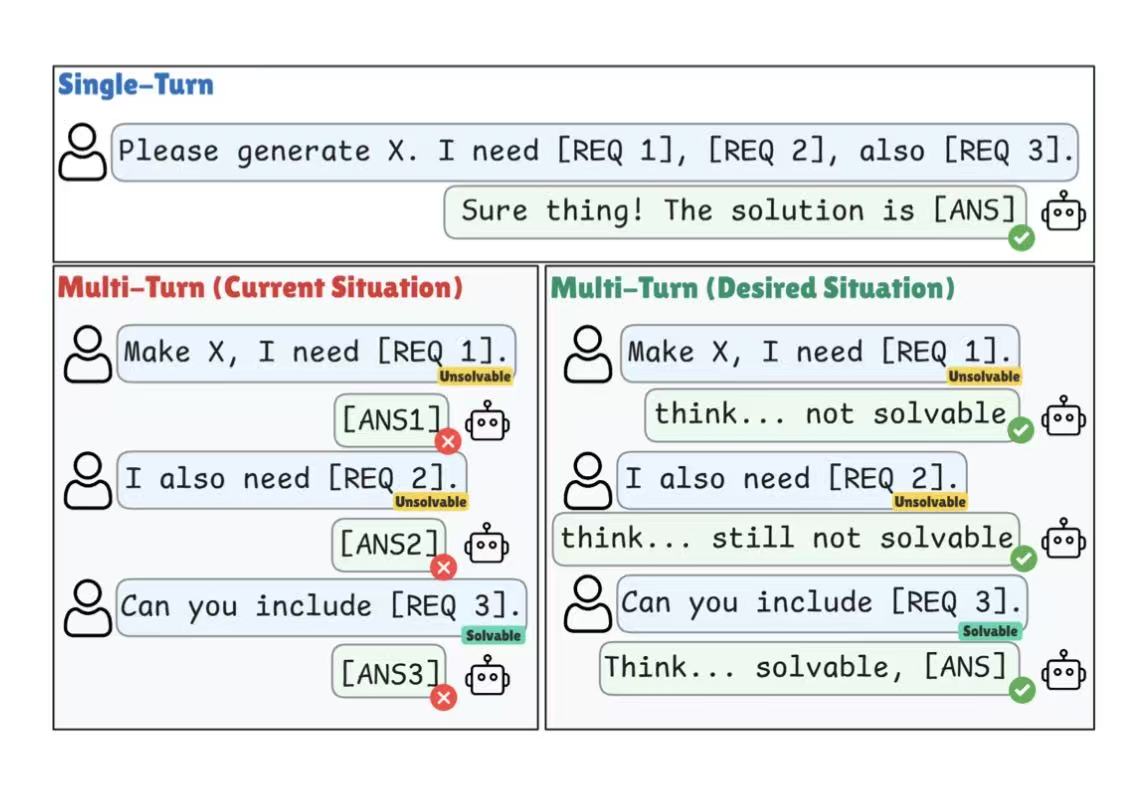
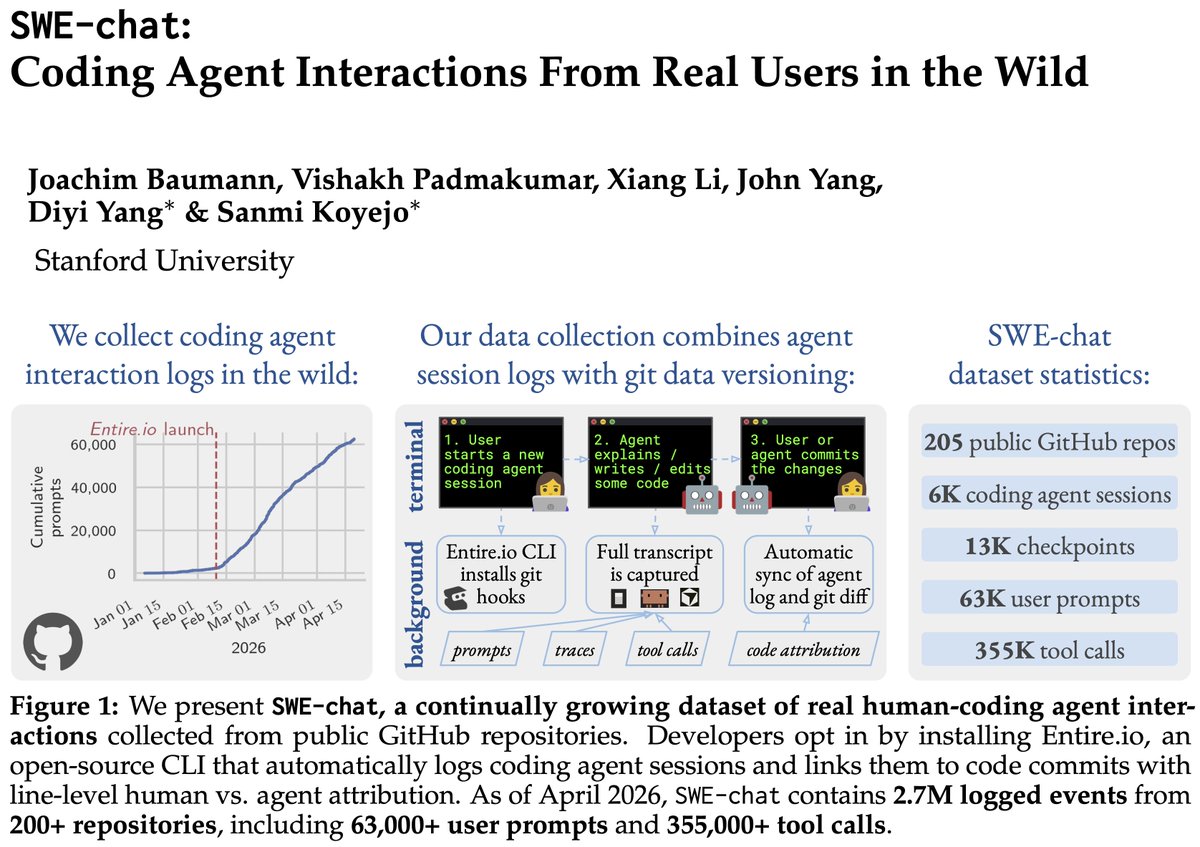
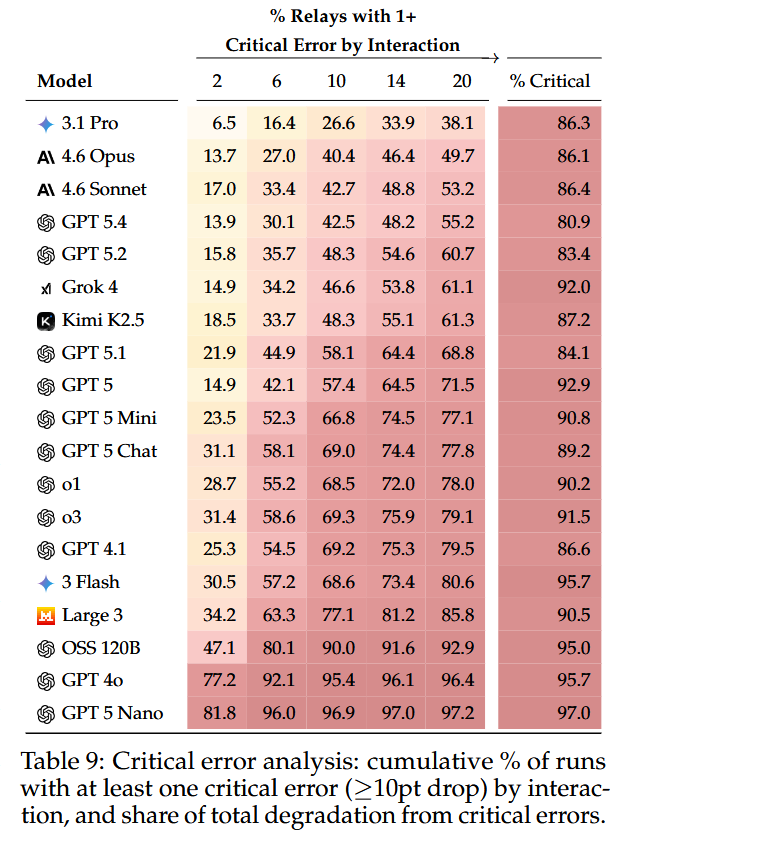
Philippe Laban retweetledi

We've just released open source MTP style drafters for Gemma 4 models ⚡
Now Gemma 4 models are even faster on your choice of hardware, without losing quality!
Grateful for the fruitful collaboration between my team, Gemma team, and many collaborators to enable this release!
Omar Sanseviero@osanseviero
Excited to introduce Gemma 4 Multi-Token Prediction Drafters⚡️Accelerated inference right in your pockets - Up to a 3x speedup - Same quality guarantees - Available in your favorite open-source tools
English