Noam Elata retweetledi

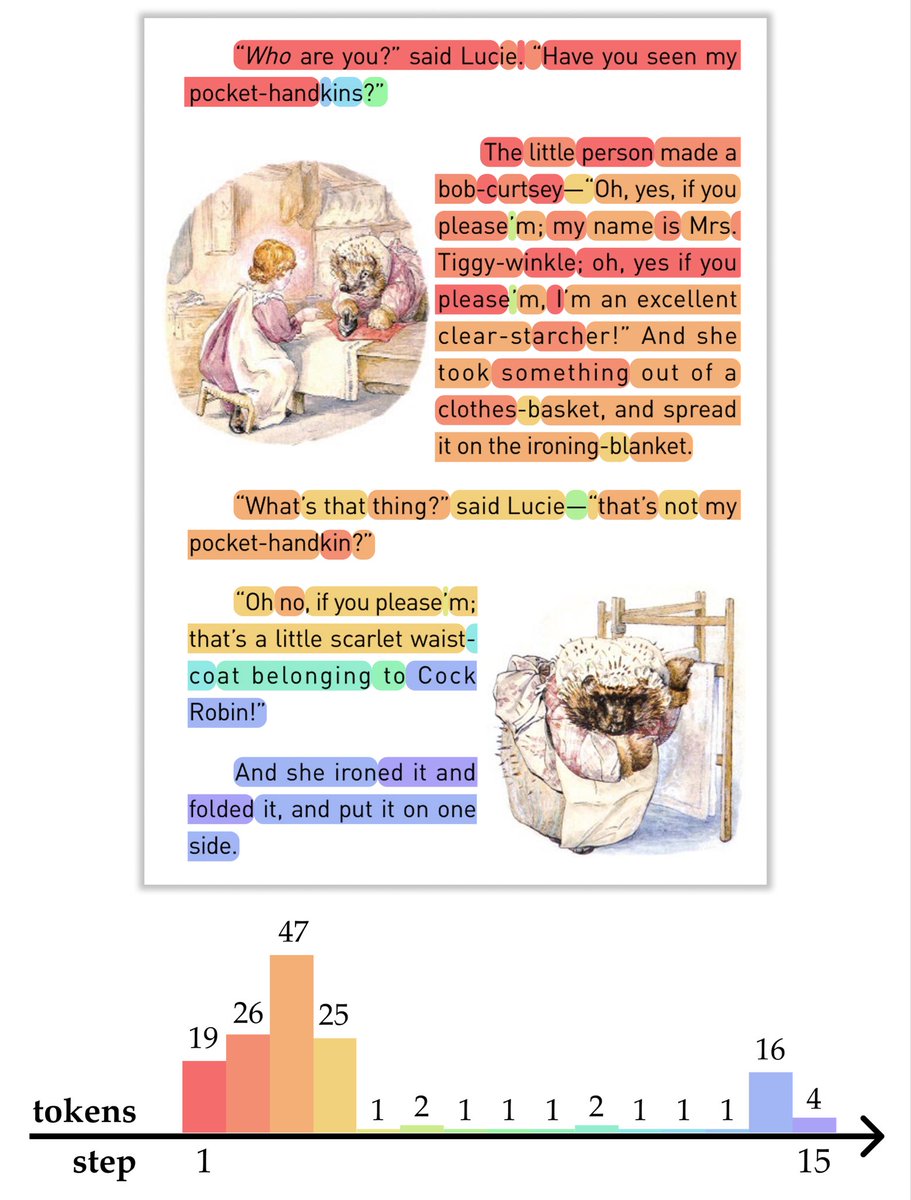
Introducing 🦤 DODO: Discrete OCR Diffusion Models.
This work is the result of my summer internship at Amazon and is the first to study masked diffusion models for document parsing.
OCR is special: the image already contains the answer.
So why decode one token at a time?
English