Sabitlenmiş Tweet
NVIDIA AI
12.6K posts


NVIDIA AI
@NVIDIAAI
Teaching your AI new tricks.
Santa Clara, CA Katılım Haziran 2016
853 Takip Edilen293.6K Takipçiler

This is crazy - 2 hours away from 24 hours of continuous humanoid work!
The robots have sorted over 28,000 packages so far
Bob, Frank, and Gary are all healthy
English

NVIDIA AI retweetledi

💡 Why did @togethercompute choose NVIDIA Blackwell to serve DeepSeek-V4?
Because NVIDIA Blackwell is built for the bottlenecks that matter most in long-context inference:
→ KV-cache pressure during decode
→ MoE weight bandwidth during prefill
A single NVIDIA HGX B200 system can keep DeepSeek-V4’s compressed CSA/HCA/SWA cache layouts resident across many concurrent long-context requests, while native MXFP4 support enables efficient end-to-end quantized inference for V4’s MoE weights.
The result? Higher throughput, lower overhead, and optimized serving efficiency at scale.
Together AI@togethercompute
English

The tokenizer inside @NVIDIA Dynamo? That's fastokens — built by Crusoe. On NVIDIA GB200 NVL72 it delivers 9.1x average speedup over Hugging Face and up to 40% faster TTFT.
We don't just run open-source. We build it.
Read the full breakdown: crusoe.ai/resources/blog…
English

Curious what people are running locally these days 👀
Sudo su@sudoingX
what a time to be alive. i asked my dgx spark for updates from my phone. hermes agent came back with all 8 tests passing across 3 test suites. all green. all done autonomously on a 121B model running locally. i didn't write a single test. i just asked. this is the future and it's already here.
English

We use renderers across Lab, verifiers, and prime-rl.
We are collaborating with leading open-source partners, including @NVIDIA @vllm_project @sgl_project, to ensure it can become a useful standard across models, inference engines, and RL infra stacks throughout the ecosystem. primeintellect.ai/blog/renderers
English
Introducing Renderers
RL trainers work in tokens. Environments work in messages. Going back and forth corrupts sampled tokens, wasting compute on every agentic turn.
With Renderers, we fix this mismatch. This unlocks >3x throughput on popular open models.

English




Since I got it stable I've burned 1B tokens on Qwen3.6 that would have cost over $500! This thing will definitely pay for itself in under 1 year. No regrets so far.
Running Total (22 days): 1,046,312,172 tokens | 15,630 messages | $525.62
@NVIDIAAI
Craig Mouser@mouser58907
Uh oh, look what daddy did! (Hopefully not a huge regret)
English

I just received a 100,000$ grant from the Human Rights Foundation.
In total I received:
- 100K USD through HRF
- 25.8K USD through donations site
- 25K Brev credits through Nvidia
- 4x B200s for a month
- 5K from lambda
- 4x RTX PRO 6000 private donor
Open source must win
0xSero@0xSero
English
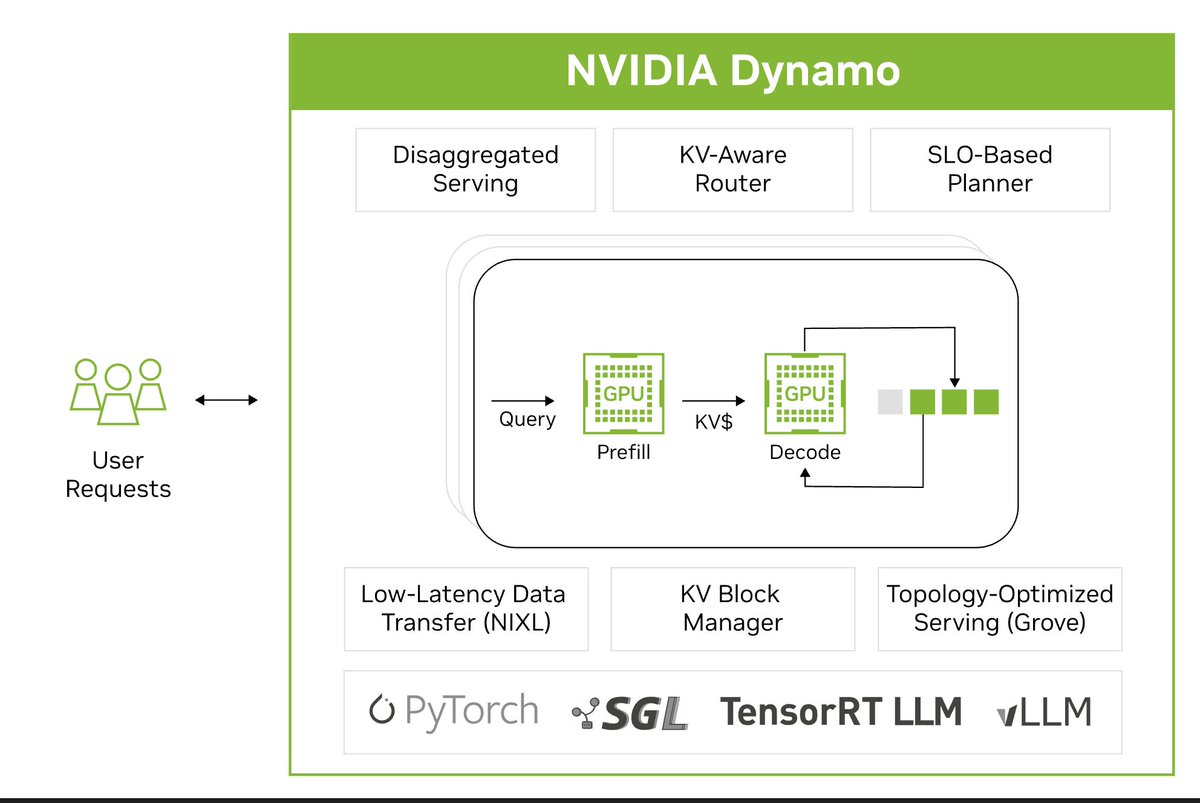
Delivering agentic inference at scale requires balancing efficiency across:
1) Models and algorithms
2) Software
3) Compute
Our full-stack platform continuously optimizes for these inputs using extreme co-design across compute, networking, storage, and memory. Plus, software with broad ecosystem support across millions of developers.
The result: lower cost per token, higher throughput, and more scalable AI systems.
English
OpenShell v0.0.40
🔀 local-domain service routing in the gateway
☸️ k8s node scheduling + tolerations
🔒 CLI TLS now uses the OS trust store
🛡️ SecretResolver debug no longer leaks secrets
Two security fixes ship alongside new routing and K8s scheduling control.
github.com/NVIDIA/OpenShe…
English

@NVIDIAAI Nemoclaw obviously. It's insane to even be testing anything else.
English

@NVIDIAAI I just built my home robot to use VSLAM and navigate the environment autonomously. Based on NVIDIA Jetson Orin Nano super dev kit and RGB-D camera. Next to pure voice interaction capability through LLM and NemoClaw to get it to do things and interact with users 💪🏽
English
Build Video Analytics AI Agents with Skills x.com/i/broadcasts/1…
English

nobody is talking about how good nemotron 3 nano omni 30b-a3b actually is on local. very underrated.
multimodal, reasoning, video understanding, image vision, all shipped in one open source release by nvidia. moe architecture 30b total params, 3b active per token, q8 is near lossless and fits comfortably on a single dgx spark with room to breathe.
i have been running it for weeks now and the gap between what this model can do and what the conversation says is wide. nvidia is pushing hard on the open-source front. most builders haven't noticed yet because the discourse is locked on closed-source frontier benchmarks and the next viral chart.
meanwhile this thing handles agentic loops, processes video inputs, reasons across image context, and stays responsive on consumer tier unified memory hardware. on dgx spark it flies.
more content coming, showing all the modalities in action.
if you have used it, what is your experience. drop your stack and your findings, curious what other builders are seeing across hardware tiers.

English
@poolsideai @nvidia @PrimeIntellect @huggingface This will be great! Can't wait to see what people build
English

Poolside is hosting a 2-day model research hackathon in London.
Join us to push an open-weight agent model as far as you can. RL and fine-tune Laguna XS.2, our latest-generation model, on Prime Intellect Lab.
Dates: May 29–30
Partners: @nvidia + @PrimeIntellect + @huggingface
Prize: NVIDIA DGX Spark
Agents need better models.
Better models need cracked researchers.
Link below.
English