
Prabhat
120 posts

Prabhat
@PrabhatAstrix
20 Software Engineer | Building Shi that actually matters
Bengaluru Katılım Nisan 2022
84 Takip Edilen21 Takipçiler


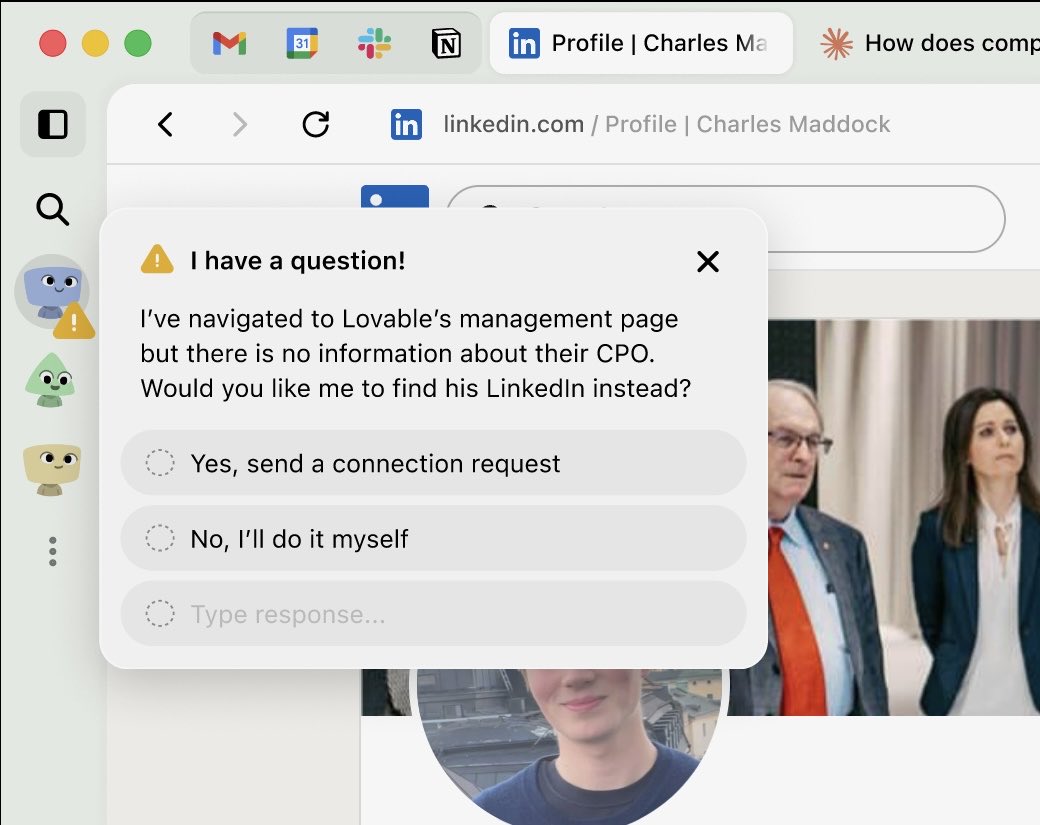
Mock-up for an “agent sidebar” where you can track what your agents are doing
What do you think?


English

Fair enough, that's a solid real-world example. Different projects clearly favor different models depending on the codebase.For me personally, when I was building my Electron desktop app with a lot of complex interconnected features, Opus 4.6 handled it noticeably better. It often got the architecture and implementation right on the first try with fewer regressions.Appreciate you sharing your experience though. Interesting how results can vary so much between projects.
English

@PrabhatAstrix @KaiXCreator In this environment, Codex has been stronger at maintaining test integrity across layers, understanding existing architecture constraints, and shipping changes with fewer regressions in downstream flows.
Benchmarks are useful, but real production codebases tell the real story.
English



@cneuralnetwork That's one of the coolest advice I have seen so far today
English

too much availability kills your value
don't show up to work tomorrow
English
Hi @Jbm_dev , working on my latest product its still in its last stages of being built. If u want to connect and later give me your insights on it before we release then that would be absolutely great!!
Do follow if u wanna connect and I will fb and soon connect with ya about it. Only if ur interested
English

The table mixes GPT-5.4 Thinking/Pro (max effort) with Opus 4.6 and skips some key data. On the most practical coding benchmark, SWE-Bench Verified (real GitHub issues), Claude Opus 4.6 leads at 80.8%, ahead of GPT-5.4's ~80% or lower on similar evals. GPT wins on SWE-Bench Pro (57.7%) and OSWorld (75% vs 72.7%), but those are different variants. Opus 4.6 also edges out on BrowseComp agentic browsing (84% vs 82.7%) and often feels stronger for deep, reliable reasoning and coding in practice. Benchmarks are close overall. No total domination. Depends on the task. What's the specific case where you saw Claude underperform?
English
@PrabhatAstrix @KaiXCreator Could you point to a specific case?
I’m not just referring to my own experience — even advanced benchmarks suggest otherwise — but I’m genuinely curious to see a concrete example where Claude performed better.

English
I don't think coding is everything, though it definitely helps when reviewing things. What really sets a "vibe coder" apart is having a strong understanding of concepts like system design, DevOps, and the logic behind how things actually work. That’s what gives you a real edge over others.
English

For GPT 5.4, I agree with day-to-day coding and maybe code reviews but it still isn't at par with Opus 4.6. I have used both in development of my Desktop App and Opus 4.6 has simply dominated.
GPT 5.4 sure is faster but that also makes it miss key things while Opus 4.6 takes its time but gets the job done.
English
@PrabhatAstrix @KaiXCreator Still debating GPT 5.3 in 2026 feels like debating 1990 tech.
GPT 5.4 has been out for a while and is simply better for complex features, day-to-day coding, and code reviews than Claude.
English



@Bhavani_00007 They often forget
Npm run build
If the AI doesn't do it for them already they will be like issue wasn't fixed
English

Vibe coders are confused by:
- npm install
- npm run dev
- http://localhost:3000/
What else am I missing?
English
@delveroin Ofc that's why I am here xD
Want to connect would like to know ur insights on a product that my cofounder and I are building.
English

@NanouuSymeon Git: Version Control System
GitHub: Extension of Git on Cloud
English




@KaiXCreator As of now stuck at option number 1.
But will soon go to 3 xD
Hi Kaito, let's connect releasing my product soon it's in the last stages of being built but would love to know ur insights on it. Drop a msg if ur interested. 😁
English

