Sabitlenmiş Tweet

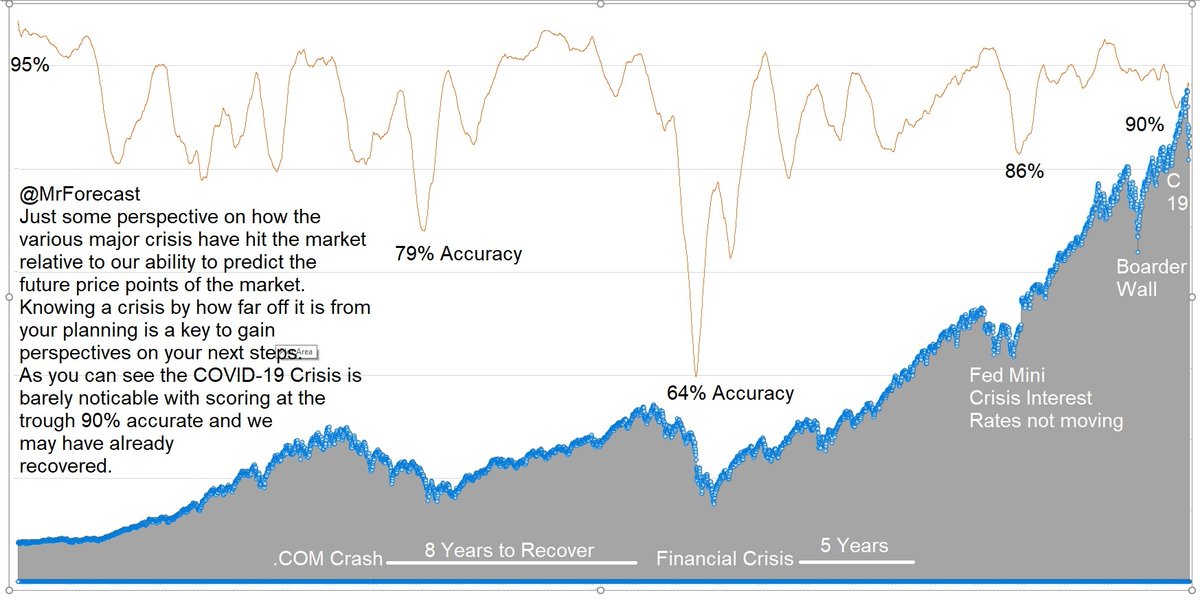
@dave7846 Understanding how the market behaves against a forecast let's you know how far of reality is from fear. #MathMatters
English
Mr. Forecast
16.8K posts
@MrForcast
Desperately Seeking Alpha? Sim: 33% CAGR • Alpha ~25% • -22.6% DD | Trading now.


















