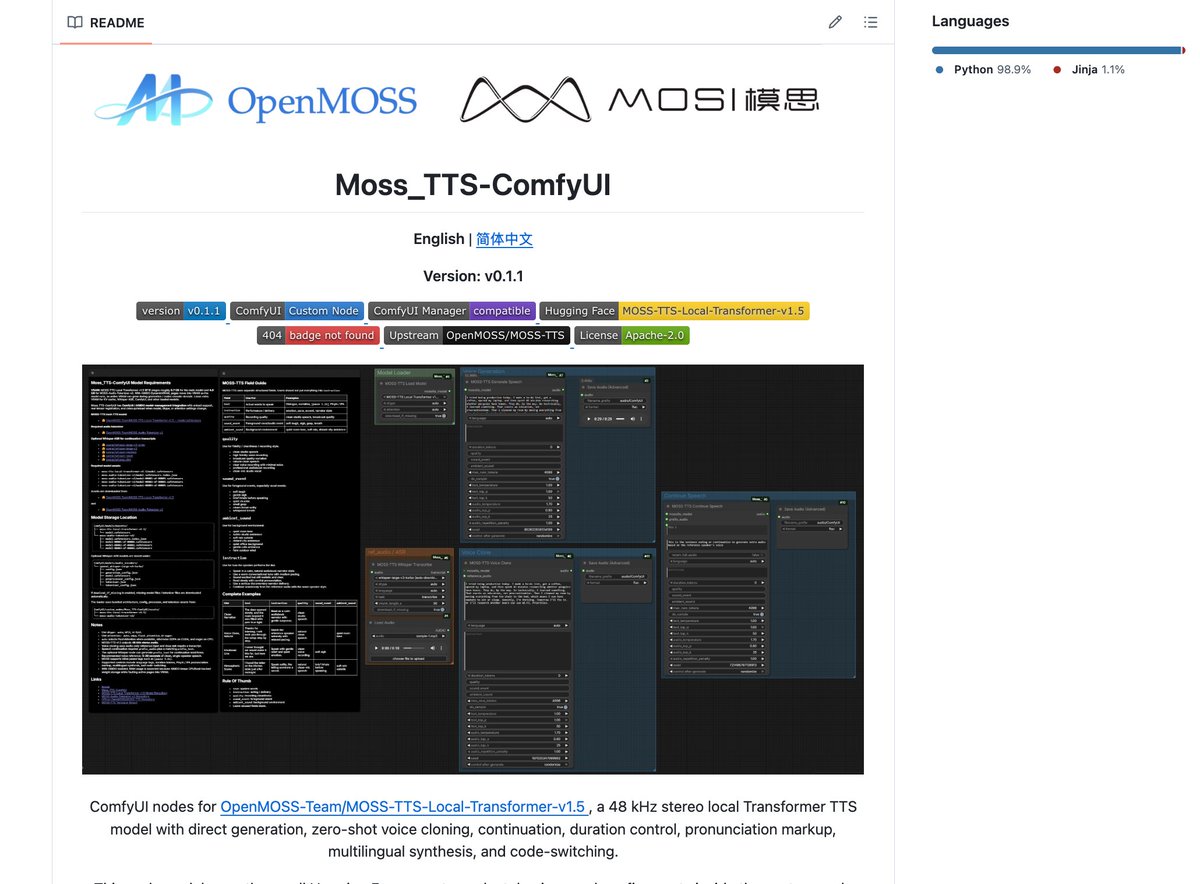
🤗 MOSS-Transcribe-Diarize-0.9B is now open source on @huggingface. Built with an end-to-end audio-to-structured-transcript paradigm: >0.9B open-source ASR model >Apache license 2.0 >128k long-context transcription >Up to ~90-min audio input >Speaker labels + timestamps in one generation >Multi-speaker diarization for meetings, interruptions, and overlapping voices >Hotword biasing for names, terms, and domain-specific vocabulary >~100 token/s on NVIDIA RTX 4090, RTF ~0.017 Thank you @sgl_project @vllm_project @Prince_Canuma @lllucas for day-0 support! 🚀 Github: github.com/OpenMOSS/MOSS-… Huggingface: huggingface.co/spaces/OpenMOS… API: shorturl.at/DWwe3 Live demo: shorturl.at/wRZ3j Technical Report:arxiv.org/abs/2601.01554 HF Space: huggingface.co/spaces/OpenMOS… AtomGit:ai.atomgit.com/OpenMOSS/MOSS-… SGLang-Omni: github.com/sgl-project/sg… vLLM: github.com/vllm-project/v… MLX-audio: github.com/Blaizzy/mlx-au… Discord:discord.gg/SmVQHGffZU