@julioc Solid list! Clean Code shaped how I think about writing, not just coding. Kleppmann’s book is a must for building real-world systems. Adding Refactoring by Martin Fowler to the list too!
5 books all software engineers should read:
1. Clean Code ( Robert Martin )
2. Designing Data-Intensive Applications ( Martin Kleppmann )
3. System Design Interview ( Alex Xu )
4. System Design Interview: Volume 2 ( Alex Xu & Sahn Lam )
5. The Software Engineer's Guidebook ( Gergely Orosz )
Which books transformed your career or skills the most?
--
Get my Free .NET Developer Roadmap 👇
juliocasal.com/roadmap
An MCP server that makes anyone a database engineer (open-source)!
@MongoDB just released an MCP Server that lets AI tools like Claude, Cursor, and GitHub Copilot talk directly to a MongoDB deployment.
That means anyone (technical or non-technical) can now say:
- “Show me the most active users”
- “Create a new database user with read-only access”
- “What’s the schema for my orders collection?”
...and let the Agent handle the rest.
No need to type in manual queries or memorize syntax.
This MCP server works across:
- Atlas
- Community Edition
- Enterprise Advanced
Natural language is all you need now to write production-grade queries.
100% open-source! Link in the next tweet.
Thanks to the #MongoDB team for partnering today!
@svpino Interesting list — shows how roles focused on using AI may fade, while those building and steering it stay strong. Adaptability is the real job security.
List of the top 40 jobs that will disappear because of AI.
You know who's here?
• Data scientists
• Web developers
You know who isn’t here?
• AI/ML Engineers
• Software Engineers
(Microsoft study).
@rohanpaul_ai Incredible work! SmallThinker proves that local-first LLMs don’t have to compromise on performance. Love the smart use of sparsity and pre-attention routing—this is a major step toward truly efficient on-device AI.
SmallThinker shows that a 4B or 21B parameter family can hit frontier accuracy while running above 20 tokens/s on plain CPUs with tiny memory.
Current on‑device attempts usually shrink cloud models afterward, losing power, so the paper builds a fresh architecture tuned for weak hardware.
The team mixes two types of sparsity: a fine‑grained mixture of experts that wakes only a handful of mini‑networks per token and a ReGLU feed‑forward block where 60% of neurons stay idle.
This cuts compute, so a common laptop core can keep up.
A pre‑attention router reads the prompt, predicts which experts will be needed, and starts pulling their weights from SSD while attention math is still running, hiding storage lag.
They also blend NoPE global attention once every 4 layers with sliding‑window RoPE layers, trimming the key‑value cache so memory stays under 1GB for the 4B version.
All these tricks feed a custom inference stack that fuses sparse kernels, caches hot experts, and skips dead vocabulary rows in the output head.
Benchmarks show the 21B variant outscoring larger Qwen3‑30B‑A3B on coding and math while decoding 85× faster under an 8GB cap, and the 4B model topping Gemma3n‑E4B on phones.
Training ran from scratch over 9T mixed web tokens plus 269B synthetic math‑code samples, then a light supervised fine‑tune and weight merge locked in instruction skills.
The authors admit knowledge breadth still trails mega‑corpora giants, and RLHF remains future work, yet the concept proves local‑first design is practical.
----
Paper – arxiv. org/abs/2507.20984
Paper Title: "SmallThinker: A Family of Efficient LLMs Natively Trained for Local Deployment"
@akshay_pachaar@MongoDB This is a game-changer! Talking to your database like a teammate unlocks next-level productivity. Excited to see where this goes.
The future of writing database queries is not writing them at all!
@MongoDB just released their own MCP Server, and it quietly shifts how we interact with databases.
It connects to AI tools like Claude, Cursor, or GitHub Copilot, and you can just talk to your database using natural language:
→ "What's the schema for the orders collection?"
→ "Find the top 10 users by purchase volume."
→ "Create a read-only DB user."
No need to context switch. No need to memorize query syntax. No need to even leave your IDE.
It works across MongoDB Atlas, Community, and Enterprise, and supports admin ops, schema exploration, indexing, and code generation, all via natural language.
This way, you can focus on what actually matters: data modeling, app logic, and product experience.
Link to the announcement in the next tweet.
Thanks to #MongoDB team for partnering with me today!
The most dangerous AI isn't the smartest. It's the one without guardrails.
I've seen production systems fail not because the AI wasn't capable, but because it wandered off course without anyone noticing. Agentic AI systems face unique challenges that traditional software simply doesn't:
𝗧𝗵𝗲 𝗛𝗶𝗱𝗱𝗲𝗻 𝗥𝗶𝘀𝗸𝘀:
• Lost in the middle: Agents losing track of instructions during complex, multi-step tasks
• Hallucination amplification: Small errors snowballing into major failures across processes
• Volatile external states: Environments changing during agent execution
• Undesired input behavior: Users attempting to manipulate agent behavior
Without proper guardrails, I've witnessed security breaches, operational meltdowns, and six-figure losses in high-stakes environments.
𝗛𝗲𝗿𝗲 𝗮𝗿𝗲 𝗳𝗼𝘂𝗿 𝗰𝗿𝗶𝘁𝗶𝗰𝗮𝗹 𝗴𝘂𝗮𝗿𝗱𝗿𝗮𝗶𝗹𝘀 𝗲𝘃𝗲𝗿𝘆 𝗮𝗴𝗲𝗻𝘁𝗶𝗰 𝘀𝘆𝘀𝘁𝗲𝗺 𝗻𝗲𝗲𝗱𝘀:
📌 𝗔𝗱𝗮𝗽𝘁𝗶𝘃𝗲 𝗙𝗲𝗲𝗱𝗯𝗮𝗰𝗸 𝗟𝗼𝗼𝗽𝘀
• Use rewards to correct drift and enable mid-course corrections
• Break down high-level goals into smaller, verifiable sub-goals
• Monitor agent behavior and adjust parameters dynamically
• Implement flexible reconfiguration when goals shift
📌 𝗖𝗼𝗿𝗿𝗲𝗰𝘁𝗶𝘃𝗲 𝗔𝗰𝘁𝗶𝗼𝗻 𝗦𝘆𝘀𝘁𝗲𝗺𝘀
• Build "re-do" capabilities for every critical action
• Implement rollback procedures when errors occur
• Use multi-agent cross-validation to catch hallucinations
• Design systems that can restart cleanly from a known good state
📌 𝗛𝘂𝗺𝗮𝗻-𝗶𝗻-𝘁𝗵𝗲-𝗟𝗼𝗼𝗽 𝗖𝗼𝗻𝘁𝗿𝗼𝗹𝘀
• Require human approval for high-risk decisions
• Limit the scope of potential damage through oversight
• Flag high-certainty cases for review (like medical diagnoses)
• Create escalation paths for uncertain or prohibited actions
📌 𝗘𝗺𝗲𝗿𝗴𝗲𝗻𝗰𝘆 𝗦𝘁𝗼𝗽 𝗠𝗲𝗰𝗵𝗮𝗻𝗶𝘀𝗺𝘀
• Implement immediate termination capabilities for runaway processes
• Create safeguards against changes beyond certain thresholds
• Monitor for volatile external states that could cause inconsistent internal states
• Develop parallel systems that run continuous safety checks
The goal isn't to constrain AI - it's to enable it to operate safely at scale. With proper guardrails, agentic systems can tackle increasingly complex workflows while keeping risks manageable.
𝗪𝗵𝗮𝘁'𝘀 𝘆𝗼𝘂𝗿 𝗲𝘅𝗽𝗲𝗿𝗶𝗲𝗻𝗰𝗲 𝘄𝗶𝘁𝗵 𝗔𝗜 𝗴𝘂𝗮𝗿𝗱𝗿𝗮𝗶𝗹𝘀? 𝗪𝗵𝗮𝘁 𝗰𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲𝘀 𝗵𝗮𝘃𝗲 𝘆𝗼𝘂 𝗳𝗮𝗰𝗲𝗱 𝗶𝗻 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻?
Deep dive into Agentic Workflows: weaviate.io/blog/what-are-…
Top AI Algorithms Guide
AI algorithms power various applications, from text analysis to image recognition. Here’s a breakdown of essential AI techniques.
1. Text Analysis
Extracts insights from text data using topic modeling, word vectorization, and text preprocessing for NLP applications.
2. Regression
Predicts continuous values based on past trends using models like linear regression, decision trees, and neural networks.
3. Multiclass Classification
Categorizes data into multiple labels using logistic regression, decision trees, and neural networks for complex tasks.
4. Two-Class Classification
Performs binary decision-making using SVMs, decision forests, and logistic regression for Yes/No predictions.
5. Anomaly Detection
Identifies rare patterns in data using autoencoders, isolation forests, and PCA for fraud detection and security.
6. Recommender Systems
Predicts user preferences using collaborative filtering, hybrid models, and deep learning for personalized recommendations.
Follow me at @goyaalshaliniuk for more such information !
@milan_milanovic Awesome breakdown! Choosing the right Git strategy can truly shape your team's flow and deployment speed. GitHub Flow for speed, Gitflow for structure!
𝗚𝗶𝘁 𝗕𝗿𝗮𝗻𝗰𝗵𝗶𝗻𝗴 𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝗶𝗲𝘀
When managing code in software development, choosing the right branching strategy can significantly impact collaboration, integration, and deployment.
Here are the main Git branching strategies:
𝟭. 𝗙𝗲𝗮𝘁𝘂𝗿𝗲 𝗯𝗿𝗮𝗻𝗰𝗵𝗶𝗻𝗴
It involves creating a new branch for each feature or bug fix. Developers work on these branches independently, merging them into the main codebase (usually the main or develop branch) once the work is completed and reviewed.
It is best suited for teams that require strict code reviews and where features are developed independently.
𝟮. 𝗚𝗶𝘁𝗳𝗹𝗼𝘄
It is a branching model that defines a strict workflow for managing releases. To organize work, it introduces the concept of develop, release, hotfix, and feature branches.
It is best to use it with large projects with scheduled release cycles.
𝟯. 𝗚𝗶𝘁𝗟𝗮𝗯 𝗙𝗹𝗼𝘄
It combines ideas from Feature Branching and Gitflow but simplifies the process. It emphasizes deployment and integrates with issue tracking and continuous deployment.
This strategy includes a main branch representing a production-ready code and optional branches per environment (staging, production, etc.).
It is best to use it for teams using GitLab integrated tools, and if we want to benefit from CD practices.
𝟰. 𝗚𝗶𝘁𝗛𝘂𝗯 𝗙𝗹𝗼𝘄
It is a lightweight, branch-based workflow that is simple and effective for continuous deployment. It focuses on keeping the main branch always in a deployable state. Feature branches are created from the main branch, and we use pull requests to review and merge changes into the main branch.
It is best suited for small teams or projects with continuous deployments.
𝟱. 𝗧𝗿𝘂𝗻𝗸-𝗕𝗮𝘀𝗲𝗱 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁
With this strategy, all developers commit their changes directly to the main branch (the "trunk"). Feature branches are short-lived or avoided altogether.
It is best suited for teams that practice continuous integration and delivery and for projects where rapid development is a priority.
If you're new to Git workflows, start with a simpler strategy like GitHub Flow and evolve as your team and project grow.
For larger teams or more complex projects, consider more structured approaches like Gitflow or GitLab Flow.
Also, regardless of the branching strategy, proper automated testing should be implemented to catch issues earlier and establish team agreements on commit messages, branch naming, and merge procedures.
#softwareengineering#programming#coding
Your JSONB query isn’t slow.
You’re just using the wrong index.
Let’s say you’re storing events like this:
{
"user_id": "123",
"status": "completed",
"source": "mobile"
}
And you're filtering like this:
SELECT * FROM events WHERE payload @> '{"status":"completed"}';
You indexed the whole payload column with a B-Tree.
That won’t work.
Postgres can’t optimize deep JSONB lookups with B-Tree indexes.
So it falls back to a full scan on every query.
To fix this, you need a GIN (Generalized Inverted Index)
Now Postgres creates an inverted index:
- It breaks each JSONB object into keys and values.
- It maps them to row IDs.
- So instead of scanning every row, it jumps directly to matches.
Pro tip: Add the jsonb_path_ops option for even leaner indexes, if you're not using containment queries.
Faster. Smaller. Cleaner.
----------------------------------------------------------
Jobright provides the latest System Design jobs. Check it out here 👇
jobright.ai/ai-agent?utm_i…
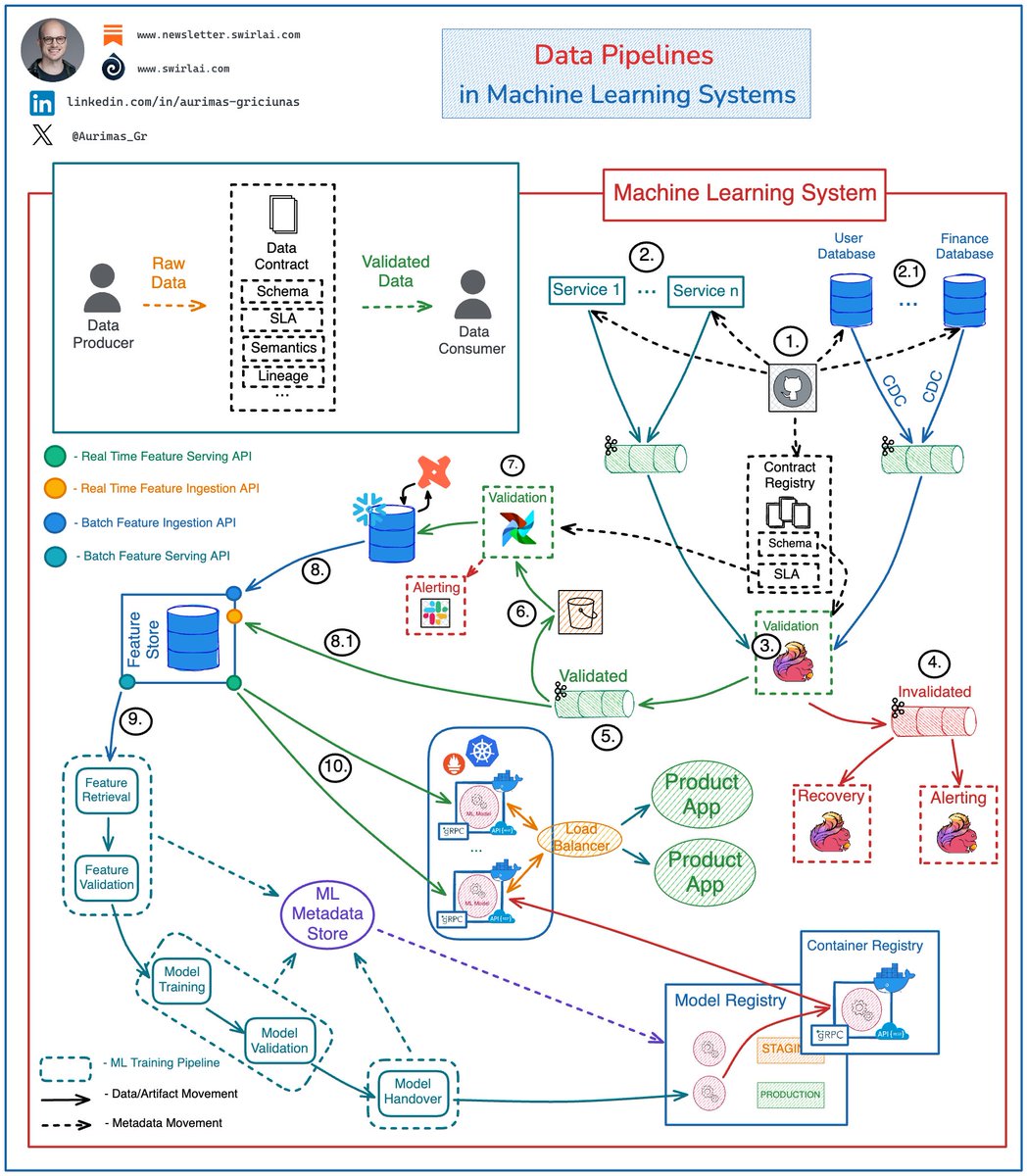
A breakdown of 𝗗𝗮𝘁𝗮 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 𝗶𝗻 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺𝘀 👇 And yes, it can also be used for LLM based systems!
It is critical to ensure Data Quality and Integrity upstream of ML Training and Inference Pipelines, trying to do that in the downstream systems will cause unavoidable failure when working at scale.
There is a ton of work to be done on the Data Lake or LakeHouse layer. 𝗦𝗲𝗲 𝘁𝗵𝗲 𝗲𝘅𝗮𝗺𝗽𝗹𝗲 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗯𝗲𝗹𝗼𝘄.
𝘌𝘹𝘢𝘮𝘱𝘭𝘦 𝘢𝘳𝘤𝘩𝘪𝘵𝘦𝘤𝘵𝘶𝘳𝘦 𝘧𝘰𝘳 𝘢 𝘱𝘳𝘰𝘥𝘶𝘤𝘵𝘪𝘰𝘯 𝘨𝘳𝘢𝘥𝘦 𝘦𝘯𝘥-𝘵𝘰-𝘦𝘯𝘥 𝘥𝘢𝘵𝘢 𝘧𝘭𝘰𝘸:
𝟭: Schema changes are implemented in version control, once approved - they are pushed to the Applications generating the Data, Databases holding the Data and a central Data Contract Registry.
Applications push generated Data to Kafka Topics:
𝟮: Events emitted directly by the Application Services.
👉 This also includes IoT Fleets and Website Activity Tracking.
𝟮.𝟭: Raw Data Topics for CDC streams.
𝟯: A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Contract Registry.
𝟰: Data that does not meet the contract is pushed to Dead Letter Topic.
𝟱: Data that meets the contract is pushed to Validated Data Topic.
𝟲: Data from the Validated Data Topic is pushed to object storage for additional Validation.
𝟳: On a schedule Data in the Object Storage is validated against additional SLAs in Data Contracts and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes.
𝟴: Modeled and Curated data is pushed to the Feature Store System for further Feature Engineering.
𝟴.𝟭: Real Time Features are ingested into the Feature Store directly from Validated Data Topic (5).
👉 Ensuring Data Quality here is complicated since checks against SLAs is hard to perform.
𝟵: High Quality Data is used in Machine Learning Training Pipelines.
𝟭𝟬: The same Data is used for Feature Serving in Inference.
Note: ML Systems are plagued by other Data related issues like Data and Concept Drifts. These are silent failures and while they can be monitored, we can’t include it in the Data Contract.
Let me know your thoughts! 👇
#AI#MachineLearning#DataEngineering
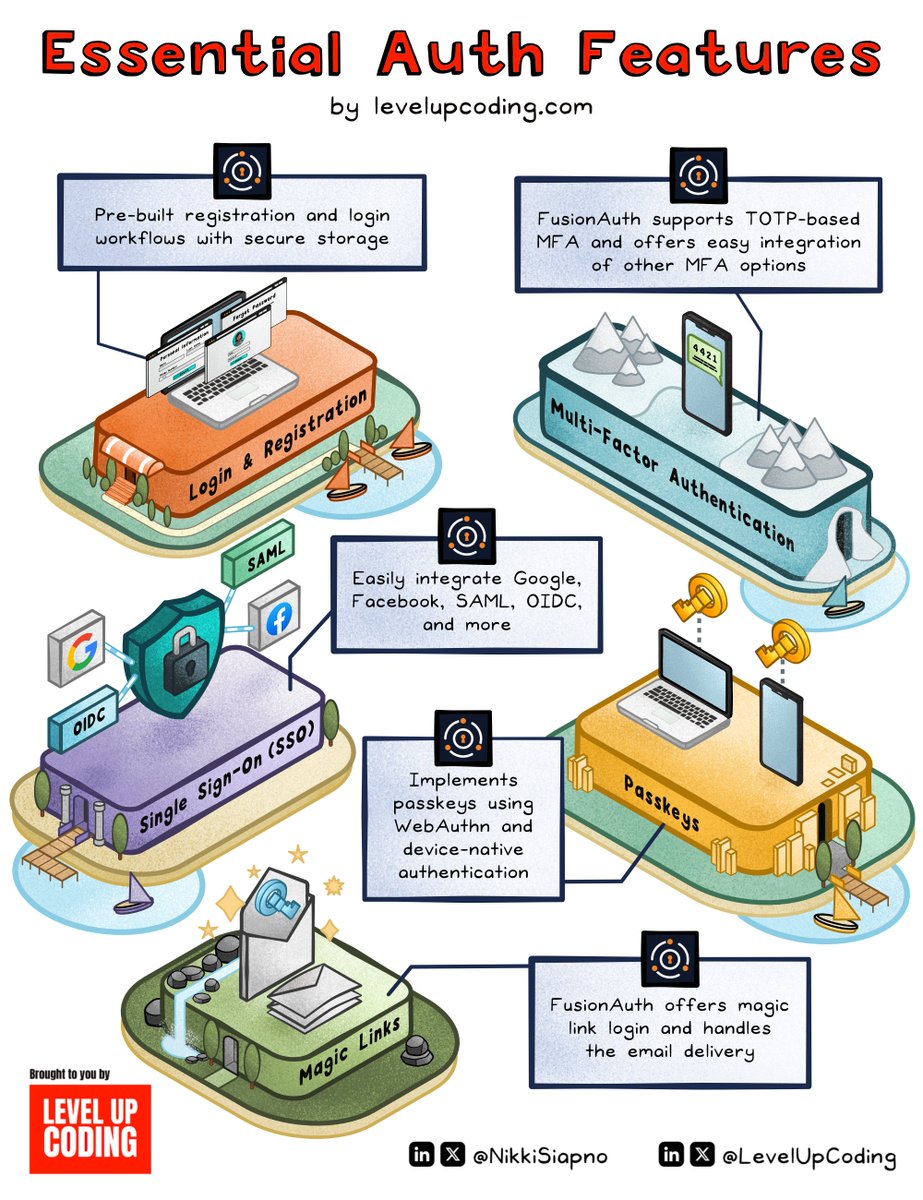
@NikkiSiapno Auth is way harder than it seems! FusionAuth’s hybrid setup is a smart solution—full control without the hassle. Have you built auth from scratch before?
Building auth is easy, all you need to do is:
• Integrate with 10+ OAuth providers
• Build signup, password reset, CAPTCHA flows
• Implement rate-limiting, and 2FA
• Detect fraud and secure sessions
• Support SAML, SSO, account recovery
• Handle edge cases when switching auth methods
• Build internal tools for customer support
• Ensure CSRF protection and secure cookie handling
• Rotate signing keys without breaking existing sessions
• Support passkeys and biometric login (WebAuthn)
• And more
...𝗘𝗮𝘀𝘆, 𝗿𝗶𝗴𝗵𝘁? 𝗢𝗳 𝗰𝗼𝘂𝗿𝘀𝗲 𝗻𝗼𝘁.
That's why auth providers (CIAM solutions) like FusionAuth are so popular.
FusionAuth is an auth provider that I've been very impressed with.
It’s a fully downloadable, API-first auth platform built for developers who need auth to just work. No fragile mocks. No rigid SaaS-only models.
They're the only CIAM with hybrid, single-tenant deployment so you can develop and test anywhere with full control.
Since it's downloadable, you don’t have to deal with unnecessary context switching or mocking.
With hybrid, single-tenant deployment, you get:
• Local dev parity with real data
• CI/CD friendly installs
• No vendor lock-in
• All the features: SSO, 2FA, OAuth, MFA, passkeys, account recovery & more
You can self-host it, run it in the cloud, or both. On your timeline, with full control.
And they provide a surprisingly feature-rich free tier to get started too.
Check it out: lucode.co/fusionauth-z7td
Thanks to @FusionAuth for building a fantastic platform and partnering on this post.
💬 Have you ever tried building your own full-scale auth? 💭
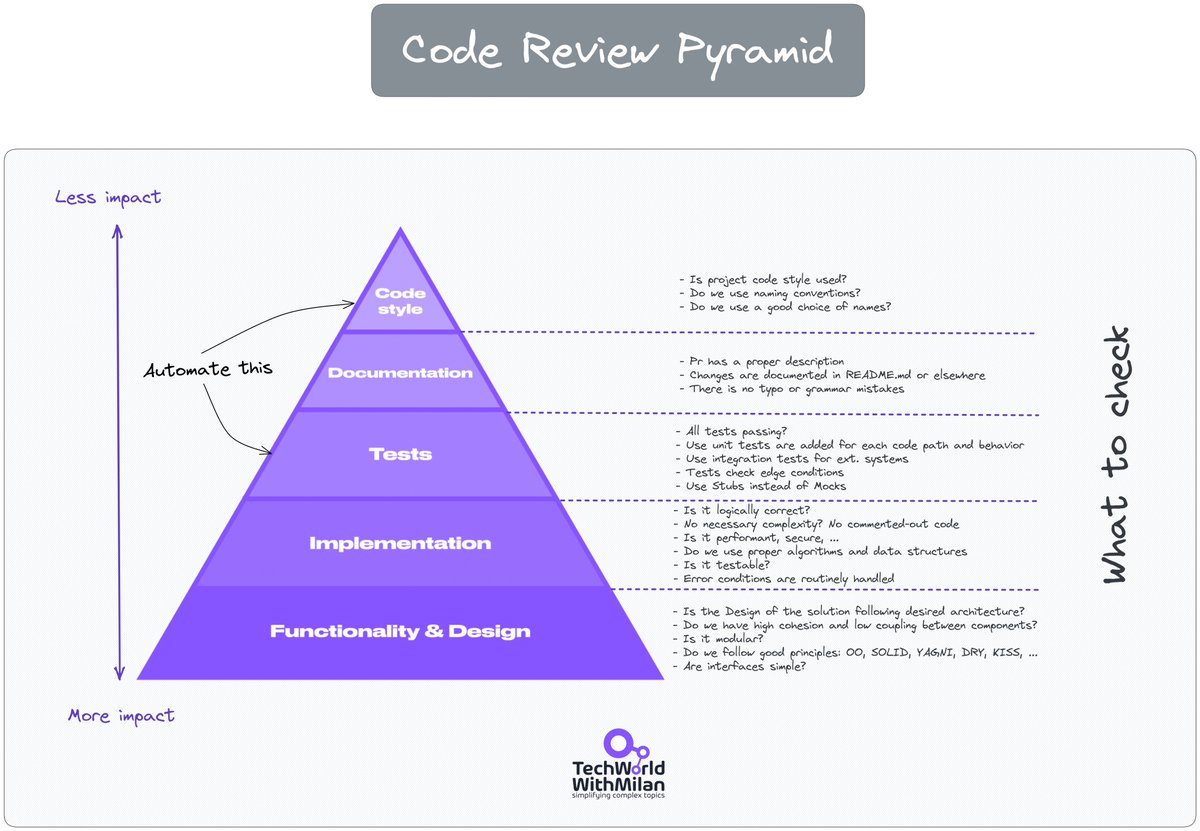
@milan_milanovic Exactly! Great reviewers see the bigger picture—purpose, implementation, and standards—not just code lines. Clear context and kindness make all the difference.
𝗚𝗼𝗼𝗱 𝗰𝗼𝗱𝗲 𝗿𝗲𝘃𝗶𝗲𝘄𝗲𝗿𝘀 𝗱𝗼𝗻'𝘁 𝗿𝗲𝗮𝗱 𝗹𝗶𝗻𝗲-𝗯𝘆-𝗹𝗶𝗻𝗲
Instead, they constantly sync three layers:
𝟭. 𝗣𝘂𝗿𝗽𝗼𝘀𝗲 (What problem are we solving?)
𝟮. 𝗜𝗺𝗽𝗹𝗲𝗺𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 (How does the solution work?)
𝟯. 𝗦𝘁𝗮𝗻𝗱𝗮𝗿𝗱𝘀 (Does it fit our quality bar?)
Great reviews start from understanding, not syntax.
Your strongest feedback emerges when these layers mismatch.
Want code reviews to matter?
✅ 𝗔𝗹𝘄𝗮𝘆𝘀 𝗽𝗿𝗼𝘃𝗶𝗱𝗲 𝗰𝗹𝗲𝗮𝗿 𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗮𝗻𝗱 𝗴𝗼𝗮𝗹𝘀
✅ 𝗕𝗿𝗲𝗮𝗸 𝘆𝗼𝘂𝗿 𝘄𝗼𝗿𝗸 𝗶𝗻𝘁𝗼 𝗳𝗼𝗰𝘂𝘀𝗲𝗱, 𝗿𝗲𝗮𝗱𝗮𝗯𝗹𝗲 𝗰𝗵𝘂𝗻𝗸𝘀
✅ 𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗲 𝘁𝗿𝗶𝘃𝗶𝗮𝗹 𝗰𝗵𝗲𝗰𝗸𝘀 (𝗹𝗶𝗻𝘁𝗶𝗻𝗴, 𝗳𝗼𝗿𝗺𝗮𝘁𝘁𝗶𝗻𝗴)
✅ 𝗖𝗼𝗺𝗺𝗲𝗻𝘁 𝘄𝗶𝘁𝗵 𝗸𝗶𝗻𝗱𝗻𝗲𝘀𝘀
Your reviews shape the team's coding culture.
👉 Read more about code reviews: newsletter.techworld-with-milan.com/p/how-to-do-co….
#softwareengineering#programming#coding
@rohanpaul_ai Fascinating! Teaching LLMs to self-reflect and debug boosts accuracy big time without extra data or bigger models. It’s like giving them a built-in troubleshooting skill—game changer for smarter AI!
Training an LLM to talk itself (self‑reflection) through mistakes can lift accuracy by up to 34.7%, turning a 7B‑parameter model into a giant‑killer.
The study tackles the headache of models that know the tool list or the math rules yet still fumble, by teaching them to reflect, try again, and pocket a reward when the retry works.
🧐 Why bother with self‑reflection?
And Self‑reflection works because it turns 1 bit of pass/fail feedback into many tokens of useful training signal.
Even strong models freeze when a task gives nothing but a yes‑or‑no grade.
There is no pile of new examples to fine‑tune on, and no larger “teacher” model to imitate. The team behind the paper bets that the model’s own commentary can stand in for missing data. If the commentary gets better, the second attempt should land more often.
🔁 How Reflect, Retry, Reward works
- The model answers.
- An automatic checker says pass or fail.
- On failure, the model writes a short self‑reflection, then answers again with that text in context.
- If the new answer passes, only the reflection tokens earn a GRPO reward. Nothing else learns.
That tiny twist keeps the training task‑agnostic. The model is not memorising new function signatures or equations, it is learning how to think about its own mistakes.
In plain words, the model learns how to debug itself. By saying out loud why its first try failed, then getting reinforced when that self‑diagnosis leads to a fix, the model internalises patterns of mistake detection and repair. Once those patterns are baked in, they kick in early, lifting accuracy without extra compute.
🧵 Read on 👇
So, what exactly is an "agent"?
I've spent a ton of time trying to define this because nobody seems to be on the same page. Anthropic's definition is my favorite one by far.
We have 3 different concepts:
1. Agentic systems
2. Agentic workflows
3. Agents
Let's define them one by one:
AGENTIC SYSTEMS
"Agentic systems are intelligent systems that combine large language models with additional capabilities to perform tasks with minimal human oversight."
Basically, an agentic system is the broader category that covers any application that uses augmented LLMs to solve a problem.
An agent is an agentic system. An agentic workflow is also an agentic system.
AGENTIC WORKFLOWS
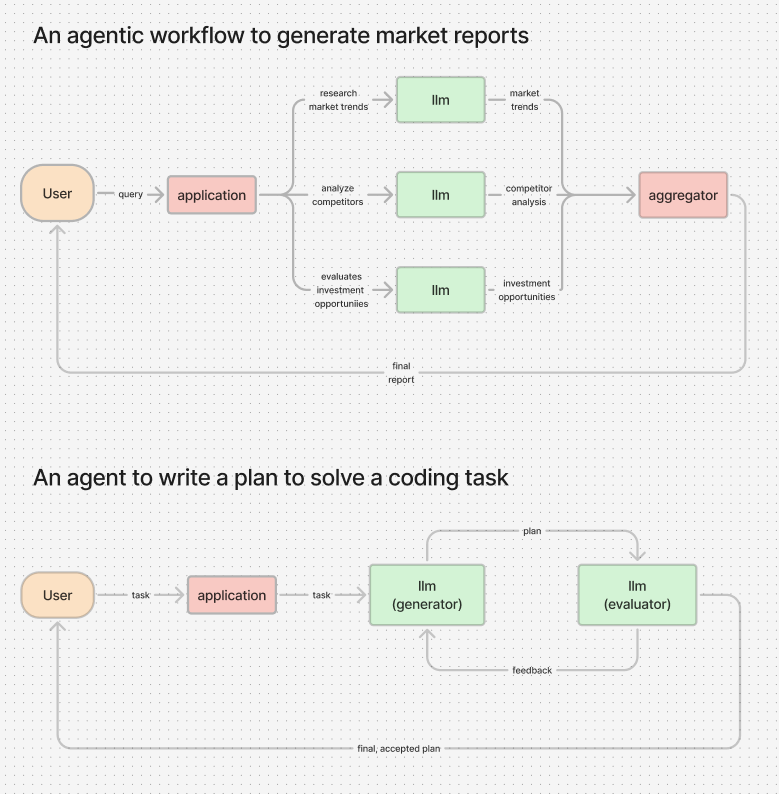
"Agentic workflows are applications that follow a predefined code path. They are simple, predictable, and consistent for solving well-defined tasks."
An agentic workflow is not an agent, and this is what I see many people get wrong.
The main difference here is that agentic workflows use hardcoded rules to solve problems. They don't give the LLM any agency.
Attached, you'll see an example of an agentic workflow that generates market reports. Notice how the workflow uses predefined branches to solve the task.
AGENTS
"Agents are systems capable of performing tasks dynamically and autonomously. They offer flexibility and model-driven decision-making at scale."
The key words here are "Model-driven decision-making".
Attached is an example that shows a simple agent that writes a plan to solve a coding task. We have two LLMs working together to generate and refine the plan until it's complete.
Something important:
I did not represent the use of tools and memory in any of these diagrams. They are pretty crucial for any agentic system!
As I mentioned earlier, I care more about implementing these concepts than defining them, but I still need to teach my students what they all mean.
If you have an idea to improve these definitions or if you notice something unclear, please let me know.
Another Chinese lab (Zai) has released a powerful new model
GLM-4.5 is on par with Opus 4 and VERY strong in coding and agentic tool use 🔥
→ Open source
→ 32B active parameters
→ Lighter version GLM-4.5 Air
→ Hybrid reasoning models
You can already use them for free ↓
🚀 Beginner’s Roadmap to Web Dev
From HTML/CSS basics to deploying your first site — here’s how to start strong:
1️⃣ HTML, CSS, JS
2️⃣ VS Code & browser
3️⃣ Build projects
4️⃣ Git & GitHub
5️⃣ Frameworks
6️⃣ Deploy
7️⃣ Keep learning
#WebDevelopment#LearnToCode#GitHub#CodingJourney
@goyalshaliniuk Super helpful breakdown! Clear levels like this make it easy to track progress and build smarter agents step by step. Exciting to see how fast we're moving toward full autonomy!
Want to get a quick idea about the different levels in AI Agents ?
Here’s a breakdown of AI agent capabilities into 3 clear levels, from basic to fully autonomous.
Let’s simplify it:
1. Basics
Start here if you’re new.
Understand how LLMs like GPT work, use prompt engineering, APIs, and simple tools like calculators or vector search.
2. Intermediate
This is where agents get smarter.
They start using functions, calling tools, managing memory, and reasoning through multi-step tasks. Frameworks like LangChain come into play here.
3. Advanced
At this level, agents act almost human.
They plan, self-learn, adapt through reinforcement learning, and collaborate in multi-agent workflows, working toward complete autonomy.
AI agents are evolving fast. Knowing where you (or your tool) stand on this pyramid helps you build, evaluate, and scale smarter AI solutions.
@TheTuringPost@googlecloud Fascinating approach! Mimicking the human research loop with denoising + self-evolution is a smart move. Excited to see TTD-DR push the boundaries beyond even OpenAI’s Deep Research!
Diffusion enhances Deep Researchers
Test-Time Diffusion Deep Researcher (TTD-DR) is a new method by @googlecloud that enhances research reports quality, using:
- Denoising with retrieval:
It starts with a rough draft and then improves it with new info as a unified object
- Self-evolution:
Optimizes the performance of each small task and component within the research process, like plan, questions, answers.
This back-and-forth loop of planning, drafting, researching more, and revising is more similar to how humans write and achieves results even better that OpenAI Deep Research!
Here's how it works in 3 stages:
@akshay_pachaar That’s a game-changer! Full codebase indexing + semantic search = massive boost in coding accuracy. Can’t wait to try it with Claude Code!
Make Claude Code 10x more powerful!
Code Context is an MCP plugin that brings semantic code search to Claude Code, Gemini CLI, or any AI coding agent.
Full codebase indexing means richer context and better code generation.
100% open-source.