Sabitlenmiş Tweet

Manjari Narayan
10.2K posts

@NeuroStats
Surrogate Science , Auditing AIxBio, AI epistemics. Prev @Dyno_Tx | @StanfordMed | PhD@RiceU_ECE | BS@ECEILLINOIS Feedback: https://t.co/wR1ooEvxzP

Claude Codecrastination: when you avoid the thing you're supposed to do by cranking out 17 other things you've been wanting to do for a while.



It's so great that there are now multiple orgs doing transparent, rigorous testing of basic premises about how LLMs work and how their behavior can be influenced. So glad that Geodesic exists and excited to work with them on more like this!
I found myself similarly disoriented. I suspect we haven't found new abstractions that actually make sense for theory to be cool again. But you have to develop a taste for different research problems.
🌶️ Some (perhaps) spicy thoughts. It’s been a while since my last tweet, but I wanted to write about how disorienting it has been from academia to an LLM lab 😅 The kind of research I was trained to do during my PhD almost doesn’t exist here. The obsession with mathematical elegance and novelty is mostly gone. Everything is about scaling data and compute. For a while, that really got to me. At my lowest point, I felt like I’d lost interest in building LLMs altogether. I didn’t feel intellectually challenged anymore. What made this even stranger was that, at a technical level, things worked. If there was a capability I wanted to teach a model, scaling the right data and compute always got me there, no exception (so far). But recently, I found a way to reconcile with myself.. I realized the real competition isn’t in the ML recipe anymore. Most teams do roughly the same thing. What actually matters is how fast you can iterate, test ideas, and recover from mistakes. And that speed is mostly backed by infrastructure 🏗️ Faster loops, fewer bugs, better tooling. Seeing this made me excited again! Infra is its own deep, hard, and intellectually fun problem space. In 2026, I want to become an ML researcher who’s really good at infra. And I'll come back to ML problems with that edge, and will be excited to share what I find 😌

7/7 This work is supported by the Good Science Project (thanks to @stuartbuck1), with encouragement from @aishdoingthings and @analoguegroup. Best way to reach me: reply, DM, or email vansh@mit.edu with 2 lines on your background and your city.



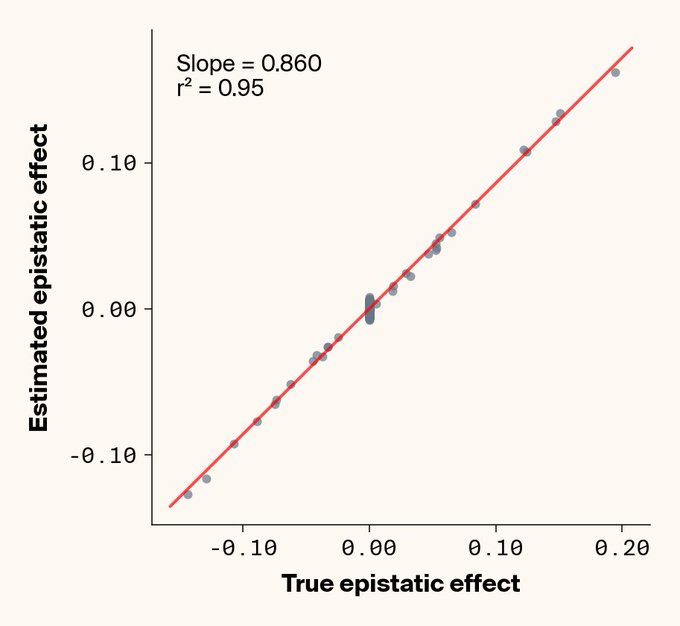

@AnthropicAI @Google The recent very welcome @Arcinstute challenge made this painfully clear: defining evaluation metrics is hard. In some cases, trivial data transformations—and even random data—can score astonishingly high. Great AI performance ≠ biological meaning. 4/6


@anshulkundaje I was just making that point in a 3-tweet thread here. In addition to my closing suggestions there, I would mention the need for life course molecular (omics) epidemiology - high powered.
@ltrd_ You also don’t need to be a gold medalist of the IMO to be a great mathematician. He isn’t drawing a contrast between smart and stupid. It’s a contrast between shallow and deep thinking.