Linea@lineaavey
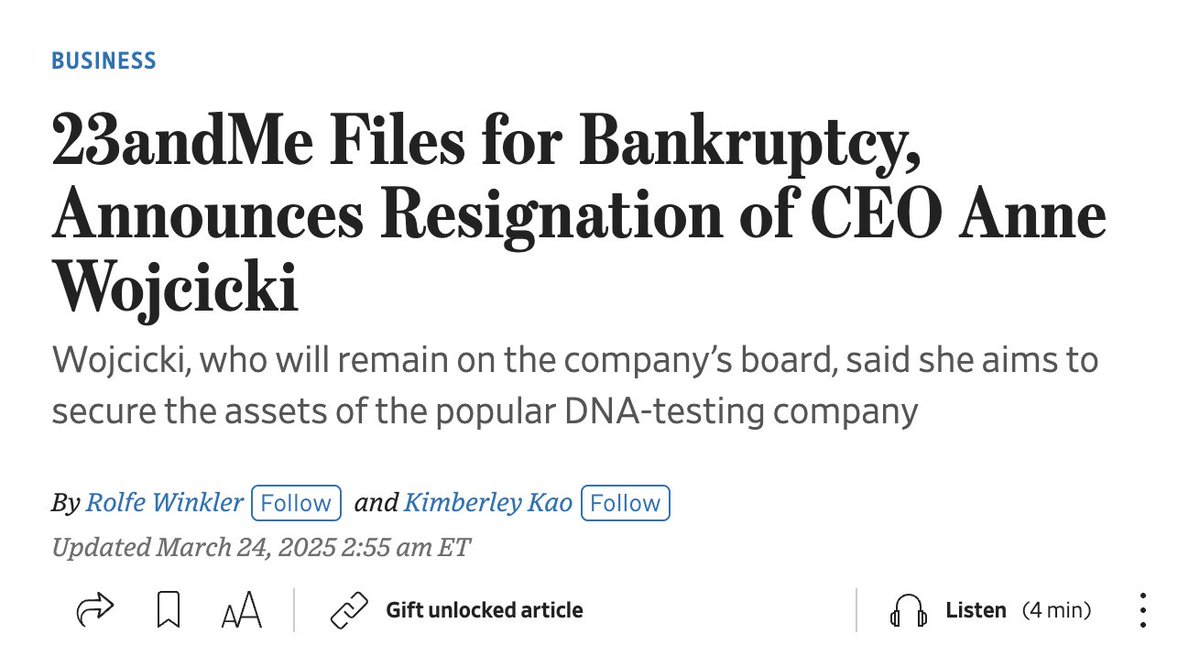
As a co-founder of 23andMe, with all the recent news I felt it was time to express my views on the company, after witnessing the downfall of an idea and brand that could have become the world’s leading digital health platform.
The idea for 23andMe came to me after years working in life science research across the US (San Francisco, Boston, San Diego, and DC), at companies like Applied Biosystems, Molecular Dynamics, Perlegen, and Affymetrix. In traditional research studies, it’s a very familiar pattern: data are collected toward a specific goal, analyses are performed, and papers may get published. But there was almost no way to re-engage the people who provided their samples and no provision for them to access their data. One story stuck in my mind. Augie Nieto was diagnosed with ALS or Lou Gehrig’s disease. He had the personal resources to fund a genetic study of ALS, but when he asked the researchers for his data (that he’d funded), he was informed that the research protocol didn’t permit them to share any data back with him.
I had also attended the Personalized Medicine conference at Harvard for several years in the early 2000s. Everyone waxed on about this rosy future where people would only be prescribed medications that worked for them. It sounded great, but when you do a back-of-the-envelope calculation of the data required to implement that scenario, and consider how ploddingly research progress is made, it was a pipe dream. How would the data even be collected?
23andMe represented a new model: maintaining an online connection with the users and providing them with a direct view into their DNA. Having a communication link to the people who funded their own data access, we had a unique opportunity to continue the dialog, which could help parse the connection between our DNA and health outcomes in ways no government-funded effort was doing.
This concept came out of work I did at Perlegen Sciences (2003-2005), a company with a mission to find variants in the human genome and determine their role in disease. We created gene ‘chips’ that enabled the analysis of variants in DNA across the whole genome. With these newly designed chips, the strategy was to take samples from patient cohorts, isolate and analyze the DNA, and correlate markers in patients compared to healthy controls. My job was to track down samples from patients who’d been diagnosed with various diseases and find funding to pay for the research. I met with countless disease foundations and patient advocacy groups. This is when I came across the Michael J. Fox foundation, which funded Perlegen’s first-of-its-kind study of Parkinson’s disease (and was how I met Sergey Brin, the co-founder of Google, who was a major donor to the organization).
I was already feeling the inadequacy of these studies. So many diseases we were targeting were highly complex and needed more than just a simple diagnosis. The more I dug into ‘autism’, ‘bipolar disorder’, and ‘chronic fatigue syndrome’, to name a few, it was clear we needed more insights into what drove these patient diagnoses. The bible of medical diagnosis, the Diagnostic and Statistical Manual of Mental Disorders, or DSM-4 as it was called at that time, defined the conditions according to symptoms, but many likely have subtypes with differing causal routes. It was a ‘garbage in, garbage out’ problem. If you’re not starting with a succinct patient diagnosis, the genetic signature will be garbled. And it wasn’t easy collecting DNA from patients. In traditional research protocols, it meant getting blood samples, or worse, skin punches.
Part of the answer to this problem came from attending a trade show where I came across the booth of a startup, DNA Genotek, claiming that they could get high-quality DNA from a spit sample. Out of curiosity I grabbed a kit and took it back to Perlegen. The scientists were a bit dubious, but were willing to do a test run. And I was recruited to be the ‘spitter’. Soon after, I found out it had worked beautifully. I was even more intrigued when they said they’d run my DNA across one of our GWAS chips. My data were sitting on a server in the company, and I was immediately hooked. Could I get a copy? This question raised far more concerns than I would have anticipated. Our HR department made me sign a release that I wouldn’t hold the company responsible for what I might learn.
A lightbulb went on–if I was interested in accessing my own data, wouldn’t others feel the same way? Getting deeply personalized information about what makes us ‘us’ seemed undeniable. It didn’t take long for the concept to unfold. I’d then moved to Affymetrix where I floated the idea of a consumer-focused genetics startup to the management. To this day, I’m grateful to Steve Fodor, Sue Siegel, Gregg Fergus, Thane Krieiner, and others who supported my mission to run with it.
Building a website for consumers to learn about their DNA was no small challenge. It took us over a year to build a secure database, research the scientific implications behind the genetic markers, design the user interface, and create understandable explanations for the general public. We asked for feedback from a wide range of scientists–including a day of grilling at the Broad Institute–and we informed the head of the FDA of our plans. Our scientific advisory board was made up of experts from across the US. Soon after launch, we branched into ‘23andWe’ (our research mission), with the goal of collecting additional data through surveys.
I didn’t want to stop there. I knew we needed to keep engaging with our customers. What if we added in symptom tracking, blood test results, drug response, environmental exposure, etc? There was a wealth of information our customers could share. When we launched our initial surveys, we were pleased and surprised at the high response rate. But surveys can only collect limited data. There were so many other ways to dig deeper. And from a business model perspective, the one-and-done DNA collection step wouldn’t cut it.
On another note, I was also very vocal about the opposition to gene patents, well before the Supreme Court ruled against them in 2013. Finding genetic correlations to any human traits very clearly isn’t an invention deserving of patent protection, nor did it seem ethical. (I later found out 23andMe discoveries were being filed for patents without my knowledge.)
My time at the company was cut short in 2009, when my co-founder Anne convinced the board that she should run the company. And I must be honest, I was frustrated with the direction the company took after that point. After my departure, she architected a majority vote for herself that eliminated board governance, even as it expanded over the following funding rounds. For better or worse, the buck stopped with her. It came as no surprise when the board resigned last year.
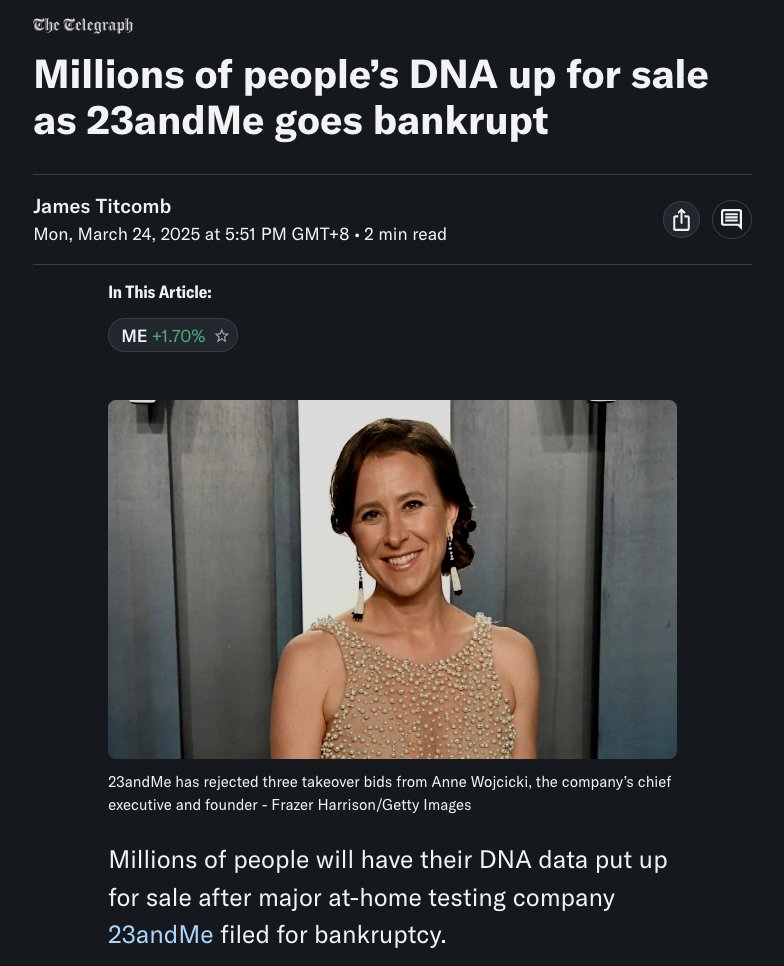
23andMe was in a unique position when it started, well before the digital health revolution got underway. It is painful to think what could have been - the category-defining Google of digital health. The company has amassed one of the largest genetic data collections in the world, and to Anne’s credit, created a terrific consumer brand. We can only imagine the importance of the dataset that could have been built, combining blood work, deeper gene sequencing, wearable data, and providing actionable insights. Now, the market is fragmented with data siloed in many different companies. Without continued consumer-focused product development, and without governance, 23andMe lost its way, and society missed a key opportunity in furthering the idea of personalized health. The 14+ million people who bought into the concept deserve to see their data moved to a secure platform with new leadership and vision. Consumers, however, should be careful sharing their data if they don’t trust its secure and ethical use.
There are many cautionary tales buried in the 23andMe story. Striking a balance between the desire for founder control and board oversight is essential; otherwise, why have a board at all? It’s a familiar trope in Silicon Valley that wealth translates into unquestionable business savvy. But no matter how great an idea, the importance of the dynamics of the founding team and their ability to listen to feedback is key.
As a venture investor, I take these learnings into the tech bio space with a realistic view of the possibilities we’re seeing. The AI-guided future of health is here, and while there will never be a moment like the post-genome era with a blue ocean digital health market, it’s possible that new companies will rise and build the dream dataset of human health. I think there are great innovations that can make this happen, and I’m excited to be a part of that future.