Sabitlenmiş Tweet

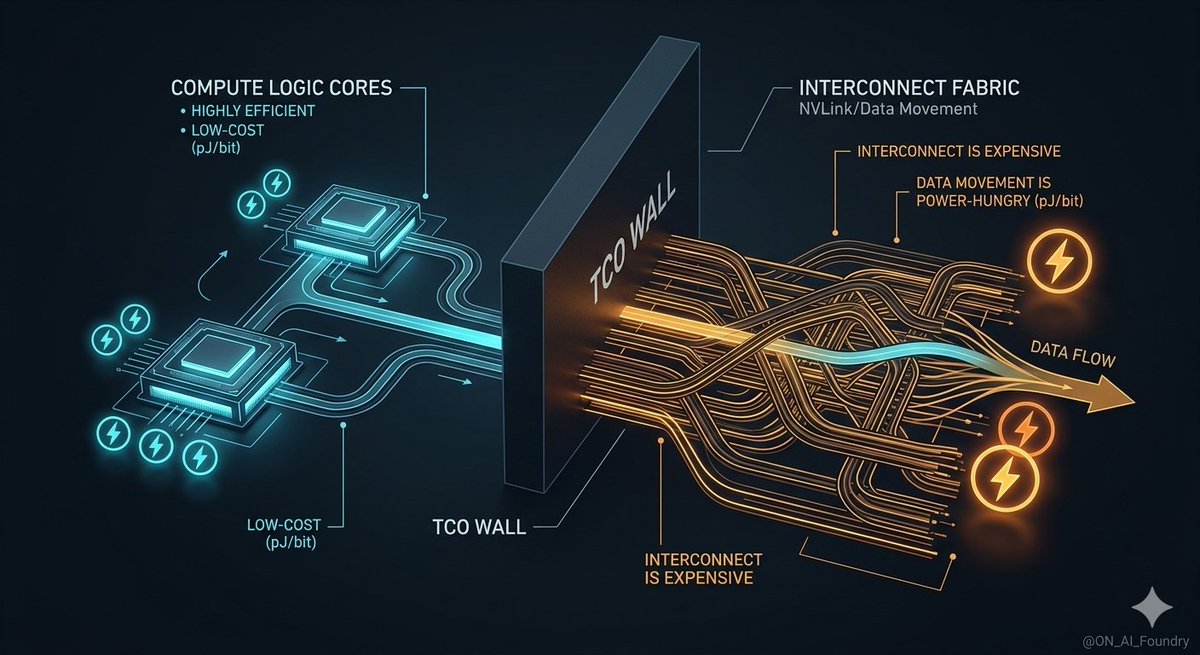
1,000x scaling at #GTC26 is a marketing masterpiece. But under the hood, we are hitting a physical wall. Logic is effectively free; Data Movement is the 'Invisible Tax'. If we don't solve for physics, the AI ROI collapses. Why pJ/bit is the only metric:
English