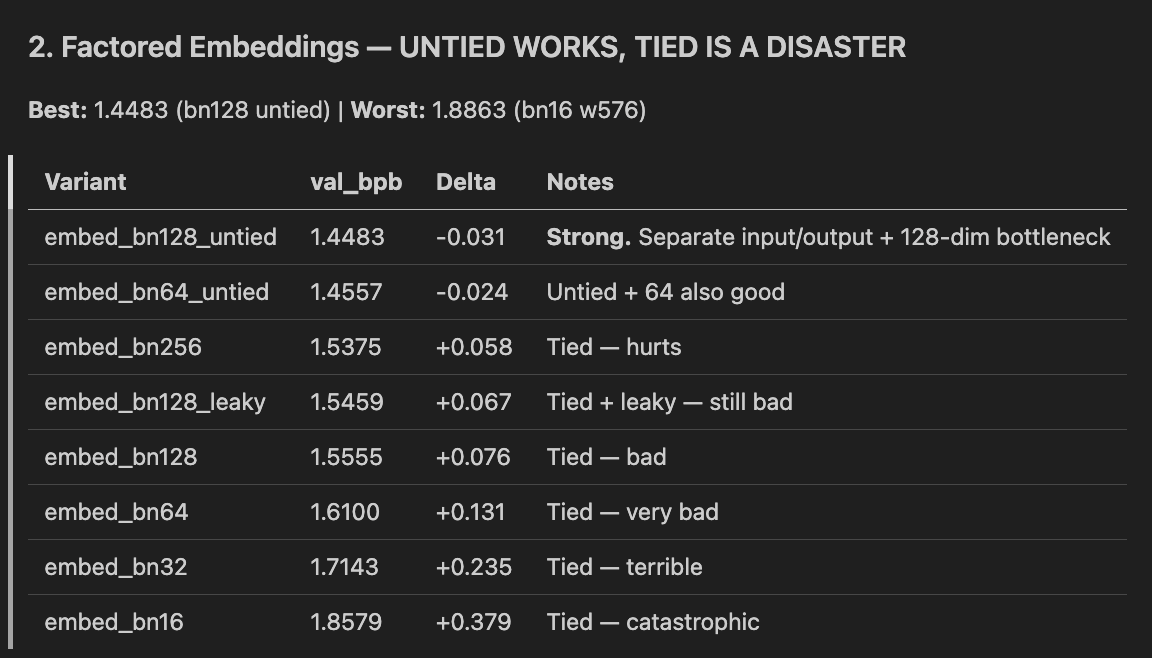
i did quick 71 experiments for 500 out of 13,000 steps for OpenAI's challenge
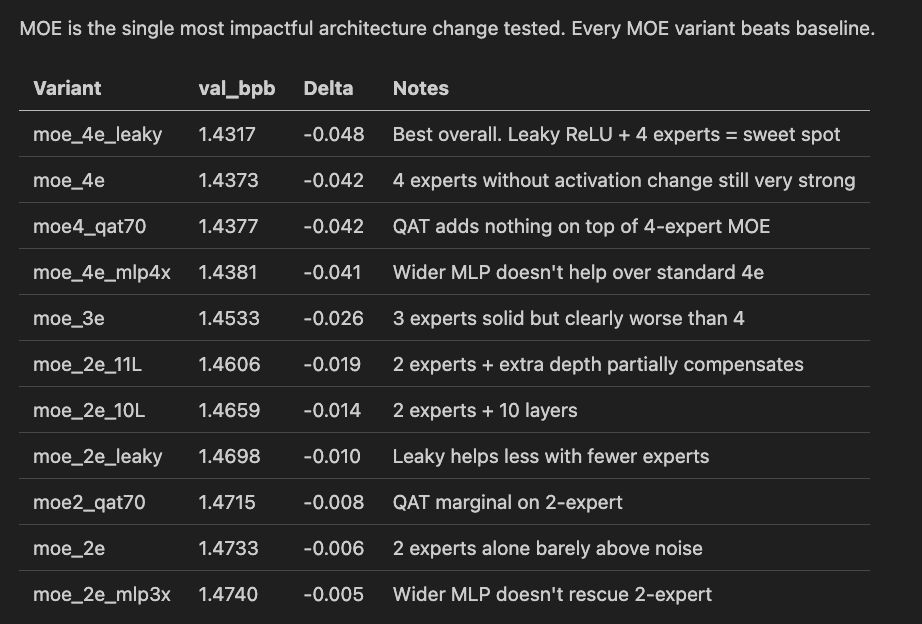
1. Mixture of Experts is absolute WINNER
(very surprising as it shouldn't be for small LLMs)
> Expert count matters most. 4 (best) > 3 >> 2.
2. UNTIED Embeddings work, tied are disaster
3. Depthwise Convolution - DEAD END
Insights:
1. 4-expert MOE + leaky ReLU -> -0.048 BPB, clear winner
2. Untied factored embeddings (bn128) -> -0.031 BPB, worth combining with MOE
3. MOE + QAT combo -> preserves quantized quality for submission
dead ends
1. Depthwise convolution -> every variant hurts, bigger kernels hurt more
2. Tied factored embeddings -> catastrophic, especially at small bottlenecks
3. Weight sharing -> not competitive with MOE for quality
4. Conv + anything combos — compounds the damage
Next Steps
1. Validate MOE 4e + leaky at 2000-5000 steps, multiple seeds
2. Test MOE 4e + leaky + untied bn128 — the two biggest wins may stack
3. Full run (13780 steps) of best combo to see if it beats 1.2244 BPB leaderboard
71 experiments, 3 GPUs, ~500 steps each. Vuk Rosić
500 step training mainly helps us eliminate VERY BAD losers, winners need to be tested on longer training.
Thank you @novita_labs for compute!
OpenAI@OpenAI
Are you up for a challenge? openai.com/parameter-golf
English
@HavenFeng Good point. It's one of the earliest world models in human history.
English

“World model” is such an overloaded term now. Seriously, until when will we start considering a terrestrial globe 🌍 as a world model?
It’s clearly about the world, has 3D consistency, and very persistent memory (no matter how many times you rotate it) 🤣
Xun Huang@xxunhuang
True. Static 3DGS is not a world model. A world model needs to understand action and reaction, cause and effet.
English
@maxencefrenette @YouJiacheng 😑 Isn't it the basics that LR should change with the batch size?
English

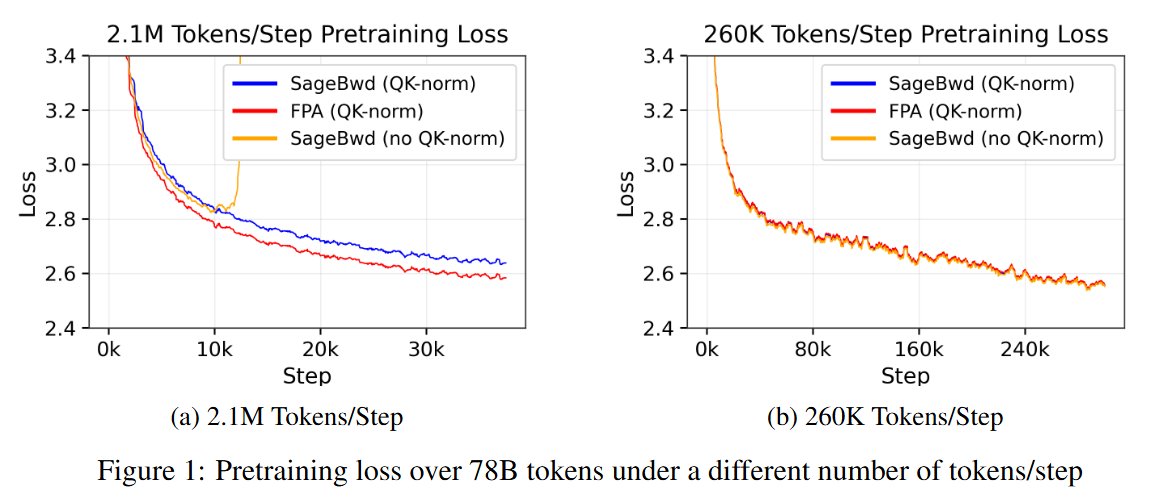
@YouJiacheng Ok i looked at the paper. Sounds like they use the same hparams including lr accross all runs. Not surprising that the tuned setting does better than the untuned setting at iso-tokens (which is also iso-flops in this case since it's the same model).

English

Interesting, large batch size will make quantized training worse.
English
@emollick This could totally be some hidden shortcut signals other than tastes
English

Evidence that AI models can, indeed, learn "taste" in this paper where a small model, trained on citations, is able to predict which papers will be hits
Citations, upvotes & shares are signals that can teach AI judgment about quality, not just execution. arxiv.org/pdf/2603.14473

English


@elliotchen100 原来如此,分的还挺细的,我看过shanda的一个position paper很强调memory和continual learning
中文

论文来了。名字叫 MSA,Memory Sparse Attention。
一句话说清楚它是什么:
让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。
过去的方案为什么不行?
RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。
线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。
MSA 的思路完全不同:
→ 不压缩,不外挂,而是让模型学会「挑重点看」
核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。
→ 模型知道「这段记忆来自哪、什么时候的」
用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。
→ 碎片化的信息也能串起来推理
Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。
结果呢?
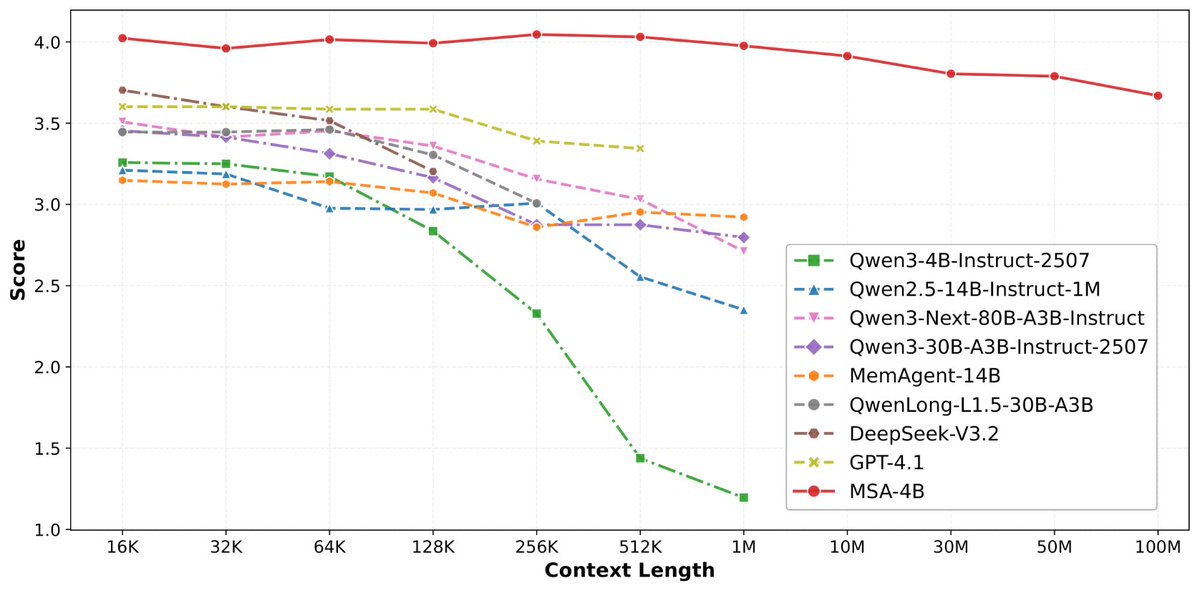
· 从 16K 扩到 1 亿 token,精度衰减不到 9%
· 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统
· 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。
说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。
我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏
github.com/EverMind-AI/MSA
艾略特@elliotchen100
稍微剧透一下,@EverMind 这周还会发一篇高质量论文
中文

这个相关机构需要做个全面的大检查了。
1. Windows的版本是已经是out of service的版本。
看着版本是Win 7
所以新的漏洞没人修,所以处于裸奔状态。知道win7之后有多少的安全漏洞被修复了吗? 你们这么用Windows 7,就是裸奔。
2. 机器上直接装向日葵远程控制软件。
装这个的人应该开除。所有人应该进行安全教学。
这个向日葵远程控制软件,是一个非常常见的远程控制协作软件。安全机制非常脆弱,动态口令保护。
而且向日葵一直有RCE。
装了这个软件,就相当于给你的网络开了一个巨大的后门。
3.这台机器是用来做地堡有限元分析的。
看几个软件是,用来设计地堡防钻地弹的。
妥妥的军事项目。
ps,这几个有限元计算的软件,应该都是盗版的。

中文


@hillbig "Typical MoE implementations require roughly 40 times as much data per total parameter as dense models" could you suggest a reference? Thanks
English

Pre-training of LLMs has once again become a major focus of attention. Although concerns about data scarcity are growing, pre-training itself continues to evolve. A key driver of this progress is the increasing use of synthetic data (see Tramel’s presentation at Berkeley, linked below).
Although post-training can improve performance, the upper bound of a model’s capabilities is generally believed to be determined during the pre-training phase. This is because pre-training is where fundamental representations and basic reasoning patterns are acquired, and these tend to change only marginally during post-training.
Looking at current scaling laws, the Chinchilla rule originally suggested that the optimal training data size is roughly 20 times the number of parameters. Recently, however, this ratio has increased to around 60 times the number of parameters. In addition, the emergence of Mixture-of-Experts (MoE) architectures has enabled increasing the total number of parameters without a proportional increase in inference compute.
This development further intensifies data requirements. Compared with dense models, MoE models require fewer data visits per parameter and are therefore more susceptible to overfitting. As a result, typical MoE implementations require roughly 40 times as much data per total parameter as dense models. For example, a 1T-parameter model may require on the order of 40T tokens.
Moreover, data diversity is critical. Simply repeating the same dataset multiple times does not meaningfully improve performance.
However, when model-generated synthetic data is used directly as training data, the overall data quality can deteriorate. This phenomenon—often referred to as mode collapse—reduces the diversity present in the long tail of the data distribution and leads to more monotonous model outputs.
One effective mitigation strategy is to mix real data and synthetic data during training. In addition, instead of fully regenerating data, it is often preferable to generate paraphrases of existing data. By synthesizing alternative expressions that preserve the original data's factual content, it is possible to improve training efficiency while maintaining data diversity.
Importantly, the models used for paraphrasing do not necessarily need to be powerful; relatively small or weak models can be sufficient. This approach follows the same fundamental principle as data augmentation in computer vision. By observing the same information expressed in many different forms, the model learns representations that are independent of specific surface expressions while simultaneously learning the mapping between expressions and internal semantic representations.
Recently, two types of synthetic data have emerged as particularly important.
The first is program code. Code can be verified by execution, enabling automatic correctness checks and the generation of highly reliable training data. Beyond improving programming ability, code data appears to help models acquire broader representations and reasoning capabilities.
The second is data containing explicit reasoning processes. If such reasoning traces are incorporated during pre-training rather than only during post-training, models may learn reasoning procedures—essentially, certain classes of algorithms—during pre-training itself.
In real-world data, explicit reasoning processes are often absent; texts rarely include detailed explanations of why particular outcomes occur. To address this, one promising approach is to generate multiple reasoning trajectories with inexpensive, weaker models, then verify and filter them with stronger models. This pipeline can produce high-quality reasoning data suitable for inclusion in the pre-training corpus.
In this sense, synthetic data acts as an amplifier of real-world data. Because human-generated data is fundamentally limited, synthetic data will likely play an increasingly central role in future large-scale model training.
English