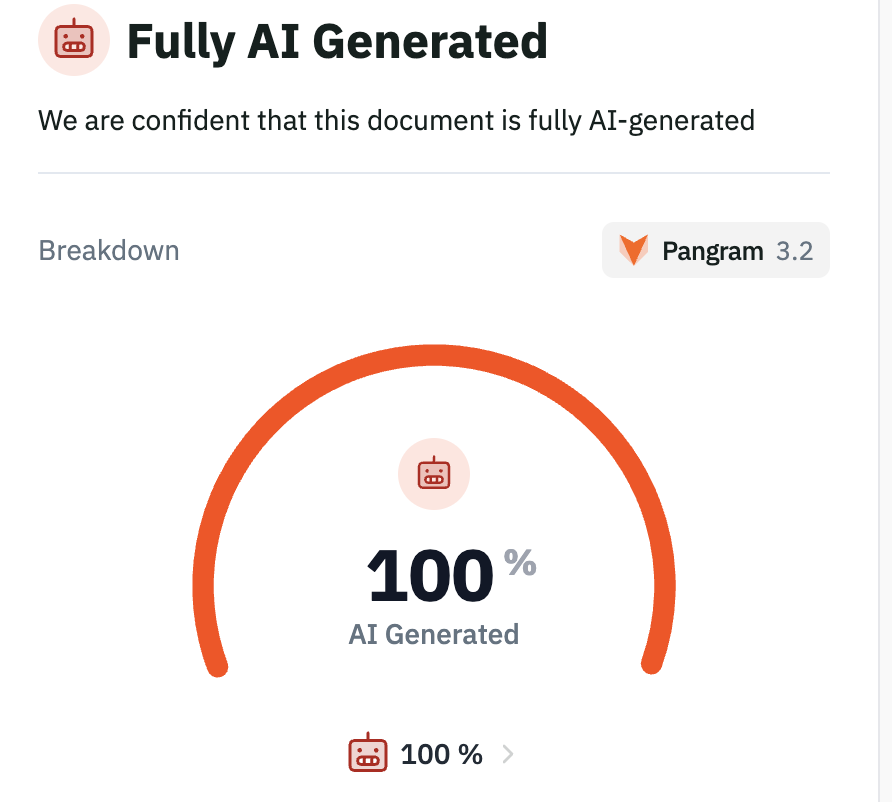
@thdxr This is much more common on LinkedIn. Just take any post longer than 75 words and put it on pangram and you will find this. Even the commenters have their comments AI generated 🙂
English
Param Thakkar
365 posts

@Param23072004
Playing with Reinforcement Learning, World Models + GPUs, CS undergrad @ Veermata Jijabai Technological Institute, Mumbai,Independent contractor @transformerlab






Direct link to the piece here: notboring.co/p/world-models





discover the complexities of the humanoid supply chain on Atlas! humanoids.fyi
Alec Radford has 190,000+ citations, no PhD, no master's degree, and 34,000 Twitter followers. Sam Altman called him an Einstein-level genius. Wired compared his role at OpenAI to Larry Page inventing PageRank. He still prototyped most of his work in Jupyter Notebooks. The resume is staggering when you list it out. GPT-1: first author. GPT-2: first author. CLIP: primary author. Whisper: co-author. DALL-E: co-author. DCGAN: co-author. Contributing researcher on GPT-3, GPT-4, and DALL-E 2/3. Multiple U.S. patents owned by OpenAI. He joined in 2016 with a bachelor's degree from Olin College, a school founded in 1997 with fewer than 400 students. His first experiment at OpenAI was training a language model on 2 billion Reddit comments. It failed. But the organization gave him room to keep going. Two years later he built GPT-1 alone, based on what colleagues described as pure technical intuition. He couldn't fully explain how it worked at the time. He just knew it would. At NeurIPS 2024, Ilya Sutskever singled out two people as responsible for the pre-training era: Radford and Dario Amodei. All four original authors of the GPT paper have since left OpenAI. Radford left in December 2024 to do independent research. His last tweet was in May 2021. A reply explaining why GPT-1's layer width was set to 768. The person who built the foundation of a $300B+ industry communicates less publicly than most interns. That ratio between impact and visibility is the strongest signal of who actually does the work versus who narrates it.