Sabitlenmiş Tweet

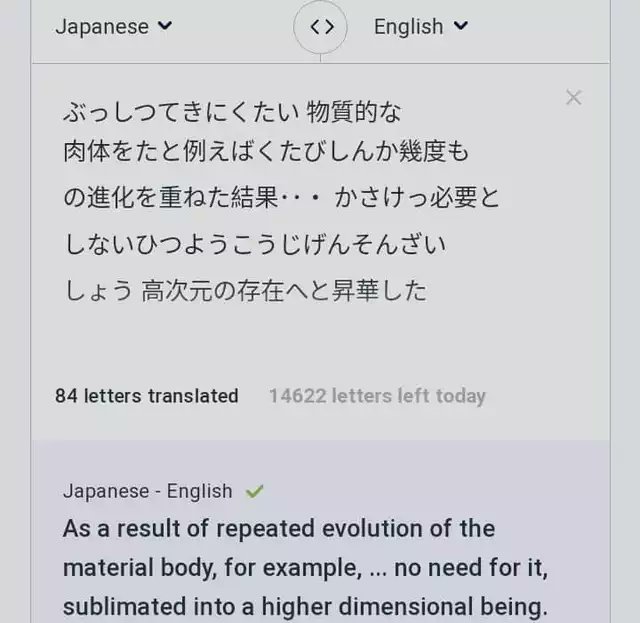
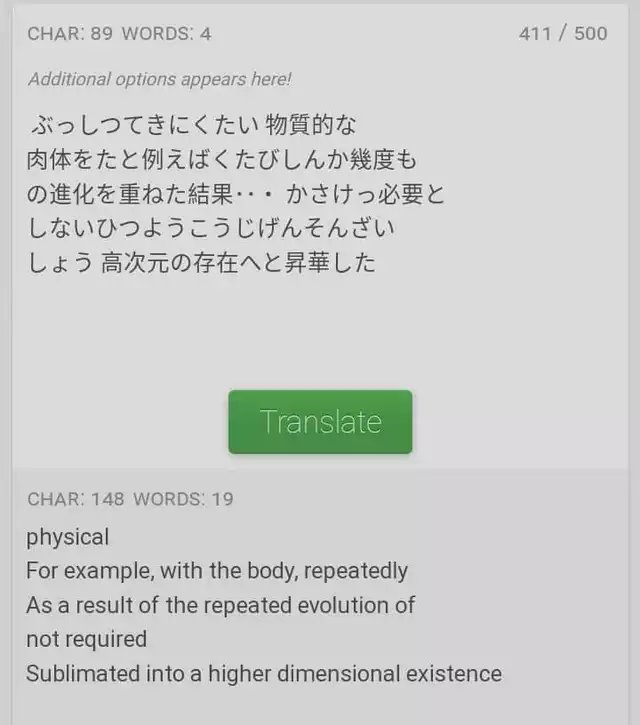
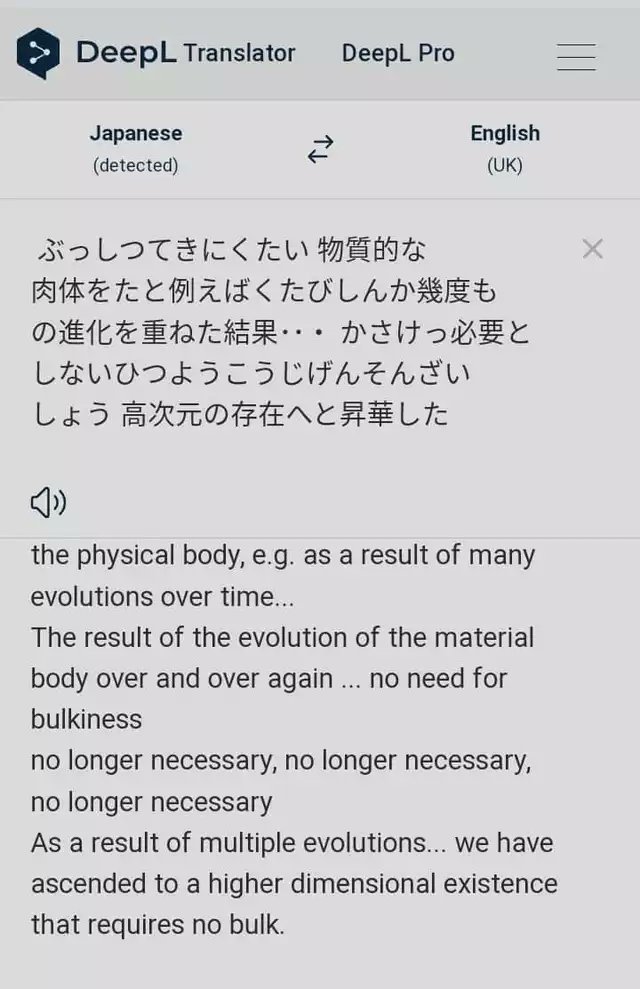
This was a translation of Amado and Isshiki's statement about Shibai's high-dimensional existence. The kanji used is a mathematical high dimension.

English
Dzulfikar Otsusuki
5.7K posts





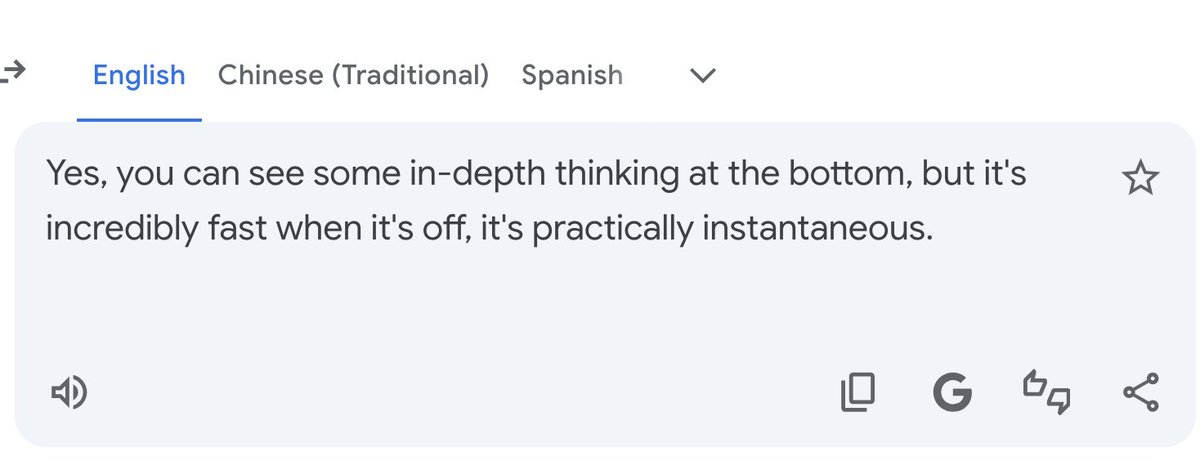
我也有了,秒出我靠,太快了,没有思考过程



Hate on a “series” and it’s a question about one village compared to the numerous villages in the same “series” and the fact that I prefer boogie woogie to Amenotejikara?? Narutards never disappoint in selling wrong narratives

Do you guys consider the Naruto fandom and boruto fandom to be 2 different fandoms?
There are Naruto fans out there that will tell you Naruto dog walked Neji and didn’t win by plot, it is very important that you don’t listen to them

It was because of that excuse is the reason they were able to defeat him with low casualties They strategize and plan to use that weakness against him Why are we still on this topic

Physical stronger ≠ wincon Depending on the situation If your opponent is a better strategist,out haxes you or have better speed, intelligence They can harm you,jigen was outsmarted twice against Naruto and Sasuke it's his hax that saved him twice, even though he is stronger






