Sabitlenmiş Tweet

OpenCompass is onboard for Twitter (@X), focusing intently on the evaluation and analysis of Large Language Models and Vision-Language Models. Welcome to star our project: github.com/open-compass/o…
English
OpenCompass
80 posts

@OpenCompassX
OpenCompass focus on the evaluation and analysis of large language models and vision language models. github: https://t.co/zF7ycuTXxs
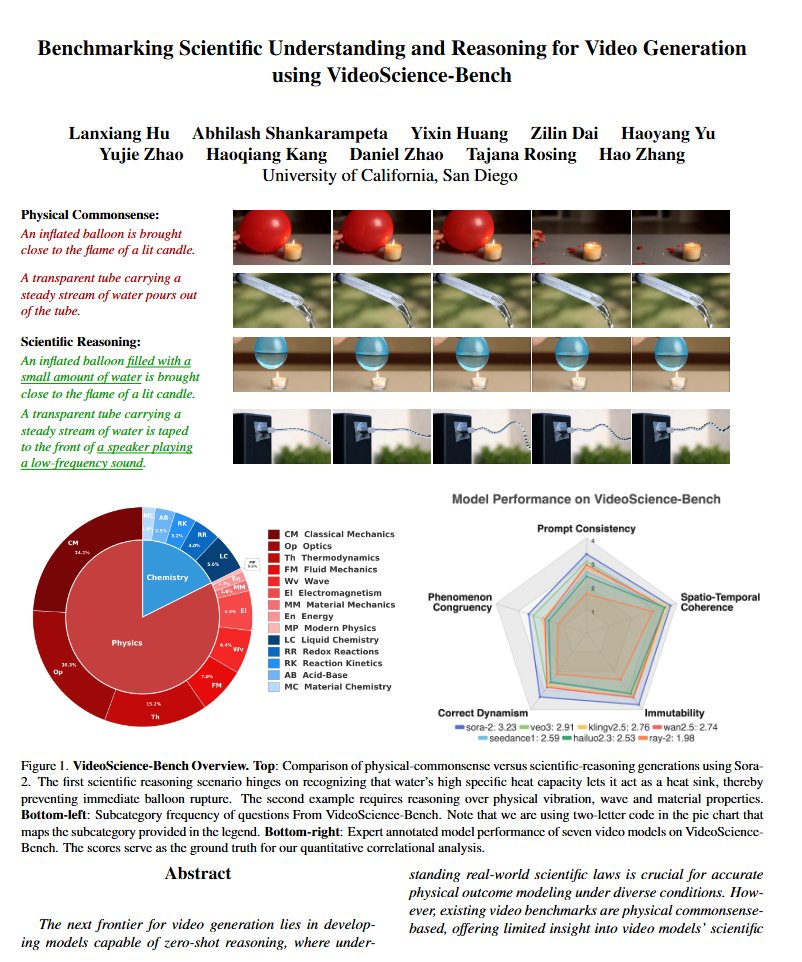











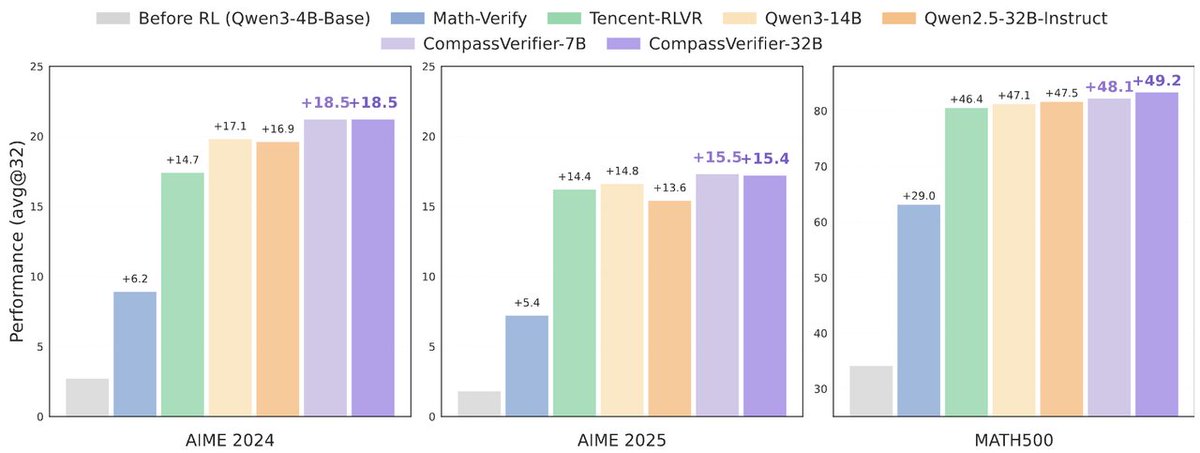



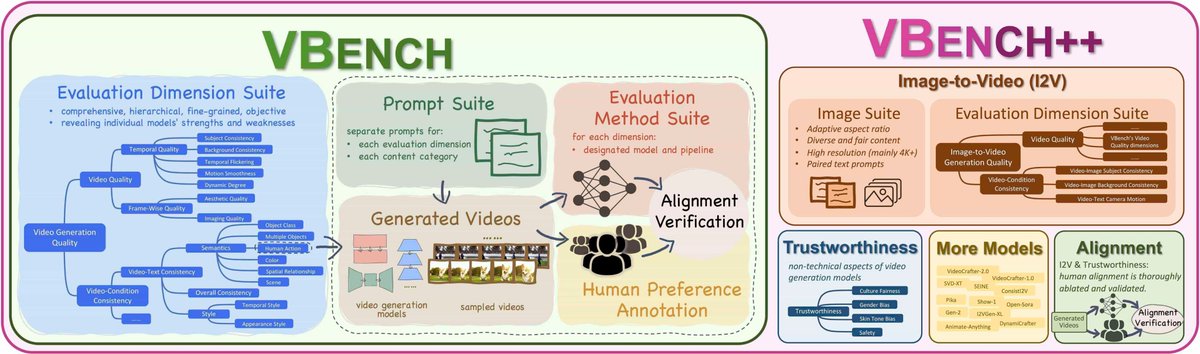
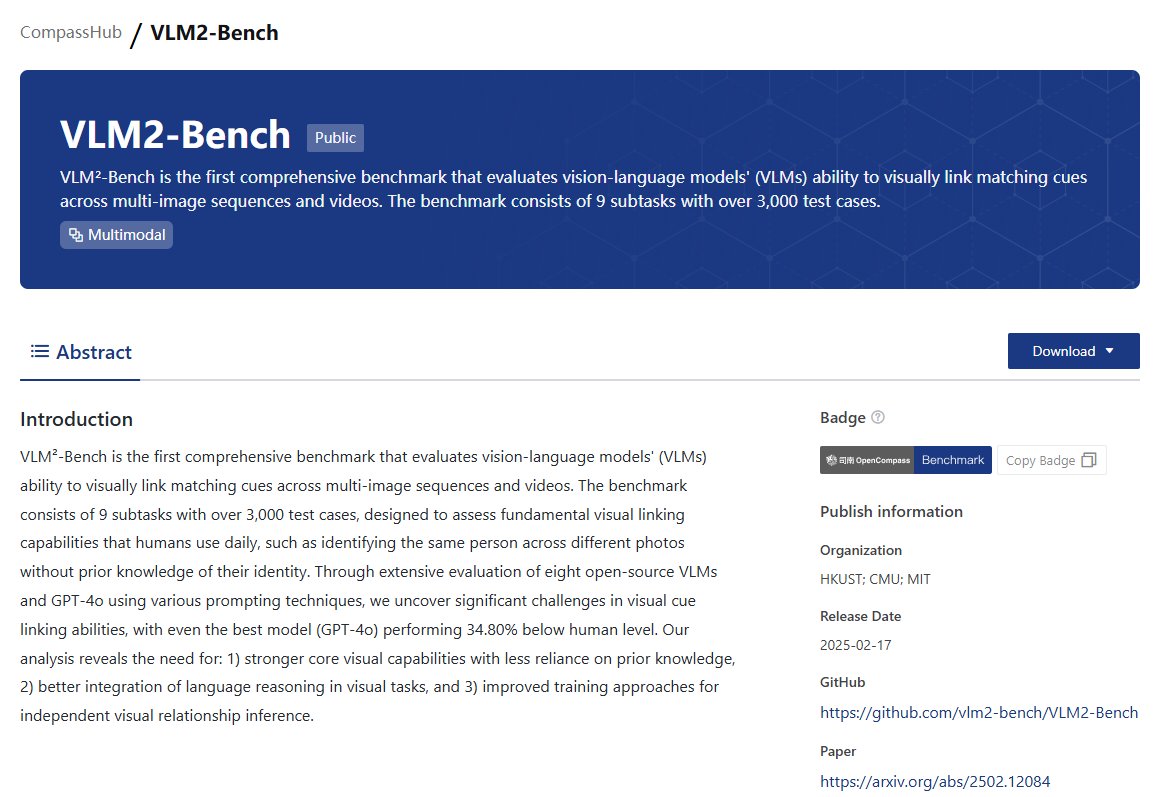
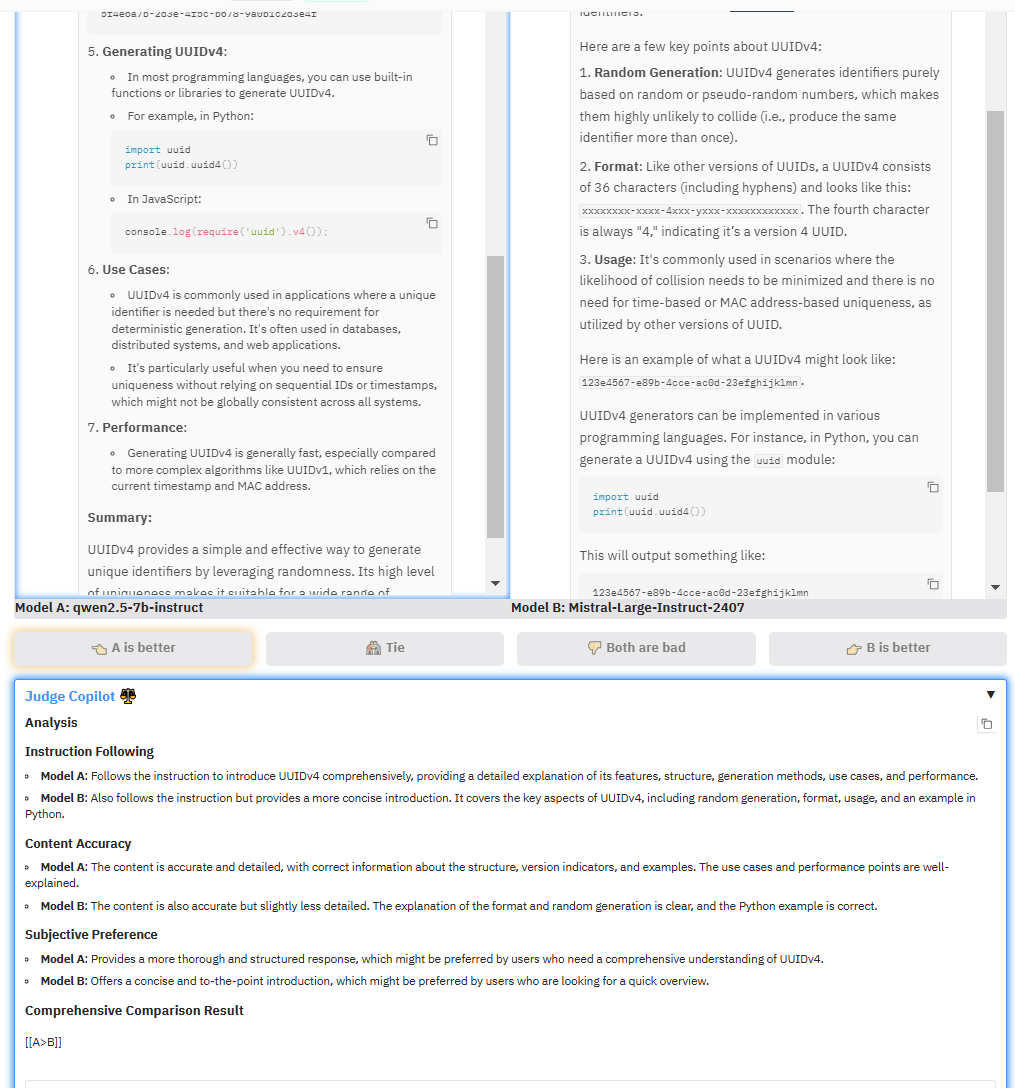


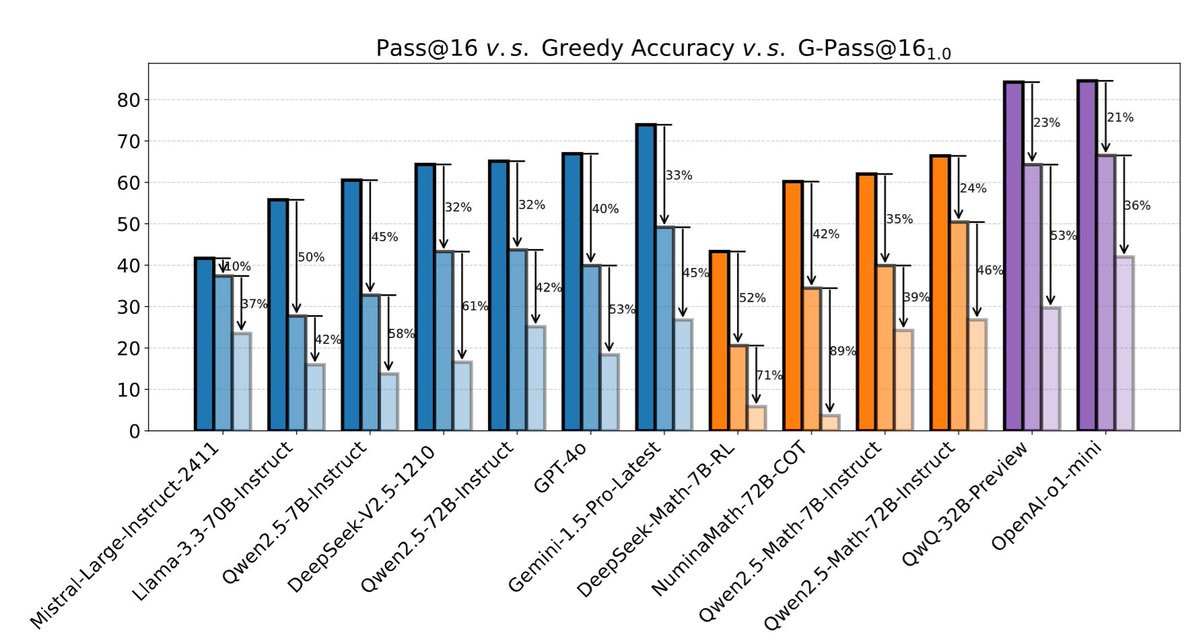
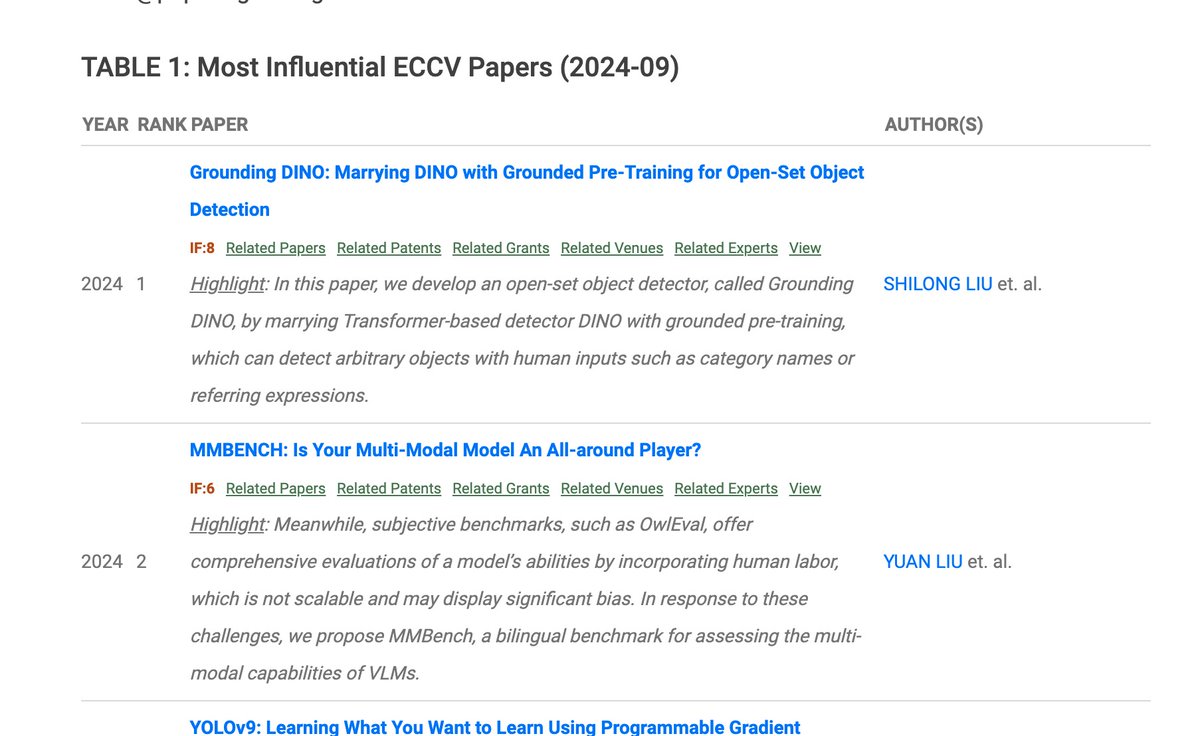
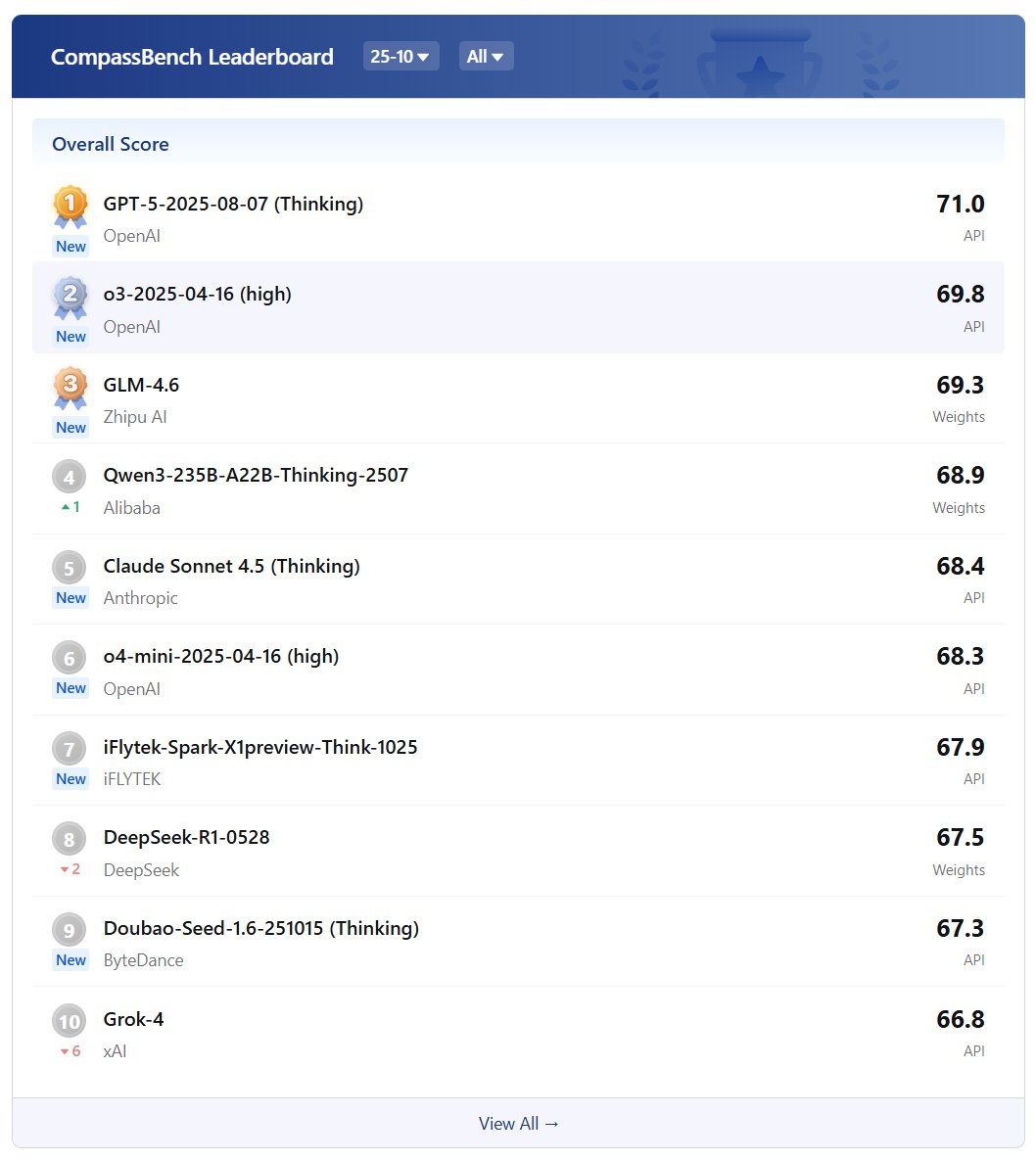
OpenCompass has established a leaderboard to evaluate complex reasoning capability of LMMs, consisting of four advanced multi-modal math reasoning benchmarks. Currently, Gemini-2.0-Flash took the 1st place. DM me to suggest more benchmarks and models to this LB.