
NftPillQueen 🍭
2.7K posts


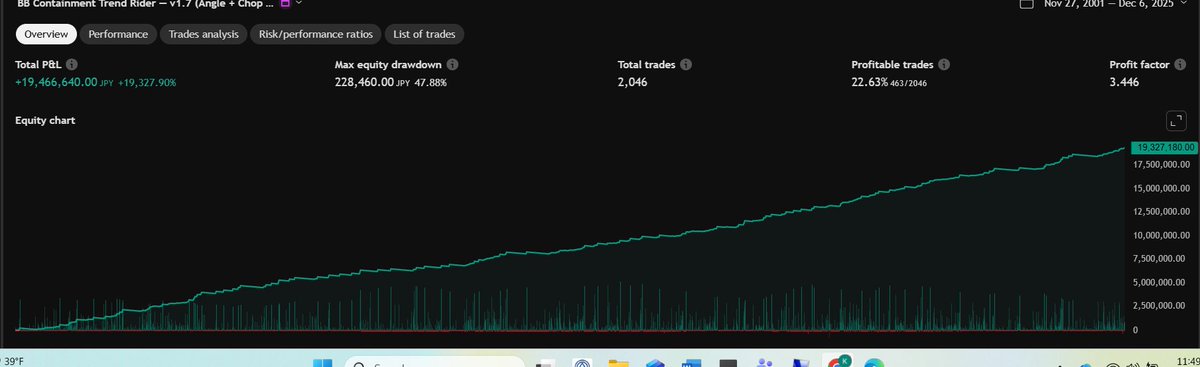
I just want to say in less than 3 months of hard work developing indicators and strats. I currently have 4 rock solid plans I will rollout next year. Works well with 28 currency pairs that I tested so far. Thank you AI for helping me do something that took me 5 years and even better.
English
NftPillQueen 🍭 retweetledi

🇧🇷 Together with the $DOG Community, we build, grow & share the rewards! 🐶✨
📅 Aug 28 – Sep 5
🎁 Join now & claim your share of the prize pool!
🔥 Multiple ways to participate, get a chance to win 1,200 USDT airdrop!
🔗 Check out the pinned post on @mqmcrypto and join! 🤝
Powered by $DOG Community
Don’t miss this limited-time campaign — grow with the community & win big! 🚀

English
NftPillQueen 🍭 retweetledi

Dork isn’t a genius, a guru, or a billionaire.
He’s just a common guy — pissed off, emotional, and painfully real.
He’s got only one true friend, and would die for him. Everyone else? They need to earn his respect.
Dork is unemployed. He works whatever scraps he can find just to make it through the day. He’s not rich, he’s not flashy, and he’s sick of proving himself to anyone.
If you don’t like him? He’ll show you exactly where to kiss him.
Dork doesn’t push you to do anything. He doesn’t chase clout.
He’s raw honesty — no shame, no mask.
Dork is one of us.
A rebel. Standing his ground. Following his own path.
A meme with a personality — one you can relate to, and one you secretly wish you had the guts to be.

English
$BOBOO on TON 27K MC
Next $UTYA
EQCthWPYR9YmeQMeSRXe56YSiUfuP3mYsyV42wkKTN1XKC1v
Suomi
NftPillQueen 🍭 retweetledi

$ZANO I think we are about to see new ATH's soon👑
Coming soon:
- Consensus upgrade
- UI and UX Update for Zano Trade
- Anonymous voting for ZANO holders.
- Website for the auctioning of Zano aliases.
- Introduction of a grants program to support and fund community-approved projects and innovations within the Zano ecosystem.
Their ecosystem is growing exponentially✈️
English
NftPillQueen 🍭 retweetledi

We've recently been posting $ZANO analyses and as its prices continues to surge and near all time highs, let's dive in to what Zano actually is!
True Privacy In Crypto, we introduce @zano_project.
A Thread 🧵⤵️

English
I'm loving it!! Love my MEMES!
Check out $DORK
Under 300k mc and going 💪 EQBbIiA9g8eohAbE9-gCCjlAqz3_i5EyvCW0daegABESATqU
CITADEL WOLF ⛰️🐺🥷@citadelwolff
TON memes
English
@TraderCoachK1 @PromeOnTon I'm one of those that held and held 🥰
I'm ecstatic 🤗
English

Remember that core group of $wif holders that held, and held, and held wif to billions?
Well, looks like many of them are now jumping on the $ton token @PromeOnTon
They also had a tweet liked by the official $UTYA Twitter
Prob nothing.
EQB8ihuOwWWFDBoQ6JFgZHLRByt7VshDlzklpHF5NKs9a3QT

English
NftPillQueen 🍭 retweetledi

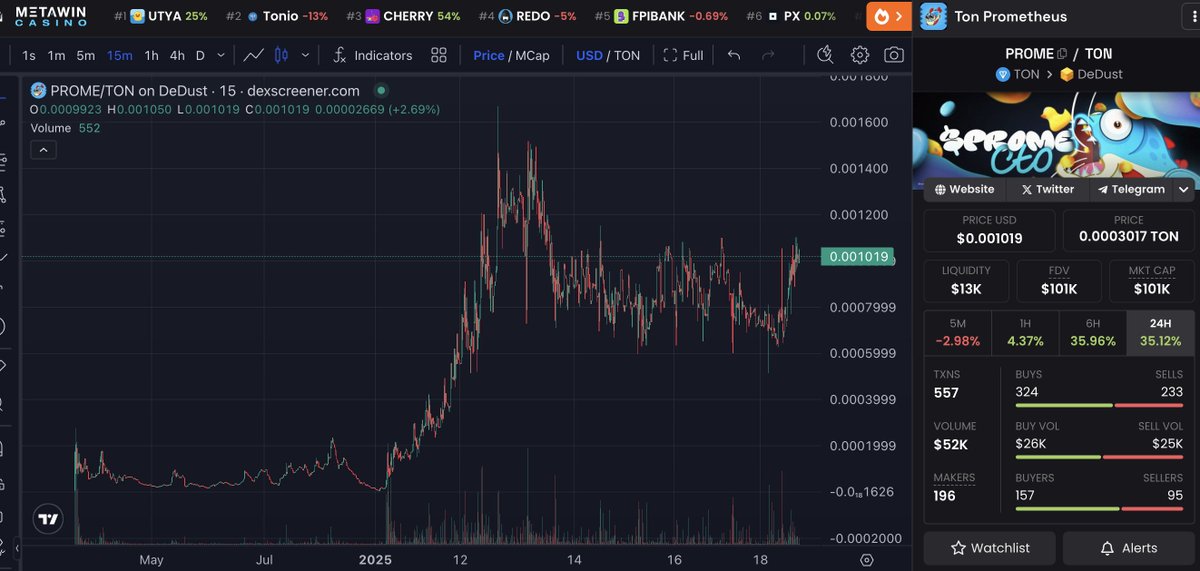
$PROME chart is a thing of of beauty! Don't get caught sleeping when @PromeOnTon sends to millys 🔥 🐟🐟🐟
EQB8ihuOwWWFDBoQ6JFgZHLRByt7VshDlzklpHF5NKs9a3QT
English
NftPillQueen 🍭 retweetledi


okay, free Nubcat!
we’re giving away $25 of $nub every day until the @nubcat account is back
just drop your SOL addy and the fun will start on Friday

MoonPay 🟣@moonpay
FREE @NUBCAT
English
NftPillQueen 🍭 retweetledi

Official Links - $PROME
Telegram: t.me/PrometheusTon
Sticker Pack: t.me/addstickers/Fi…
Website: promeonton.com
CA: EQB8ihuOwWWFDBoQ6JFgZHLRByt7VshDlzklpHF5NKs9a3QT
Chart: geckoterminal.com/ton/pools/EQCx…
X: x.com/promeonton
Comm: x.com/i/communities/…
Narrative: Prometheus, or Prome, is an adorable animated fish character, conceptualized by the Russian artist Alexander Dolnikov. Prome is consistently one of Telegram's most popular sticker packs, with tens of millions of stickers being sent.
He is also featured on the very FRONT PAGE of telegram.org

English
NftPillQueen 🍭 retweetledi
Congrats to @HotCherryTG, $CHERRY on obtaining the market cap of 1 million.
We love supporting the @telegram sticker communities.
Keep pressing forward! We can’t wait till we obtain this remarkable achievement
$PROME
EQB8ihuOwWWFDBoQ6JFgZHLRByt7VshDlzklpHF5NKs9a3QT

English
NftPillQueen 🍭 retweetledi
We are excited to be here and welcome you to check out our project.
Official Links - $PROME
Telegram: t.me/PrometheusTon
Sticker Pack: t.me/addstickers/Fi…
Website: promeonton.com
CA: EQB8ihuOwWWFDBoQ6JFgZHLRByt7VshDlzklpHF5NKs9a3QT
Chart: geckoterminal.com/ton/pools/EQCx…
X: x.com/promeonton
Comm: x.com/i/communities/…
Narrative: Prometheus, or Prome, is an adorable animated fish character, conceptualized by the Russian artist Alexander Dolnikov. Prome is consistently one of Telegram's most popular sticker packs, with tens of millions of stickers being sent.
He is also featured on the very FRONT PAGE of telegram.org
$UTYA has interacted with one of our tweets (they liked it)
English
NftPillQueen 🍭 retweetledi
If you go to telegram.org on PC, Prometheus is one of the FIRST THINGS you see! $PROME on $TON.
$UTYA $CHERRY $TONIO $REDO
EQB8ihuOwWWFDBoQ6JFgZHLRByt7VshDlzklpHF5NKs9a3QT

English
NftPillQueen 🍭 retweetledi


NftPillQueen 🍭 retweetledi

NftPillQueen 🍭 retweetledi

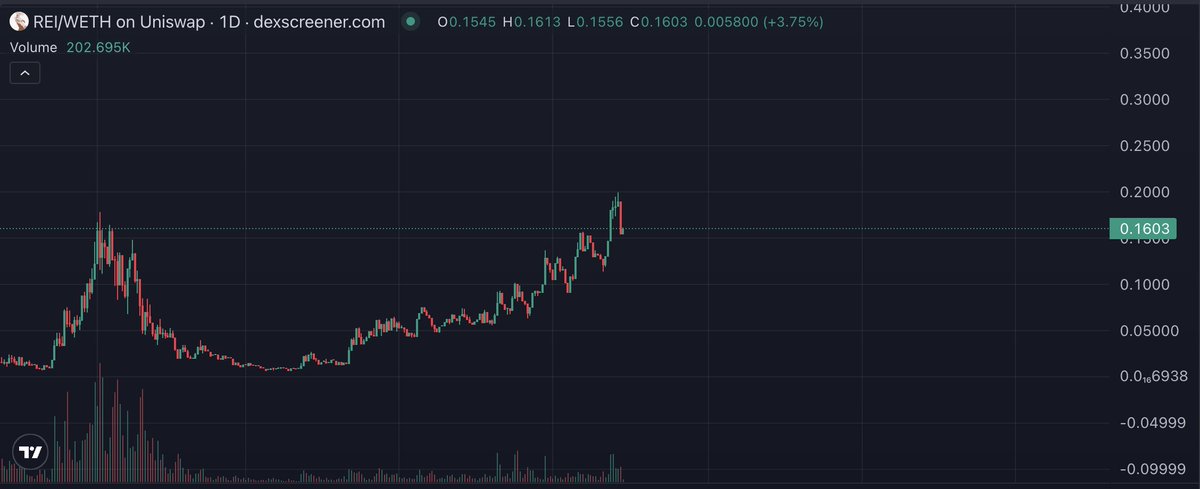
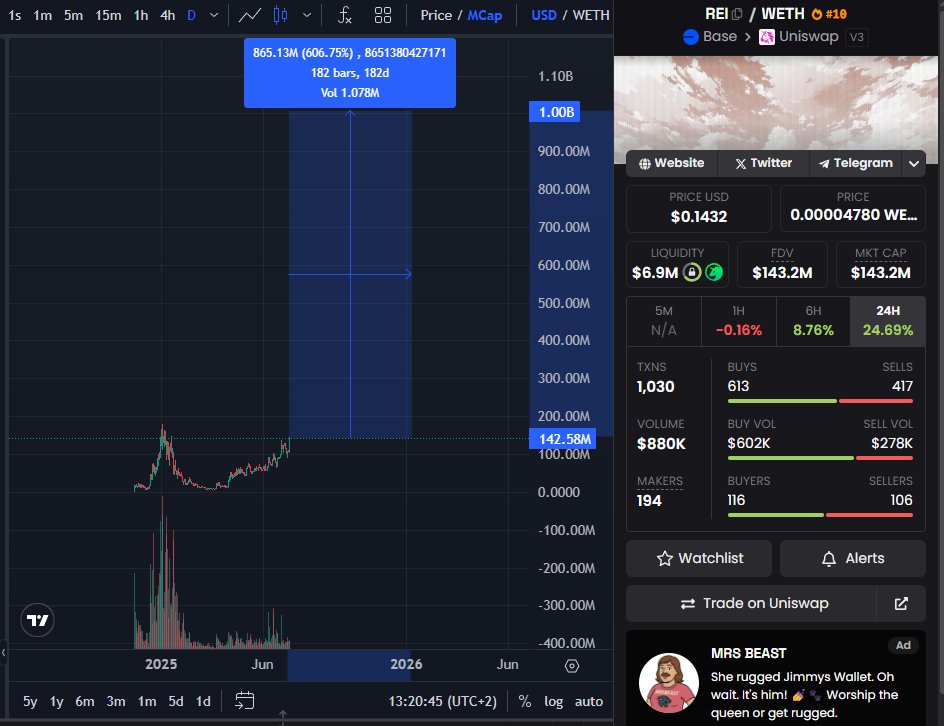
If you missed the recent pump of $REI :
This is your time to load up
One of the best looking charts
1B is coded
English
NftPillQueen 🍭 retweetledi

when tier-1 research start paying attention to your 140M mcap AI lab, you know something's cooking. 🔥🔥
@Delphi_Digital just featured $REI in their AI Frameworks report.
"REI Network: A Bet on Cognition"
most people won't read the report. most people won't understand the implications.
most people will buy $REI at $1 instead of $0.14.
Plata@platacrypto
No one is ready for Rei Core 0.3. It will start to change the way we view the use of large language models altogether. @ReiNetwork0x is a beast in the making. As many of you know, Rei is taking a novel approach when it comes to the use of LLMs and how we should interact with them. Today, we simply assume LLMs can't be trusted and that we must verify each bit of data to confirm their output. While we treat LLMs as 'human', it's just predicting which words need to be put after the first and providing an answer; there is no 'thinking'. This is unacceptable if we want LLMs and AI to play a larger role in our lives, as it has started doing for so many of us. We need to give LLMs both cognition and the ability to remember. There is still a debate on how to approach these issues, but I believe the more we mimic biology, the better the output. We should strive for an agentic system, specialized agents working together in harmony. Rei shares this vision and built their bowtie, which changes how queries are approached compared to models like ChatGPT, for example. Rei is already showcasing its reasoning skills and has proven to be a strong competitor with their Core model. Since its inception, Rei Core has proven to work as intended, being able to tackle many standard tests and closely compete with models 10-12 times larger than itself while scoring within the same range of ChatGPT. We will need to see an updated benchmark test for Core 0.3 and see how much better it has gotten, but it's safe to say we'll see some major improvement, most notably in the reasoning tasks, which make up 3/5 of the test. Besides reasoning, memory is a core aspect of building a proper language model. Without it, models tend to hallucinate, and conversations become less reliable with every query you send. In order for a model to think, it must be able to remember. Core 0.3 will allow units to gain access to their own memory structure, also known as metacognition, which will also allow us to do the same. This gives us real-time insights into which components of Core are working on your query, and means we can go far more in-depth to verify where an output came from. We can view this using hypergraphs, making things more visually sensible, which is a great addition for us to better understand how Core operates and which components are more active when handling a specific query. Core 0.3 is a huge improvement compared to the LLMs we've experienced so far, and it will show. There is still a long way to go, but Rei is making fast moves that allow them to compete with the strongest models we know on a far more efficient scale when it comes to cost and compute. All the while, funds are taking a keen interest, and Core is being used for Ecliptica with a clear revenue model in place. Name one project with a market cap of around $115M that has numerous advantages, continuously ships, and is already developing a real-world use case. At some point, Rei isn't a beast in the making; it becomes one. $REI remains one of my top conviction investments, and I see it as one of the easiest picks this cycle. $1B is much closer than you think. I hope you enjoyed this post 🫡 These posts take a long time, so I'd appreciate it if you could like and retweet it.
English
NftPillQueen 🍭 retweetledi

Most won’t do the work.
They chase noise.
But edge comes from studying fundamentals,
reading onchain flows,
and taking risk.
The market rewards those who see early and trust their edge,
especially when no one else does.
That’s how you catch the next billion-dollar run.
$REI
Cryptor ⚡️@cryptorinweb3
My $REI journey: From $10M to over $135M by digging into fundamentals, tracking product-market fit, and following smart money using @nansen_ai ⸻ On June 23, I shared a post about $REI (see QRT) that ended up going viral with over 32k views. Honestly, I was a bit surprised. Especially because I don’t have a large following, and $REI isn’t exactly a mainstream name yet in the web3 trenches. There’s barely any (big) KOL coverage, and their main X account still sits at 12K followers. In that post, I shared my insights and findings on $REI and judging by the response, it seems people still appreciate real research and clear reasoning. So in this post, I want to walk you through how I managed my $REI position and the steps I took that made it become my third-largest portfolio position as of today, right after $TAO and $BTC. For the record, I’m not here to flex a 13x return (though I won’t complain). What really excites me is that I followed a process built through 8 years of experience, trial, and error (and many dollars lost) that actually worked. And I didn’t do it alone. I use a bunch of tools, but if I had to pick just one, it would be Nansen. Nansen is by far one of the best analytics platforms out there. It’s not cheap, but it’s worth every dollar. Without it, I wouldn’t have made this call as confidently or as early. If you’re curious to try it yourself, there’s a 10% discount link below in this thread. Let’s dive in 👇🧵
English