
@trends_stores @digvijayborkar This number is coming busy, constantly
English
MindzKonnected
690 posts

@MindzKonnected
Building Agentic AI systems that act, decide, and deliver — smarter business, verified results. #AI #GenAI #RAG #AgenticAI


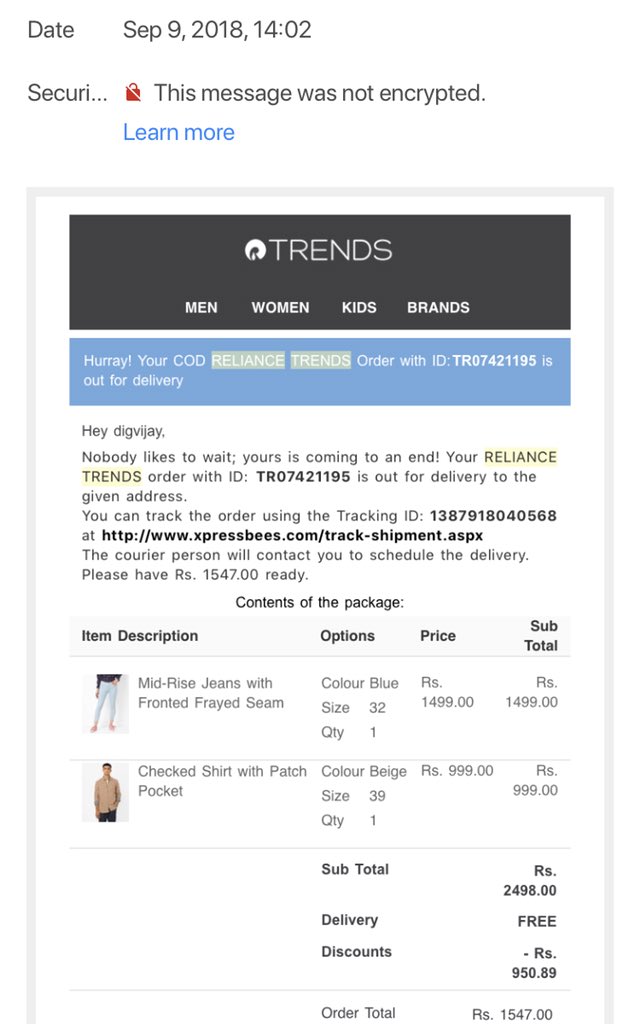




















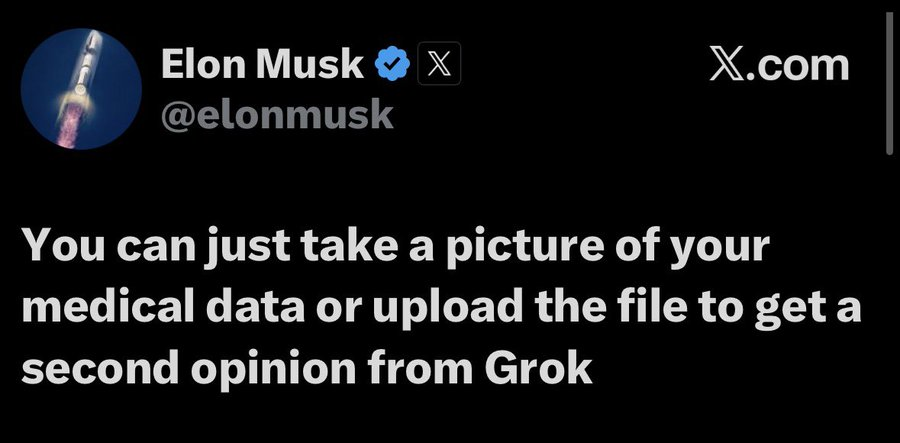

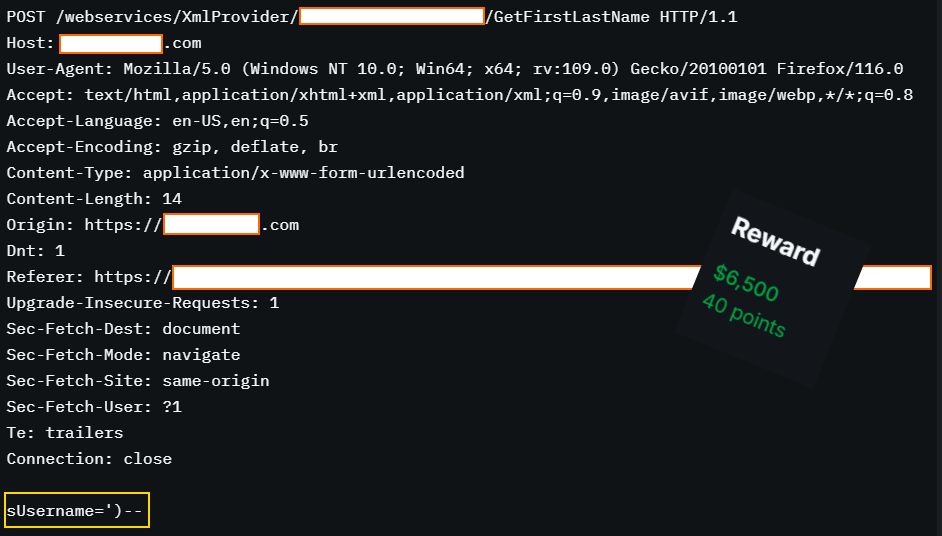

Data is a new way of conning the public.


“AI wiLL RePlAcE eVeRy WhItE cOllAr JoB”




