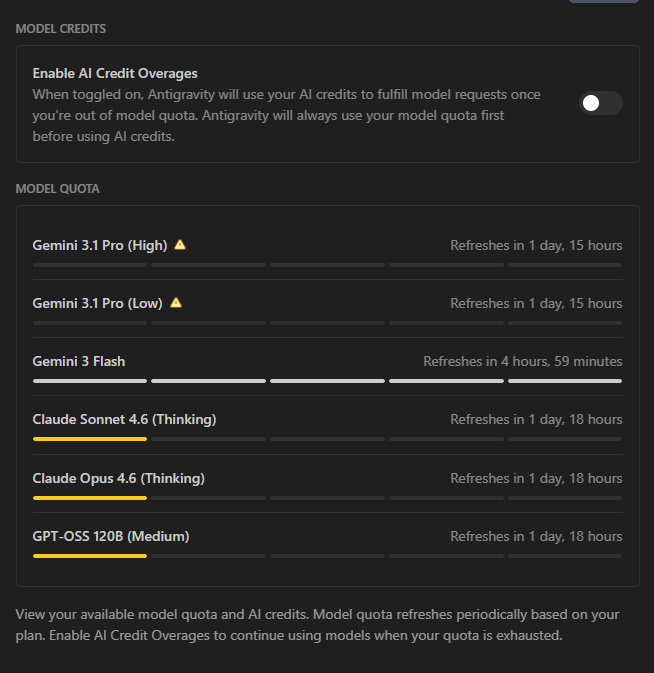
Comparing Llama.cpp v8184 against v8287 across the Qwen 3.5 family reveals massive token generation speed improvements.
The fewer active parameters a model has, the larger the performance jump:
0.8B: +31%
4B: +20.5%
9B: +14%
27B: +10.5%
35B-A3B (MoE): +23.5%
English