Fabio Biola retweetledi

Ron Weasley yelling “Expensive Petroleum” while filling up his car might be the peak of comedy 🤣
English
Fabio Biola
549 posts

@NeoKree
Mobile & Full stack developer. Investor & crypto enthusiast




No double jumps, no hand-holding, just pure, methodical platforming in a gorgeous sci-fi world. 🌙 My love letter to the cinematic platformer of the 90s #LUNARK is $3.99, its lowest price ever (80% OFF!). (Check this out @Wario64 😘!) #LinkBelow #SteamSpringSale #PleaseRT








is anyone on here tech savvy enough to know my my camera is doing this as of 12 hours ago


Doesn't seem like anyone knows what this is for, right?

> 385ms average tool selection. > 67 tools across 13 MCP servers. > 14.5GB memory footprint. > Zero network calls. LocalCowork is an AI agent that runs on a MacBook. Open source. 🧵

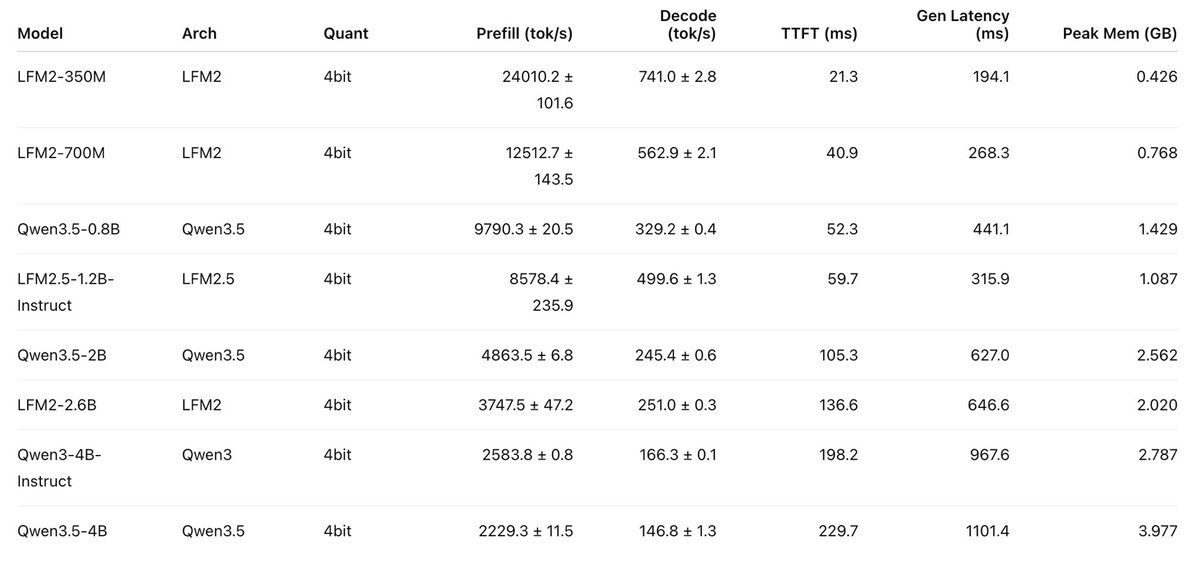
🚀 Introducing the Qwen 3.5 Small Model Series Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B ✨ More intelligence, less compute. These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL: • 0.8B / 2B → tiny, fast, great for edge device • 4B → a surprisingly strong multimodal base for lightweight agents • 9B → compact, but already closing the gap with much larger models And yes — we’re also releasing the Base models as well. We hope this better supports research, experimentation, and real-world industrial innovation. Hugging Face: huggingface.co/collections/Qw… ModelScope: modelscope.cn/collections/Qw…

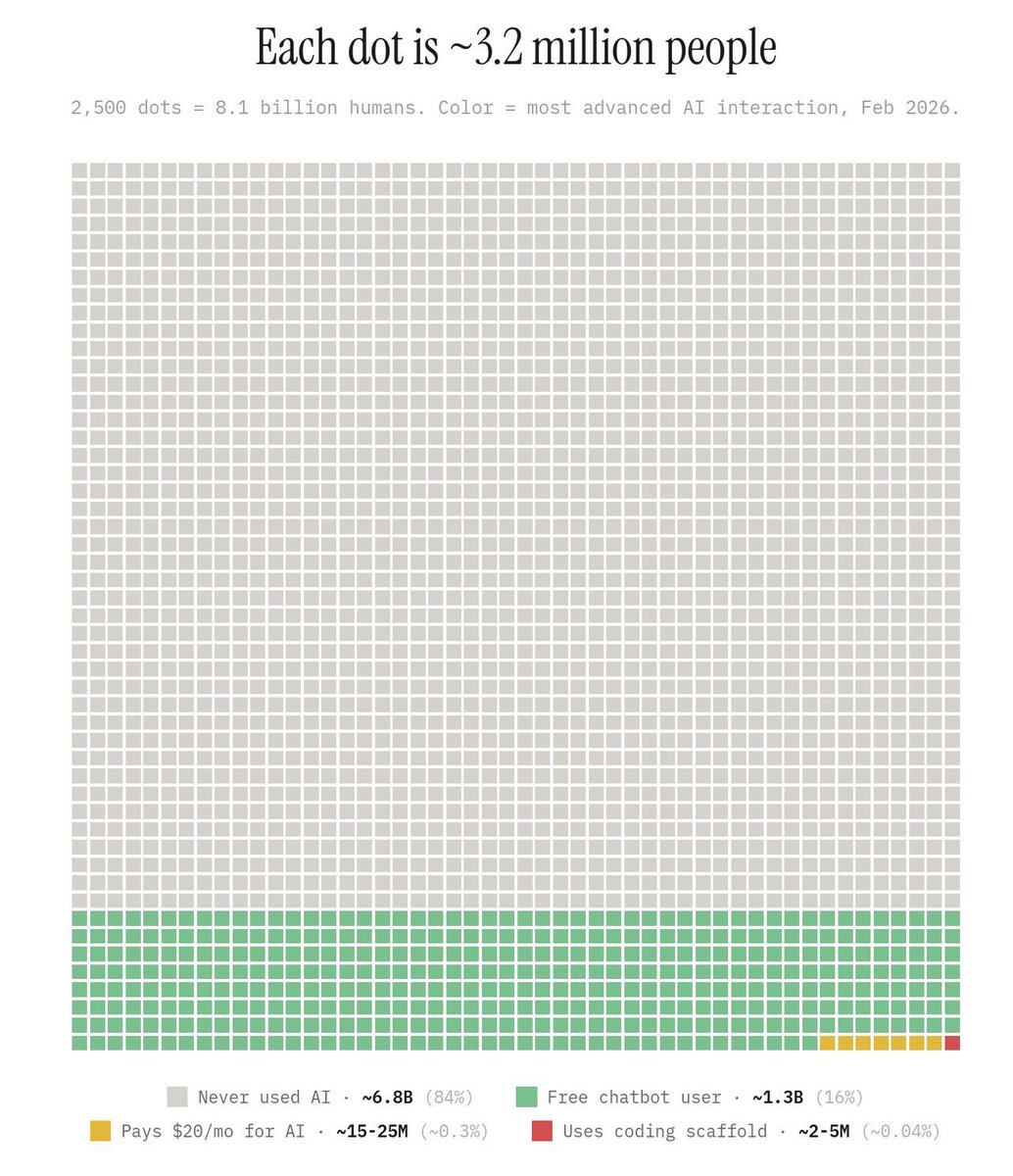
84% of people have never used AI, and just 0.3% of users pay for premium services. Anyone who thinks AI is a bubble isn't paying attention.


Today, we release our largest LFM2 model: LFM2-24B-A2B 🐘 > 24B total parameters > 2.3B active per token > Built on our hybrid, hardware-aware LFM2 architecture It combines LFM2’s fast, memory-efficient design with a Mixture of Experts setup, so only 2.3B parameters activate each run. The result: best-in-class efficiency, fast edge inference, and predictable log-linear scaling all in a 32GB, 2B-active MoE footprint. 🧵