🌌
104 posts



This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status…
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
Thariq@trq212
English

@gerardtbaker America's primary problem is in the middle East not in Europe.
Europe refuses to help with the middle East situation so America should pull all support from any military action in Europe
Fix it yourselves
Give Ukraine long range missiles if you see fit who cares
English

Obscene thing to say. If you must, say, “I’m sorry but Ukraine is not our problem; we have bigger issues to deal with; Europe should step up”. But to say you’re proud of starving a country of help in the face of lethal aggression? Just don’t understand this man’s morality.
Republicans against Trump@RpsAgainstTrump
JD Vance: Stopping funding for Ukraine is one of the things I’m proudest we’ve done in this administration.
English


well, I just maxed out my claude max plan -- can't use it again until Tuesday, what does one do?
English

You are welcome to use Claude Code if you want, but remember that your competitor, who's about to kick your ass, is using Codex.
English

This feels like physical product design's ChatGPT moment.
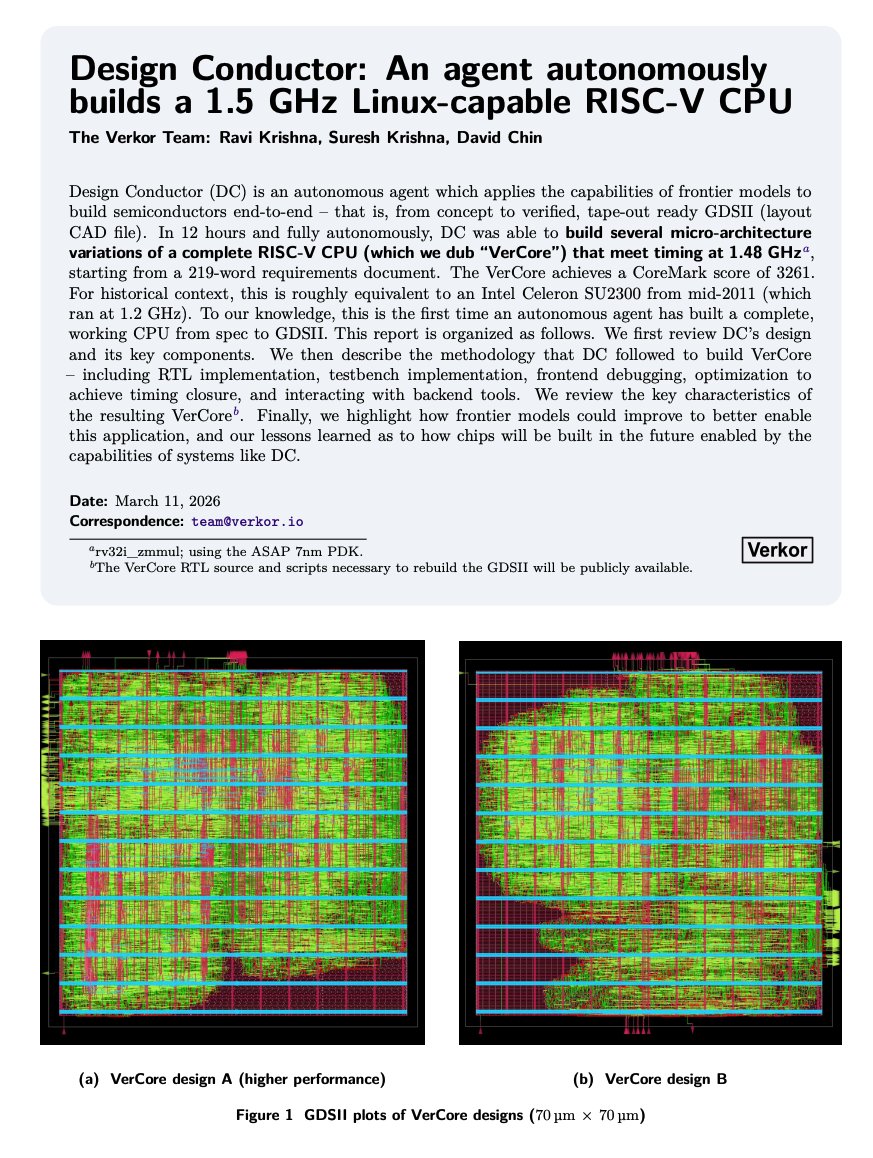
This team just ran an autonomous agent against the entire chip design process: 219-word spec in, tape-out-ready silicon layout out, 12 hours later. The agent ran continuously against a simulator, found its own bugs, rewrote its own pipeline, and iterated to a working CPU!
Chip design costs well over $400M and takes up to 9 years. Not because writing hardware code is hard (it is actually brutally hard) but because a respin costs 10 of millions. So teams spend more than half their total budget just verifying the design is correct before a single transistor is placed. That cost structure is why most chip designs never get built.
Entire product categories that were previously too low-volume to justify a tape-out are now buildable.
Towaki Takikawa / 瀧川永遠希@yongyuanxi
Design Conductor: an AI agent that can build a RISC-V CPU core from design specs. The agent is given access to a RISC-V ISA simulator and manuals... to enable an end-to-end verification-driven generation. The most important thing for design intelligence is a verifier 😎
English

Design Conductor: an AI agent that can build a RISC-V CPU core from design specs. The agent is given access to a RISC-V ISA simulator and manuals... to enable an end-to-end verification-driven generation.
The most important thing for design intelligence is a verifier 😎
English
@getjonwithit Your thread was several times longer than the Kolmogorov complexity it entails. Can you do better than 12/12?
English

So I think it's becoming increasingly clear that efficiency and losslessness, across both compression and decompression, together represent four potential axes along which we can begin to parameterize the space of possible (intelligent) minds.
But what are the others? (12/12)
English
I think one of the conclusions we should draw from the tremendous success of LLMs is how much of human knowledge and society exists at very low levels of Kolmogorov complexity.
We are entering an era where the minimal representation of a human cultural artifact... (1/12)
English

@James_Martell_ If she were a remotely decent philosopher she wouldn't have gone immediately from PhD to working for OpenAI the Anthropic. Not because she'd be at a university, but because she'd recognise con-artists when she saw them
English


@_simonsmith Is it better than Opus 4.6? Im thinking whether to switch lol
English

Whoever worked on GPT-5.4's writing abilities: I would love to learn more about how the model improved so much here, and what went wrong before it. GPT-5.4 has a mastery of language and writing styles that feels like a leap over prior OpenAI reasoning models. It's also witty.
English




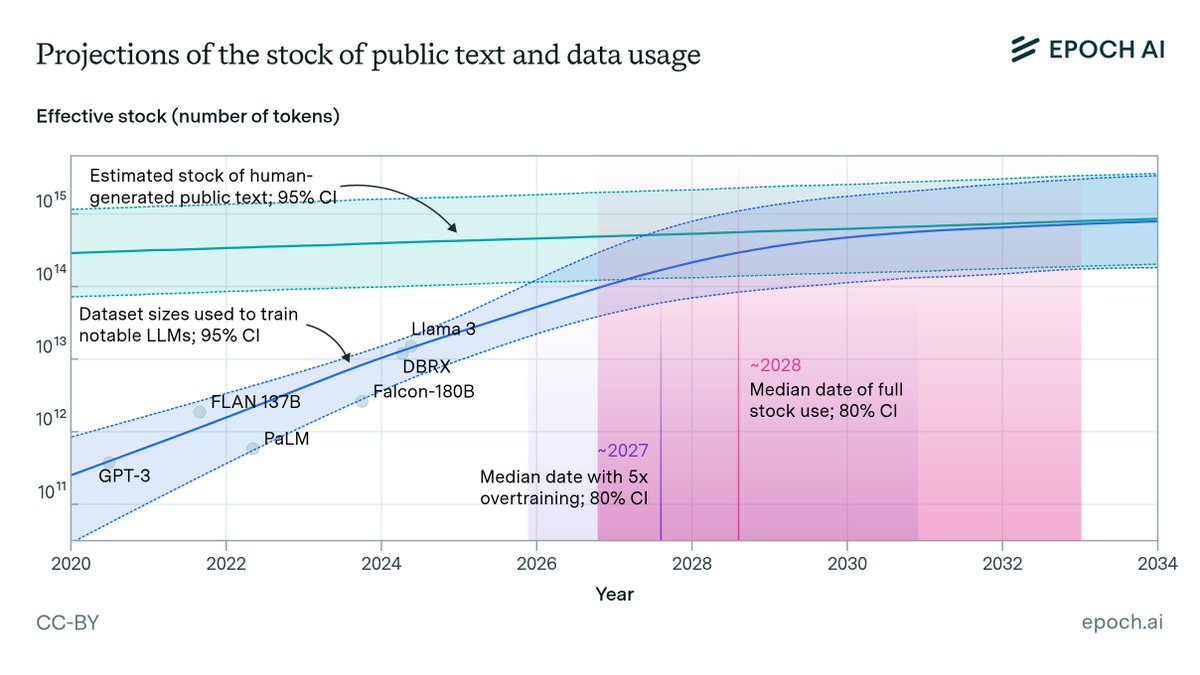
🚨 The AI bubble is about to pop and nobody's talking about it.
Epoch AI's latest research proves frontier models will hit a data wall by 2026.
Billions in compute investments? About to become worthless.
Here's why the entire industry is about to flip upside down:
English
@JonhernandezIA The people in this video look like bullshitters and gullible audience.
English

📁Mo Gawdat, former Google X executive, says AI is no longer just writing code, it is correcting human mathematics.
After 56 years using the same matrix multiplication method, AI realized the approach was flawed. It did not optimize software. It invented new math.
The result was a 23% performance boost and the removal of hundreds of millions of dollars in costs and energy use.
English
@HanicsResearch @SchmidhuberAI Another fact that is often glossed over is that Bell labs spent significant efforts in trying to build a FET before the point contact transistor.
The paper by Bardeen shows the impressive level of insight they already had. And we see what he builds on: Mott, Gurney and Schottky

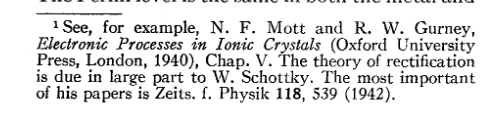

English

@SchmidhuberAI @Observer2077 Yes, but that was just the principle - the BJT breakthrough in 1948 was just as important, even if MOSFETs then later took over (which also needed other breakthroughs, than the FET foundations).
I'm genuinely not sure how much inspiration the BJT took from the 1925 paper
English

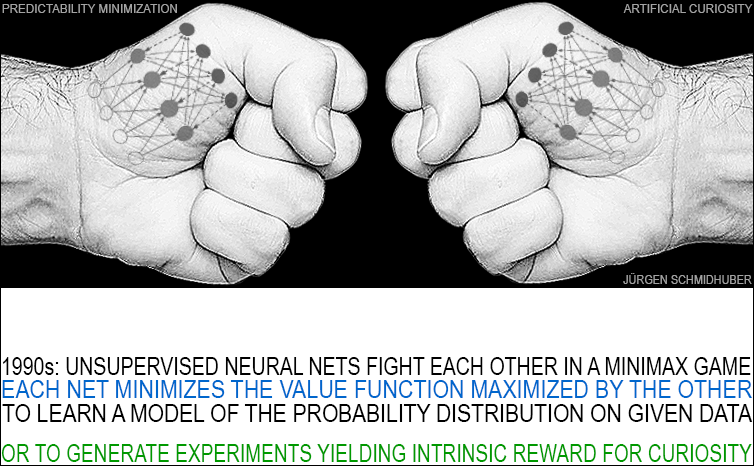
Yet another award for plagiarism. Of all the papers that could have won the #NeurIPS2024 Test of Time Award, it had to be the #NeurIPS 2014 paper on "Generative Adversarial Networks" [GAN1]. This is the notorious paper that republished the 1990 principle of Artificial Curiosity [AC90,AC90b,AC20,AC][R2] under a new name without citing it. See references [AC90,AC90b] (1990-91) that were published when compute was about 100,000 times more expensive than in 2014: two neural nets (NNs) fight each other. A control network with adaptive stochastic Gaussian units (a generative model) generates output data. This output is fed into a predictor NN which learns by gradient descent to predict the effects of the outputs. However, in a minimax game, the first NN maximizes the loss minimized by the second NN. See Section "Implementing Dynamic Curiosity and Boredom" of [AC90,AC90b]: it mentions preliminary experiments where (in absence of external reward) the predictor minimizes a linear function of what the generator maximizes.
Even later surveys by the authors failed to cite the original work [DLP].
One year later, in 1991, there was also another 2-network adversarial system called "Predictability Minimization" [PM0,PM1] for creating disentangled representations. The 2014 GAN paper [GAN1] cites it, but wrongly claims that PM is NOT a minimax game. However, PM experiments from 1991 [PM0,PM1] and 1996 [PM2] (with images) are of the minimax type. The 2014 GAN authors have never corrected their 2014 paper [DLP].
There is a peer-reviewed journal publication on this priority dispute [AC20]. (Other early adversarial machine learning settings since 1959 [S59][H90] were very different - they neither involved self-supervised NNs where one NN sees the output of another generative NN and tries to predict its consequences, nor were about modeling data, nor used gradient descent [AC20].)
Of course, it is well known that plagiarism can be either "unintentional" or "intentional or reckless" [PLAG1-6], and the more innocent of the two may very well be partially the case here [NOB][DLP]. But science has a well-established way of dealing with "multiple discovery" and plagiarism - be it unintentional [PLAG1-6][CONN21] or not [FAKE,FAKE2] - based on facts such as time stamps of publications and patents. The deontology of science requires that unintentional plagiarists correct their publications through errata and then credit the original sources properly in the future. The awardees didn't; instead the awardees kept collecting citations for inventions of other researchers [DLP]. Isn't this behaviour intentional plagiarism as it turns even unintentional plagiarism [PLAG1-6] into an intentional form [FAKE2][NOB][DLP]?
Some people have lost their titles or jobs due to plagiarism. Harvard's former president resigned after some drama [PLAG7][NOB]. But how can advisors from the field of Machine Learning now continue to tell their PhD students that they should avoid plagiarism?
REFERENCES
[GAN1] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio. Generative adversarial nets. NIPS 2014, 2672-2680, Dec 2014. A description of GANs that does not cite J. Schmidhuber's original GAN principle of 1990 [AC90,AC90b][AC20][AC][DLP] (also containing wrong claims about J. Schmidhuber's separate adversarial NNs for Predictability Minimization [PM1-2][AC20][DLP]).
[AC90] J. Schmidhuber. Making the world differentiable: On using self-supervised fully recurrent neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM, Feb 1990, revised Nov 1990. The first paper on planning with reinforcement learning recurrent neural networks (NNs) and on generative adversarial networks where a generator NN is fighting a predictor NN in a minimax game.
[AC90b] J. Schmidhuber. A possibility for implementing curiosity and boredom in model-building neural controllers. In J. A. Meyer and S. W. Wilson, editors, Proc. of the International Conference on Simulation of Adaptive Behavior: From Animals to Animats, pages 222-227. MIT Press/Bradford Books, 1991. Based on [AC90].
[AC20] J. Schmidhuber. Generative Adversarial Networks are Special Cases of Artificial Curiosity (1990) and also Closely Related to Predictability Minimization (1991). Neural Networks, Volume 127, p 58-66, 2020.
[AC] J. Schmidhuber (AI Blog, 2021). Artificial Curiosity & Creativity Since 1990-91.
[PM0] J. Schmidhuber. Learning factorial codes by predictability minimization. TR CU-CS-565-91, Univ. Colorado at Boulder, 1991.
[PM1] J. Schmidhuber. Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879, 1992.
[PM2] J. Schmidhuber, M. Eldracher, B. Foltin. Semilinear predictability minimzation produces well-known feature detectors. Neural Computation, 8(4):773-786, 1996.
[R2] Reddit/ML, 2019. J. Schmidhuber really had GANs in 1990.
[S59] A. L. Samuel. Some studies in machine learning using the game of checkers. IBM Journal on Research and Development, 3:210-229, 1959.
[H90] W. D. Hillis. Co-evolving parasites improve simulated evolution as an optimization procedure. Physica D: Nonlinear Phenomena, 42(1-3):228-234, 1990.
[DLP] J. Schmidhuber (2023). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023.
[NOB] J. Schmidhuber (Dec 2024). A Nobel Prize for Plagiarism. Technical Report IDSIA-24-24. Sadly, the Nobel Prize in Physics 2024 for Hopfield & Hinton is a Nobel Prize for plagiarism. They republished methodologies developed in Ukraine and Japan by Ivakhnenko and Amari in the 1960s & 1970s, as well as other techniques, without citing the original papers. Even in later surveys, they didn't credit the original inventors (thus turning what may have been unintentional plagiarism into a deliberate form). None of the important algorithms for modern Artificial Intelligence were created by Hopfield & Hinton.
[PLAG1] Oxford's guide to types of plagiarism (2021). Quote: "Plagiarism may be intentional or reckless, or unintentional."
[PLAG2] Jackson State Community College (2022). Unintentional Plagiarism.
[PLAG3] R. L. Foster. Avoiding Unintentional Plagiarism. Journal for Specialists in Pediatric Nursing; Hoboken Vol. 12, Iss. 1, 2007.
[PLAG4] N. Das. Intentional or unintentional, it is never alright to plagiarize: A note on how Indian universities are advised to handle plagiarism. Perspect Clin Res 9:56-7, 2018.
[PLAG5] InfoSci-OnDemand (2023). What is Unintentional Plagiarism?
[PLAG6] Copyrighted dot com (2022). How to Avoid Accidental and Unintentional Plagiarism (2023). Quote: "May it be accidental or intentional, plagiarism is still plagiarism."
[PLAG7] Cornell Review, 2024. Harvard president resigns in plagiarism scandal. 6 January 2024.
[FAKE] H. Hopf, A. Krief, G. Mehta, S. A. Matlin. Fake science and the knowledge crisis: ignorance can be fatal. Royal Society Open Science, May 2019. Quote: "Scientists must be willing to speak out when they see false information being presented in social media, traditional print or broadcast press" and "must speak out against false information and fake science in circulation and forcefully contradict public figures who promote it."
[FAKE2] L. Stenflo. Intelligent plagiarists are the most dangerous. Nature, vol. 427, p. 777 (Feb 2004). Quote: "What is worse, in my opinion, ..., are cases where scientists rewrite previous findings in different words, purposely hiding the sources of their ideas, and then during subsequent years forcefully claim that they have discovered new phenomena."
English
@SchmidhuberAI oh and Nature published on it:
nature.com/articles/s4192…
English
@SchmidhuberAI This is a lot less controversial than some of your other takes. This years IEDM (The most important semiconductor device conference) even celebrates "100 years of FETs"
ieee-iedm.org
English
@SchmidhuberAI The bipolar junction transistor, apparently invented by Shockley to spite the serendipitous invention of the point contact transistors by his colleauges, is an intellectually much more complex concept.
English

🚨BREAKING: MIT researchers discover how to enable LLMs to do real logical reasoning.
This is what you need to know:
(thread)

English