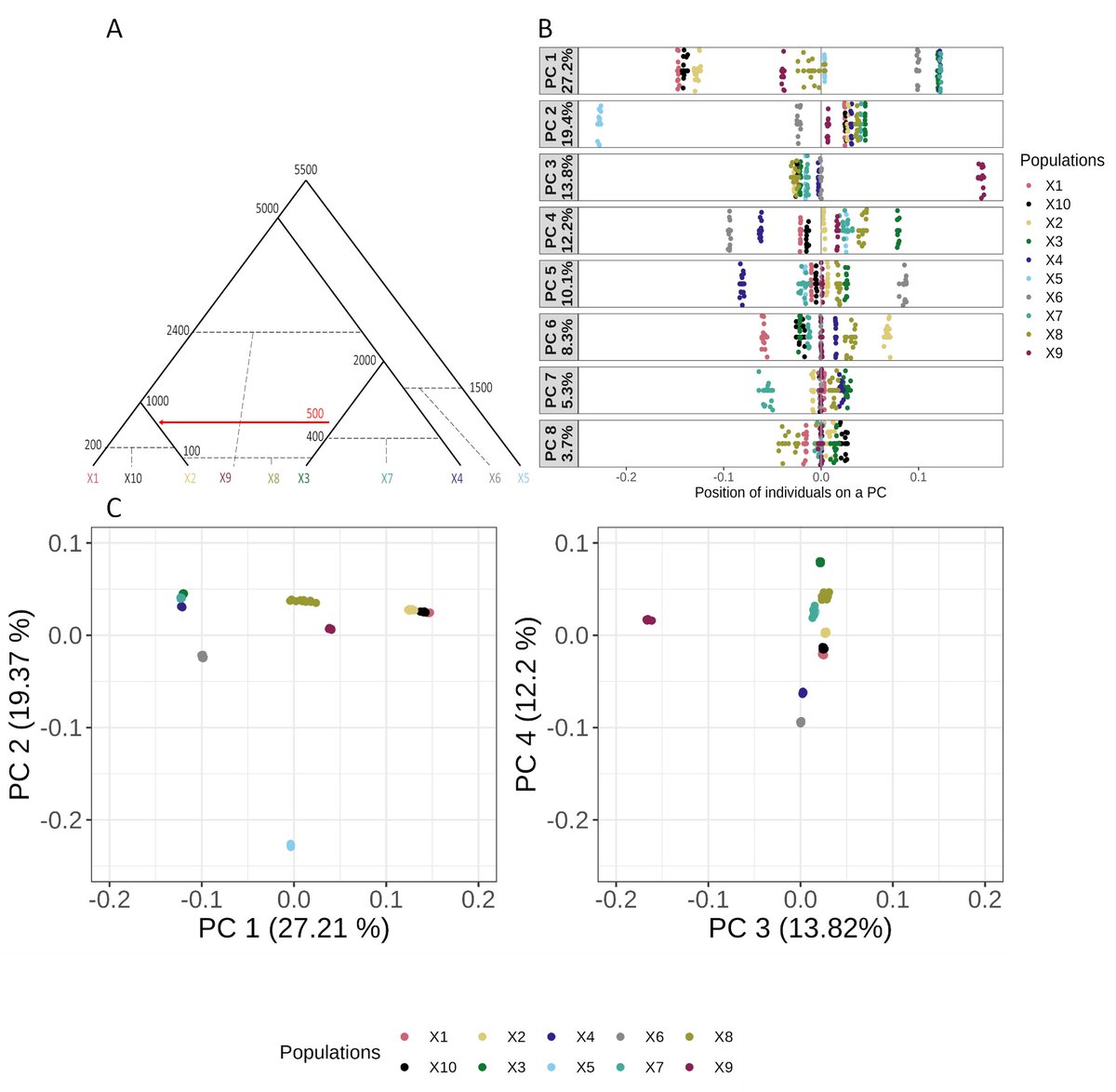
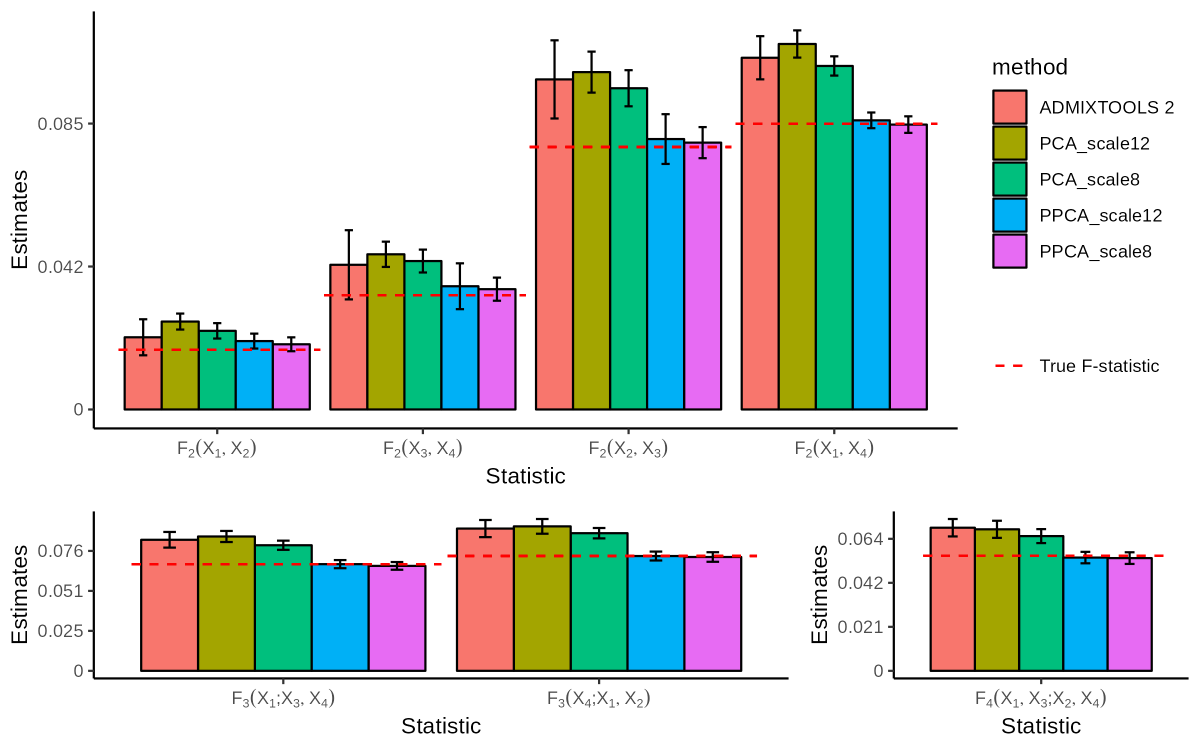
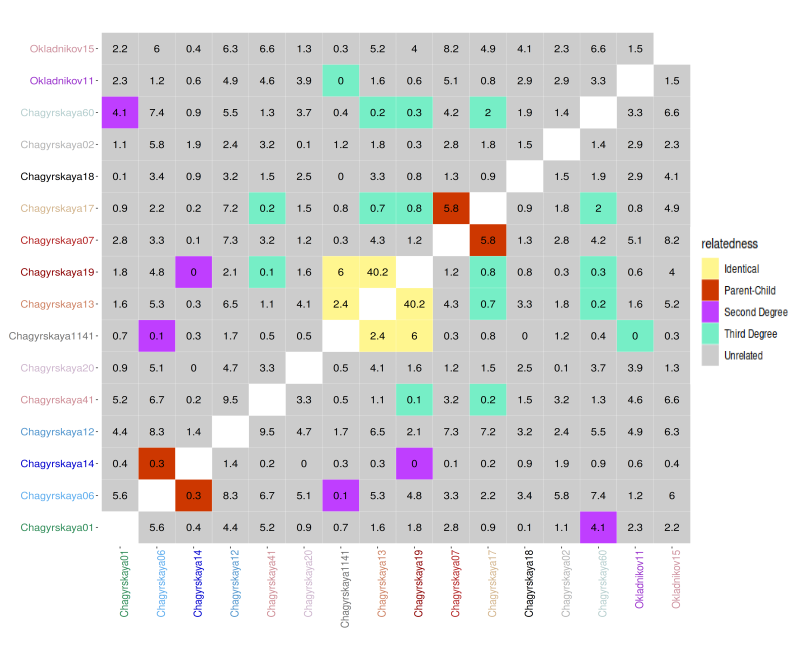
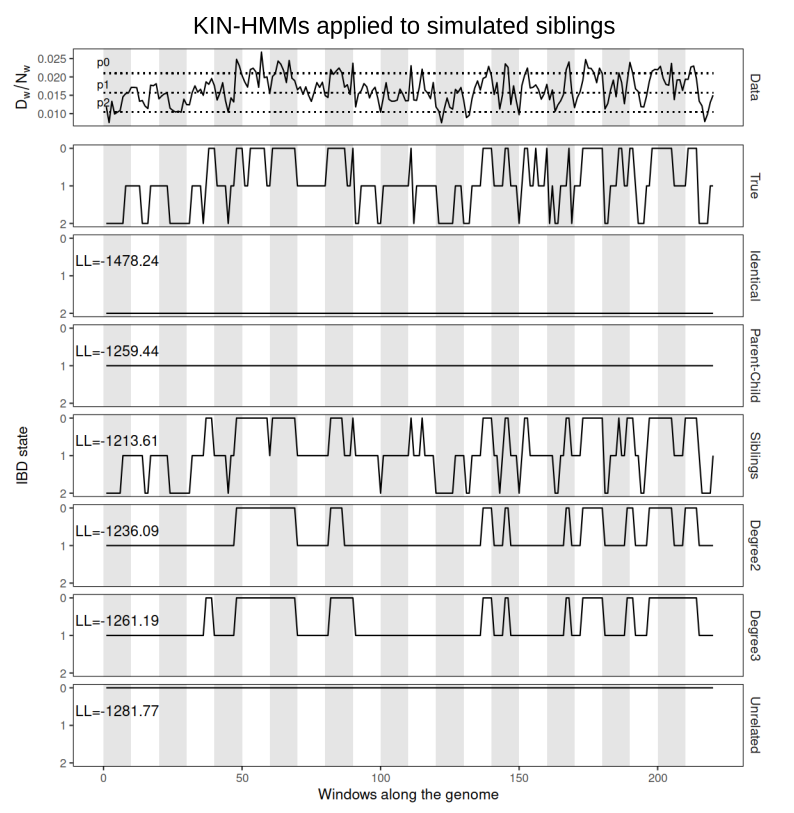
Divyaratan Popli retweetledi

Oldest modern human #genomes sequenced. These seven early #Europeans belonged to a small, isolated group that left no present-day descendants. Study @Nature led by @arevsumer, Kay Prüfer, Johannes Krause @MPI_EVA_Leipzig. tinyurl.com/mryrjyrn & nature.com/articles/s4158…


English