
English
Monadic DNA
265 posts

@MonadicDNA
DNA insights with privacy, autonomy, and boundless curiosity.



We just launched full genome sequencing for $599. Not a panel. Not a fraction. All 3 billion base pairs. 30× coverage. This changes what “DNA testing” actually means. 🧵

57% of enterprise employees admit to entering confidential company data into public AI tools. That includes internal documents and business information. AI is already being used in sensitive environments.

Microsoft just solved the context window problem. Right now, every AI suffers from a fatal flaw: the "context window problem." When an AI reasons through a complex problem, it generates a massive chain-of-thought. But there is a catch. It has to keep every single token of that thought in its active memory. The technical term is the "KV Cache." The longer the AI thinks, the heavier it gets. It slows down. It gets expensive. Eventually, it runs out of space. We thought the only fix was renting bigger, more expensive cloud GPUs to hold all that context. Microsoft just proved us wrong. They published a paper called "MEMENTO." Instead of giving the AI a bigger memory, they taught it how to forget. Here is how it works: Instead of generating one endless stream of consciousness, a Memento-trained model breaks its reasoning into small blocks. After it finishes a block, it writes a dense, highly compressed summary of its own logic—a "memento." Then, it does something unprecedented. It physically deletes the entire previous reasoning block from its memory cache. It only carries the memento forward. The model reasons, extracts the core logic, and instantly drops the dead weight. The results rewrite the economics of running AI. • Context length compressed by 6x. • Active memory usage (KV cache) reduced by 2.5x. • Zero loss in math, science, or coding accuracy. And here is the real implication. Big tech has been charging you by the token for massive context windows you don't actually need. With this architecture, small businesses and solo operators can run complex, multi-step autonomous agents entirely locally. You don't need an enterprise cloud setup. A standard machine running an open-source model can now reason indefinitely without overflowing its memory. No API fees. Complete privacy. We spent the last two years trying to give AI an infinite memory. It turns out, the secret to smarter AI isn't remembering everything. It's knowing exactly what to forget.

I’ve wanted to do this for a decade. But I never did - I refuse to give any company my DNA. It is me. So this week I sequenced my genome entirely at home. Literally on my kitchen table. I never exposed my DNA sequence to the internet. Not at any point. I used a MinION to do the sequencing (it’s smaller + weighs less than an iPhone). I used open-source DNA models for the analysis (Evo2 and AlphaGenome) running locally on a DGX Spark and Mac Studio. I traced mechanisms behind my family’s multigenerational autoimmune conditions that no clinician has been able to understand. When I set out to do this I didn’t know if it would actually work. It does. Your genome is the most private data you will ever have. You probably shouldn’t let it leave your house.
Human genome sequencing: 2003: $3,000,000,000 global effort years of research 2026: your kitchen table a few hundred $ Hard not to be excited for the future. iwantosequencemygenomeathome.com iwantosequencemygenomeathome.com
I’ve wanted to do this for a decade. But I never did - I refuse to give any company my DNA. It is me. So this week I sequenced my genome entirely at home. Literally on my kitchen table. I never exposed my DNA sequence to the internet. Not at any point. I used a MinION to do the sequencing (it’s smaller + weighs less than an iPhone). I used open-source DNA models for the analysis (Evo2 and AlphaGenome) running locally on a DGX Spark and Mac Studio. I traced mechanisms behind my family’s multigenerational autoimmune conditions that no clinician has been able to understand. When I set out to do this I didn’t know if it would actually work. It does. Your genome is the most private data you will ever have. You probably shouldn’t let it leave your house.
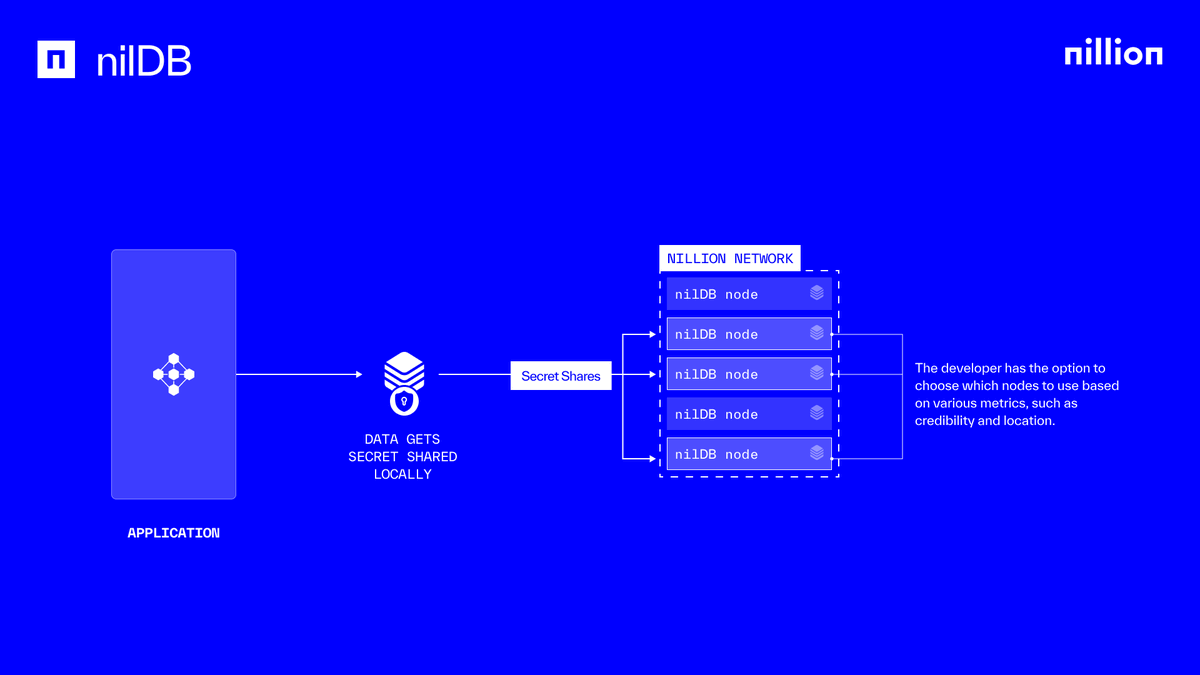
The Vercel breach put the problem in plain sight. Too many systems still keep sensitive logic and data stored in one place. nilDB exists to break that pattern. - Sensitive data is split before it is stored - It is distributed across multiple nilDB nodes - No single node holds the complete secret - No single breach reveals the whole dataset That’s why Nillion matters: it gives builders a privacy layer for sensitive data.


I'm lucky enough to have a great doctor and access to excellent Bay Area medical care. I've taken lots of standard screening tests over the years and have tried lots of "health tech" devices and tools. With all this said, by far the most useful preventative medical advice that I've ever received has come from unleashing coding agents on my genome, having them investigate my specific mutations, and having them recommend specific follow-on tests and treatments. Population averages are population averages, but we ourselves are not averages. For example, it turns out that I probably have a 30x(!) higher-than-average predisposition to melanoma. Fortunately, there are both specific supplements that help counteract the particular mutations I have, and of course I can significantly dial up my screening frequency. So, this is very useful to know. I don't know exactly how much the analysis cost, but probably less than $100. Sequencing my genome cost a few hundred dollars. (One often sees papers and articles claiming that models aren't very good at medical reasoning. These analyses are usually based on employing several-year-old models, which is a kind of ludicrous malpractice. It is true that you still have to carefully monitor the agents' reasoning, and they do on occasion jump to conclusions or skip steps, requiring some nudging and re-steering. But, overall, they are almost literally infinitely better for this kind of work than what one can otherwise obtain today.) There are still lots of questions about how this will diffuse and get adopted, but it seems very clear that medical practice is about to improve enormously. Exciting times!



🚨NEW FDA Draft Guidance Safety Assessment of Genome Editing in Human Gene Therapy Products Using Next-Generation Sequencing #FDA #Regulatory #geneediting #genetherapy Top 5 Takeaways - 1) NGS becomes the regulatory backbone for genome editing safety 2) FDA expects a layered, redundant approach to off-target assessment 3) Low-frequency events matter and must be detectable 4) Patient genetics is now explicitly part of risk assessment 5) Genome integrity (translocations) is no longer optional for DSB-based gene editing systems fda.gov/regulatory-inf…

