Sabitlenmiş Tweet

Read “Windows Internals: Thread Management — Part 1“ by OS Dev on Medium:
This article discusses about ETHREAD, KTHREAD kernel objects & windows scheduler - how it schedules a thread.
medium.com/windows-os-int…
English
OS Dev
875 posts

@OSdev_
Senior Engineer @Qualcomm - Performance Engineering | Windows kernel | C/C++ | ARM64 | CPU & Memory Microarchitectures | SoC's





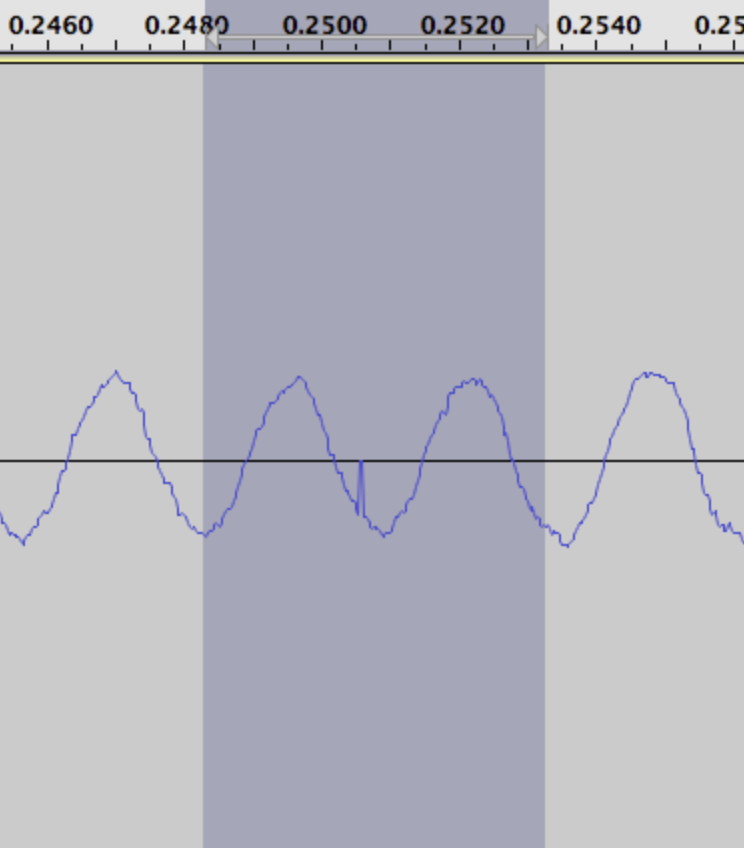
Real Time Audio on general purpose operating systems is ridiculously hard to code. Unfortunately (and unlike the visual system!) humans are *really* good at noticing audio hitches. In video, you might have ~16ms to process a video frame, and if you miss the deadline, eh, just continue to display the existing frame. It’ll hitch…but a lot of people won’t notice. The eye is fairly forgiving, mostly deals in averages. If you miss a SINGLE audio sample (.00002 sec at 44.1khz!) it’s super obvious! The ear was basically made to detect discontinuities in waveforms; the real life equivalent would be like a twig snapping. The waveform collapse (single audio sample dropped) spreads energy across every frequency band at once, almost every hair cell in your cochlea fires! There’s not really a great way to fix this. You can sample and hold, (either just the sample or the whole buffer), but the splice to the next chunk will have a *very* audible seam. Smarter systems will crossfade, and then really intelligent protocols like modern bluetooth will attempt to pitch-bend the seam. But every single one of those “fixes” costs latency and CPU time…which you don’t have in real time audio!




Gonna start a new blog series where I document small Windows features/changes/techniques that I couldn't find documented anywhere. I have a few ideas already but is there anything you'd like me to write about?
















