Sabitlenmiş Tweet

you know, we keep talking about how ai needs more representation for low-resource languages. but kashmiri, with all that incredible literature, centuries of history, was pretty much invisible to modern ocr systems.
it bothered us. so we decided to stop talking about it and build something.
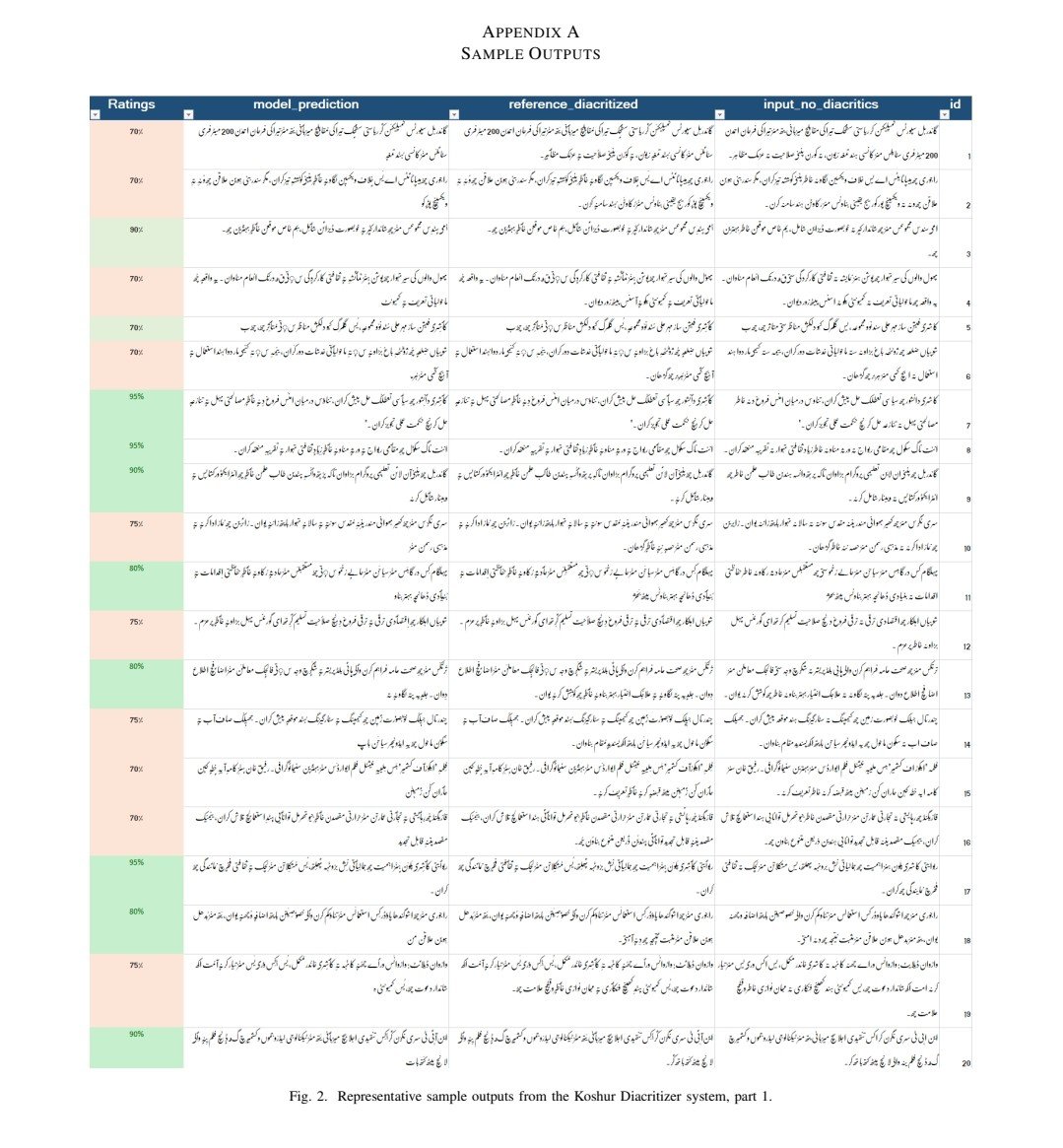
today, we're open-sourcing koshur pixel. it’s the largest synthetic ocr dataset for the kashmiri language: 613,000 image-text pairs covering words, sentences, even whole pages.
really grateful to @Haq_Nawaz_Malik and @FaizanIqbal__52. couldn't have done this without them.
paper: arxiv.org/abs/2606.23144
dataset: huggingface.co/datasets/Omarr…




English