Sabitlenmiş Tweet

🚀PaddleOCR-VL-1.5 is here!— A New SOTA for Document Parsing!
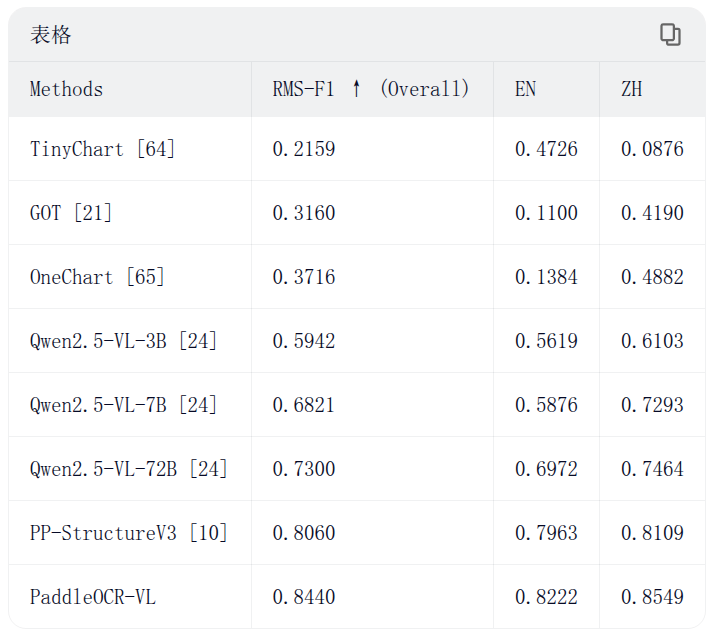
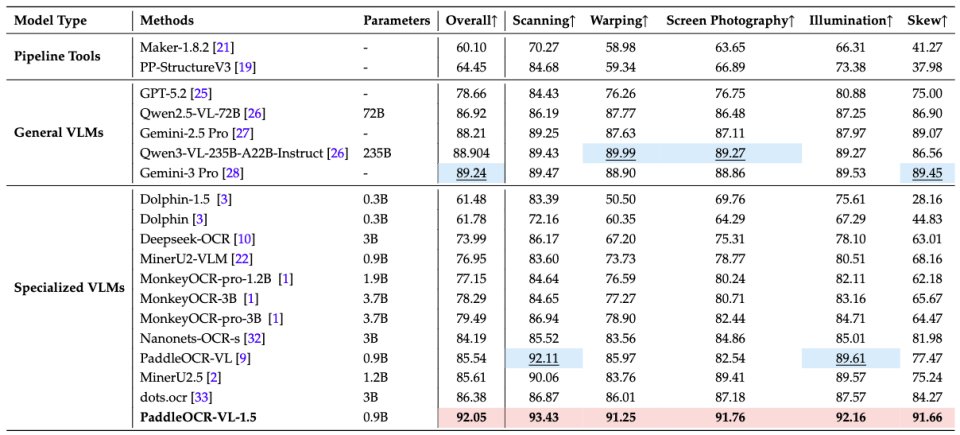
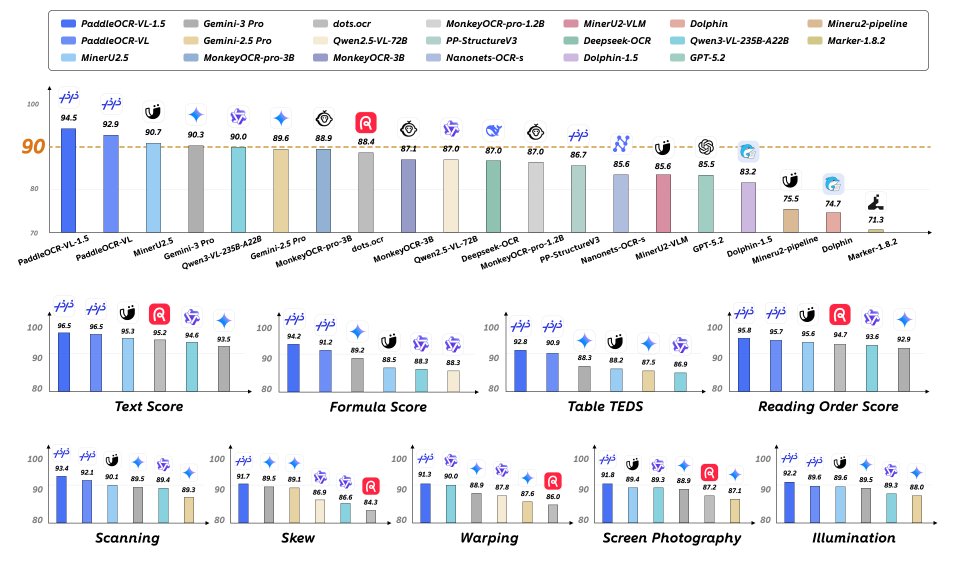
🔍 94.5% accuracy on OmniDocBench v1.5 with just 0.9B parameters, outperforming leading general-purpose LLMs and document-specific models under standardized benchmarks.
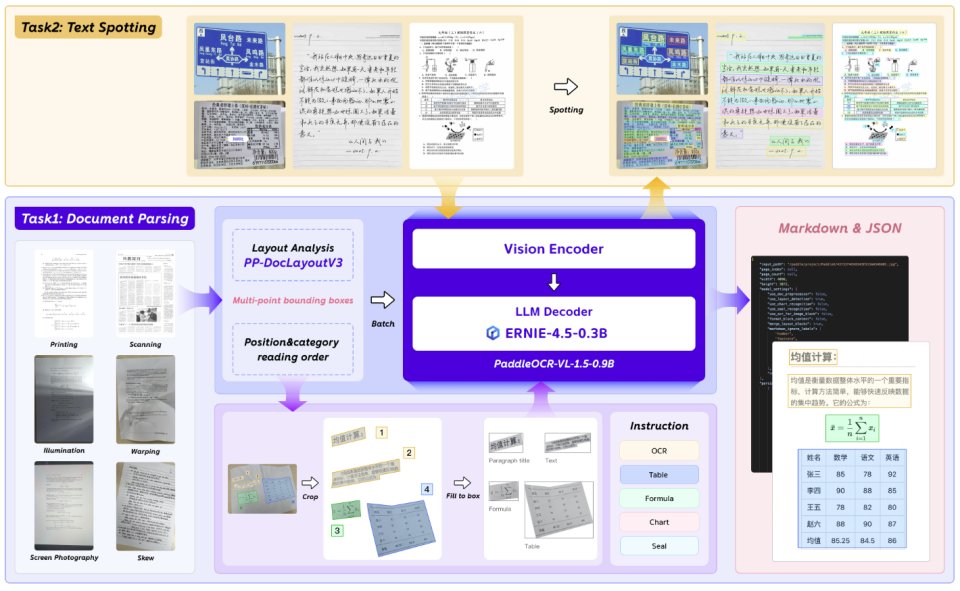
📐 Irregular-shaped localization delivers robust parsing across real-world conditions—scans, skewed or warped pages, screen photos, and challenging lighting—achieving comprehensive SOTA results
🧾 Text spotting + seal recognition, both reaching new state-of-the-art performance, alongside major gains in table, formula, and text recognition.
🌍 Stronger multilingual & specialized support: rare characters, ancient texts, multilingual tables, underlines, checkboxes—now with extended coverage including Tibetan and Bengali.
📄 Built for long documents with automatic cross-page table merging and heading recognition, reducing fragmentation at scale.
🔥Smarter. More robust. Production-ready.
PaddleOCR-VL-1.5 sets a new bar for real-world document intelligence.
How to Use⬇️
Official Website/ API 👉 paddleocr.com
Open-source Repository 👉github.com/PaddlePaddle/P…
Model Download 👉 huggingface.co/PaddlePaddle/P…
#PaddleOCR #OCR

English