blank
561 posts


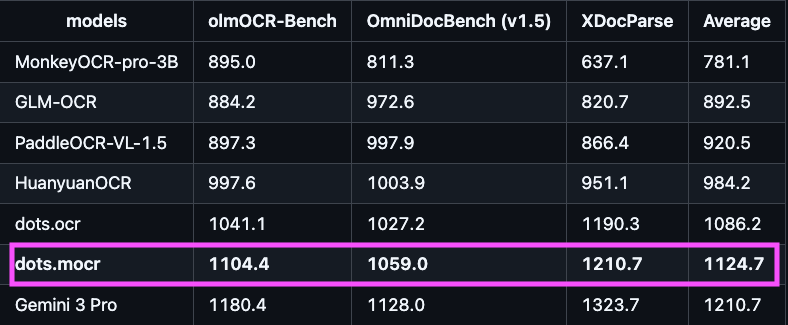
Another OCR model just dropped on @huggingface (so many OCRs lately!)
dots.mocr from @xiaohongshu Hi Lab looks really impressive on the benchmarks.
-Model: huggingface.co/collections/re…
-Paper: huggingface.co/papers/2603.13…
✨ 3B
✨ Multilingual support
✨ Converts charts, diagrams, and UI layouts directly into SVG code
English
@PaddlePaddle Dm me I want to share urdu datasets with you because your model is useless for urdu documents

English

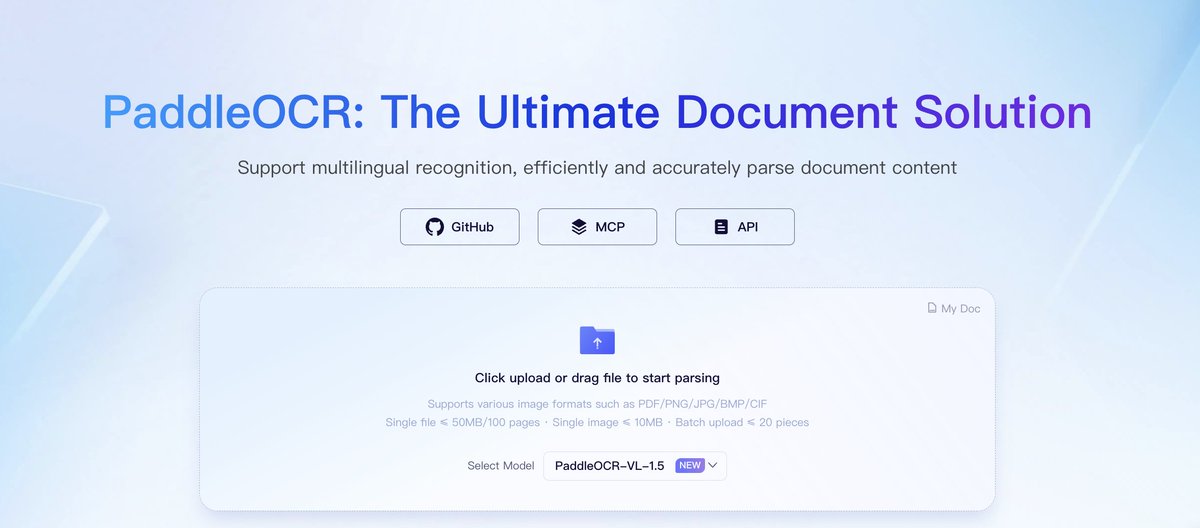
🚀 Big Upgrade: PaddleOCR Website Just Got a Major Boost!
More pages. Faster parsing. Better batch workflows.
The latest PaddleOCR website update is built for real-world document workloads — from long PDFs to high-volume processing.
What’s new
📄 10,000 free pages/day for individual users
⏱️ New async parsing service for long documents and heavy jobs
📚 Up to 1,000 pages per file — no more splitting large PDFs
⚙️ Stronger concurrency & batch processing with a major backend upgrade
Why it matters
With async service and higher throughput, PaddleOCR now handles long and large-scale document parsing far more efficiently — making enterprise-grade OCR workflows easier to access, test, and scale.
🌐 Try it now: paddleocr.com
💬 Feedback: paddleocr@baidu.com
🔧 GitHub: github.com/PaddlePaddle/P…
And with PaddleOCR Skills already live on ClawHub, your OpenClaw workflows can now process documents even faster and better.💪
#PaddleOCR #OCR #DocumentAI #OpenSource #ClawHub

English
@VikParuchuri Very bad with urdu docs I got datasets dm me I send u folder link
English

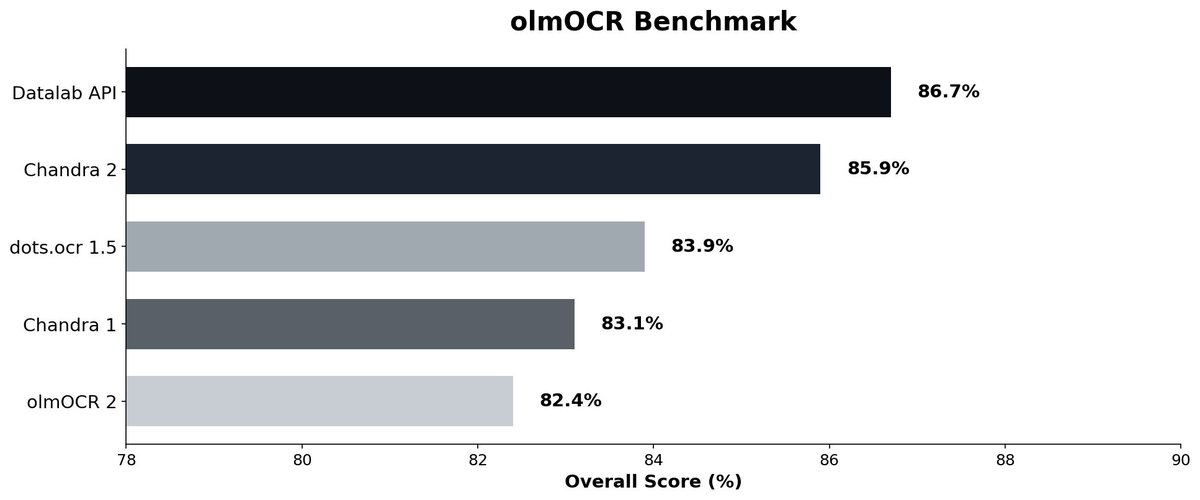
I'm excited to open source Chandra OCR 2!
- 85.9% (sota) on olmocr bench
- 90+ language support w/benchmarks
- 4B model (down from 9B)
- Full layout information
- Extracts + captions images and diagrams
- Strong handwriting, math, form, table support
English

I have successfully cleansed my account of indians. i live in peace again. I have blocked 100 accounts or so.
English
@vanstriendaniel @rednotehilab @huggingface Best model I test my language urdu handwritten notes and it improves alot from previous version I shared those urdu datasets with its developer other models are way behind latest glm ocr is shit in urdu documents
English

dots.ocr-1.5 from @rednotehilab wasn't on @huggingface yet, so I mirrored it from ModelScope
3B OCR model:
- 83.9% olmOCR-bench
- Web/scene text parsing
- 100+ languages, MIT-based
Ready-to-run UV script included
huggingface.co/davanstrien/do…
English

GLM-OCR has accumulated over 3M downloads. We are releasing its technical report: arxiv.org/abs/2603.10910
We welcome your feedback!
English


‼️ Very interesting: Iran's newly elected Supreme Leader Ayatollah Mojtaba Khamenei's account appears to be based in the Netherlands 👀
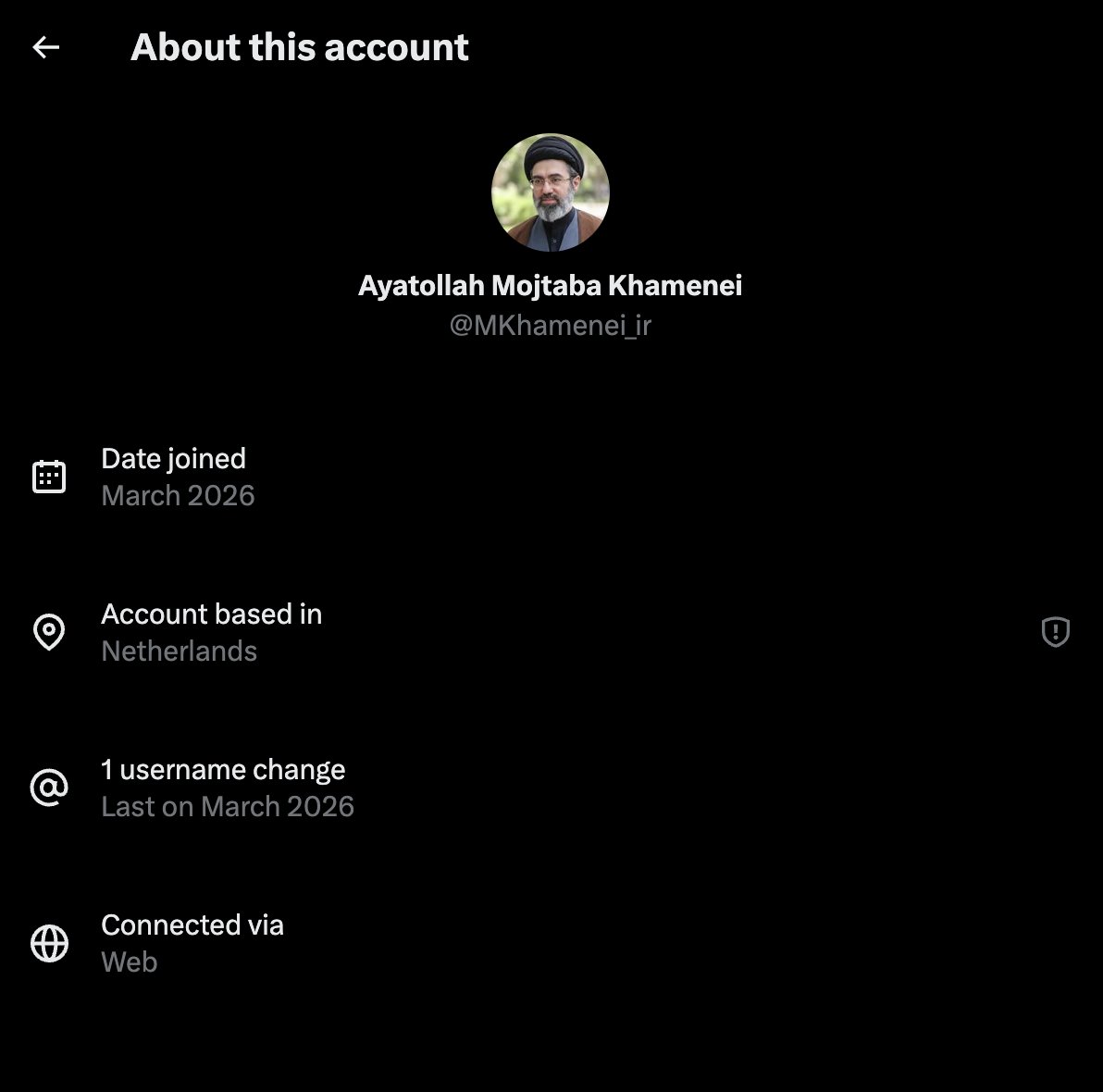
English

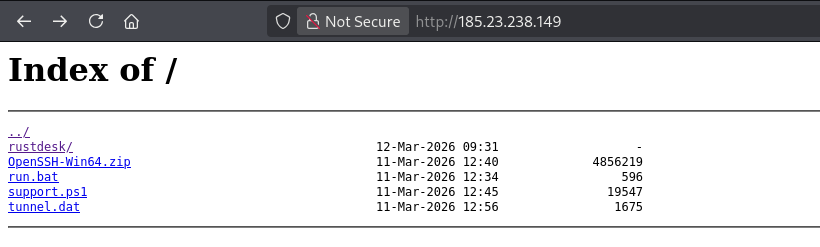
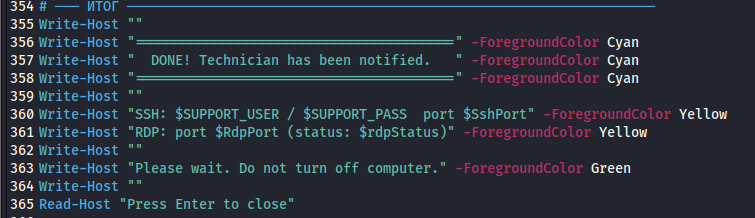
Why does this Russian support technician want to disable my antivirus?
Well, I'll leave it at that.
telegram bot token: 8617483102:AAGkFE-x8Z81Ex-PtnzkMURy1-1CI3KGpdU
$CHAT_ID = "-5185728008"
bazaar.abuse.ch/sample/d756d1e…
#opendir
English

One of the seven members of the Iranian women’s football team delegation who was granted asylum in Australia has changed her mind and asked to return to Iran.
The player initially chose to stay in Brisbane but later contacted the Iranian embassy after speaking with teammates who had already left.
Australian Home Affairs Minister Tony Burke said officials confirmed the decision was voluntary and arranged for her return.
Source: Australian Broadcasting Corporation

English

پاکستان نے ایران فون کرکے امریکی و اسرائیلی حملے کی مذمت کی ہے جبکہ سعودی عرب فون کرکے ایرانی حملے کی۔
پاکستان نے کہا ہے کہ وہ امریکی حملے کے خلاف ایران کے ساتھ کھڑا ہے جبکہ ایرانی حملے کے خلاف سعودی عرب کے ساتھ۔
بیان دیکھ کر ایران و سعودی عرب دونوں نے کھڑے ہونے پر پاکستان کا شکریہ ادا کیا اور اسے بیٹھ جانے کو کہا.
(منقول)
اردو
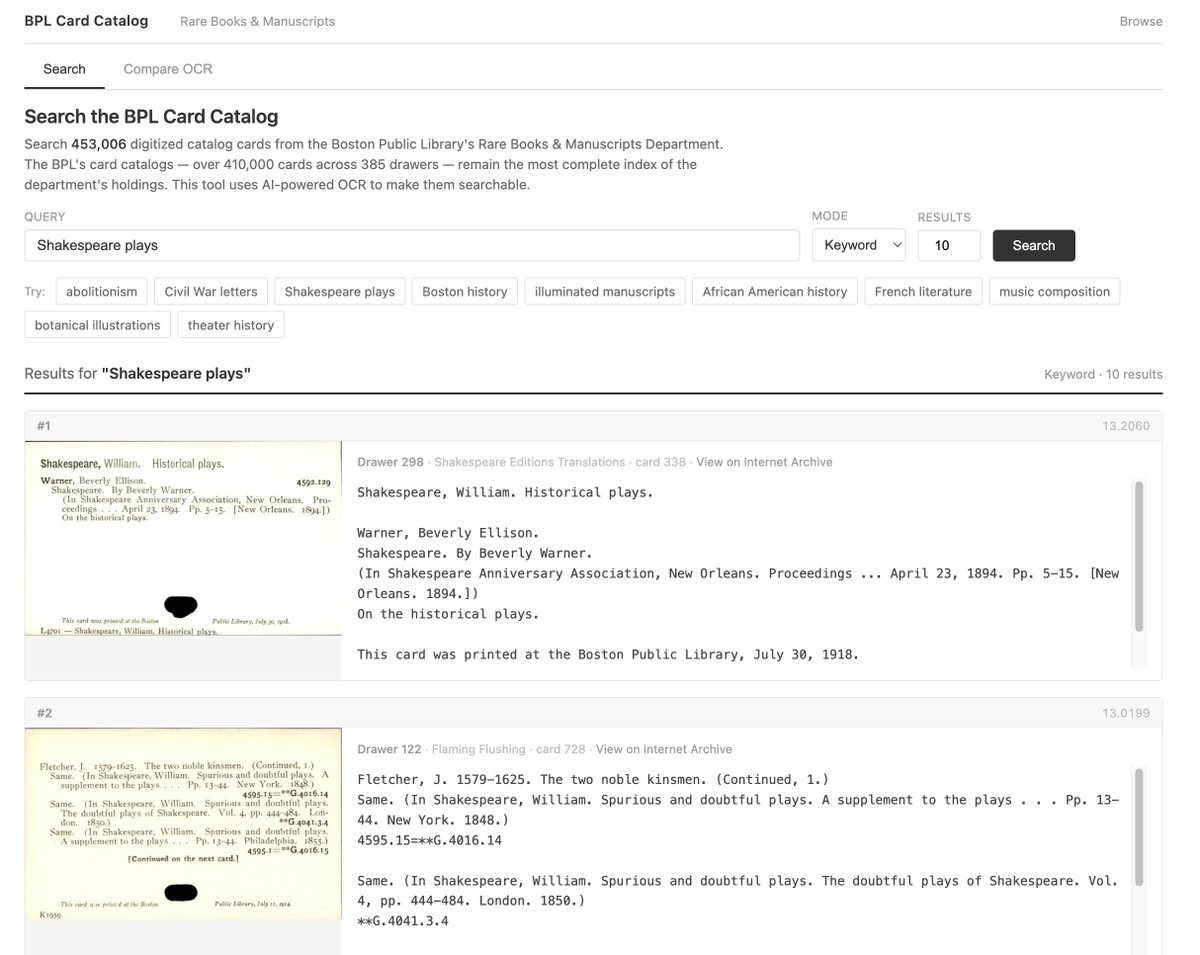
Is it worth re-OCR'ing old library index cards?
Re-OCR'd 453,000 from Boston Public Library's rare books catalogue.
~$50 compute using @huggingface Jobs
BPL's own guide calls their search "extremely unreliable." Does better OCR and semantic search fix it?
Demo link below

English

New Model:
huihui-ai/Huihui-Qwen3.5-35B-A3B-abliterated
This is an uncensored version of Qwen/Qwen3.5-35B-A3B created with abliteration
huggingface.co/huihui-ai/Huih…
English
@vanstriendaniel Only dots. Ocr latest will work make post if some one downloaded 1.5 they have model files to share with you
English
Everyone kept telling me Gemini Pro would do a perfect job but the results are not that great. Scaling this to millions of pages would also be insanely expensive and slow.

English
Ran the same OCR models on 68 pages of historic newspaper. Every model hallucinated or looped.
DeepSeek-OCR-2, LightOnOCR-2, GLM-OCR – all melt down on dense newspaper columns.
You can try yourself using this @huggingface dataset:
huggingface.co/datasets/davan…

Daniel van Strien@vanstriendaniel
Re-OCR'd the complete 1771 Encyclopaedia Britannica (2,724 pages) with a single command on @huggingface Jobs. - 0.9B model (GLM-OCR) ~$0.002/page ~$5 total on an L4 GPU Before (old Tesseract ocr) → After:
English

While others use manual tools for recon or run Google dorks to find leaked data on target websites, this AI tool does everything by itself. You just provide the web link & ask it to look for leaked IDs or any exposed information. It automatically searches the internet .
English
blank retweetledi

Here is how I find someone’s deleted Tweets on X/Twitter 🐦💻
I used to manually search for someone’s username across search engines 🔍, hoping to find a cached tweet 🗂️
Recently, a new website allows you to automatically search for cached tweets across multiple search engines and archival services ⚡🌐
The tool is called Deleted Tweet Finder V2.3 🛠️
You can access it here: 🌐 cache.digitaldigging.org
Here’s how to use it:
1. Visit the website 🖥️
2. Enter the person’s X/Twitter URL or the URL of a tweet they made 🔗
3. Select the service ✅
4. Click on “Go” ▶️
This will open a new tab with the service you selected and search for the profile or tweet 🗂️🔎
Note ⚠️: Since X acquired Twitter, it’s recommended to search for a tweet/profile using both the x.com and x.com domain names 🌐
Example:
Username: cyber_sudo 🧑💻
First URL: x.com/cyber_sudo
Second URL: x.com/cyber_sudo
____________________
P.S. ♻️ Repost if you found this helpful.
If you liked this post, get weekly OSINT tips by joining the OSINT Observer Newsletter, with over 5,000 OSINT enthusiasts: cybersudo.org. Plus, there’s a welcome gift waiting for you!
English
@naveedullah600 @ZenomTrader Naveed bro can u make mq5 indicator or semi auto ea from this nt8 code
English
AI agents are on another level.
I asked Claude Code to build a Gold strategy in NinjaTrader 8 from scratch.
It wrote the code, compiled it, debugged itself, ran the backtest, optimized it and delivered a profitable system.
Fully autonomous.
Very few are operating like this.
English

Match, Hinge and OKCupid usage data leaked by ShinyHunters
10 million records released


English