@xikhar @thsottiaux well if it auto applies the second it expires we wouldn't even need to check, also I think they all have the same expiry time which is OpenAI server time no?
English
Nour Eddine Hamaidi
2.4K posts




🆕LoL Classic mode isn't just nostalgia. Coding agents proving that many "we had to change it" , What used to be too expensive to keep alive is suddenly becoming feasible again. Which game's old version do you want coding agents to resurrect next? 🤔




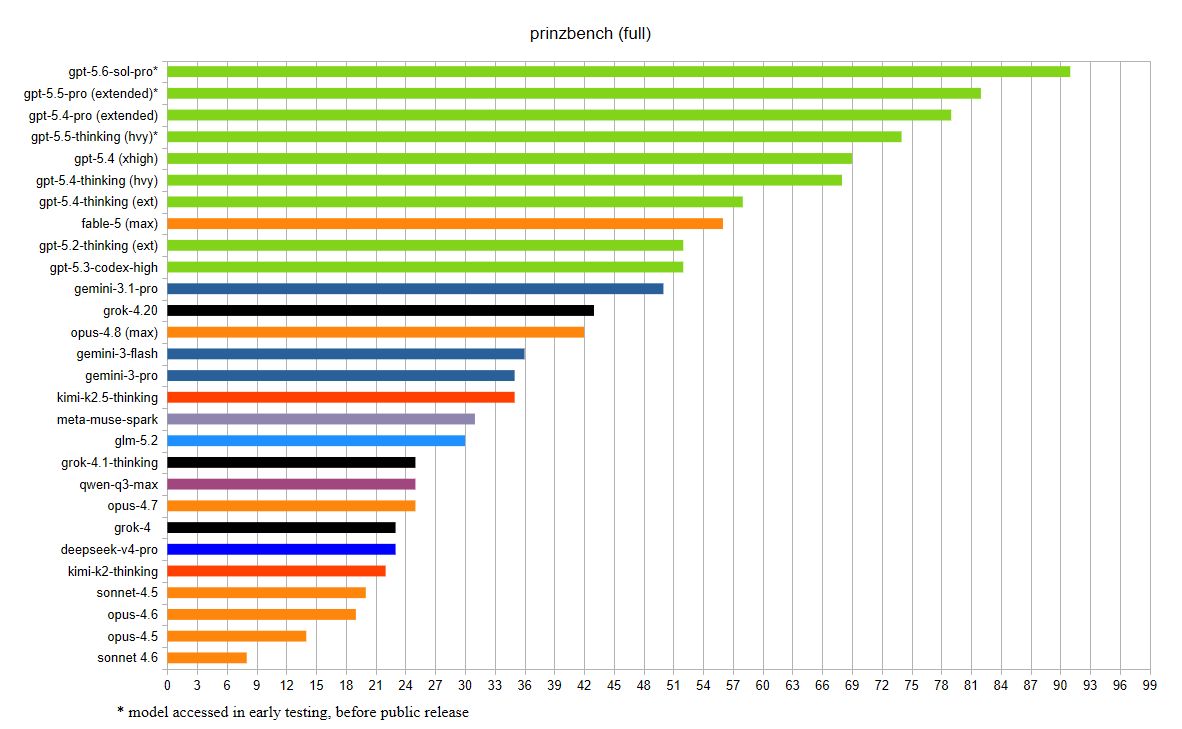
GPT-5.6 Sol confirmed to be an extremely good model