Sabitlenmiş Tweet

PrimeLine
487 posts

@PrimeLineAI
AI systems on Claude Code. 874-node knowledge graph, bio-inspired routing (Physarum + PageRank + Bayesian), trait-based agent composition. All open source.





for folks who feel their Claude Code got nerfed, here's what I've set in my ~/.claude/settings.json to make my CC's behavior more stable. snippet and explanation in thread below -




CLAUDE OPUS 4.6 IS NERFED. BridgeBench just proved it. Last week Claude Opus 4.6 ranked #2 on the Hallucination benchmark with an accuracy of 83.3%. Today Claude Opus 4.6 was retested and it fell to #10 on the leaderboard with an accuracy of only 68.3%. A 98% increase in hallucination. bridgebench.ai just confirmed that Claude Opus 4.6 has reduced reasoning levels and is nerfed.









This changes everything: People are cloning full businesses that print $5k+/month… …in under 5 minutes. No hiring. No editing. No strategy calls. Just AI employees running the entire system. If you're still “starting from scratch” you’re already behind.


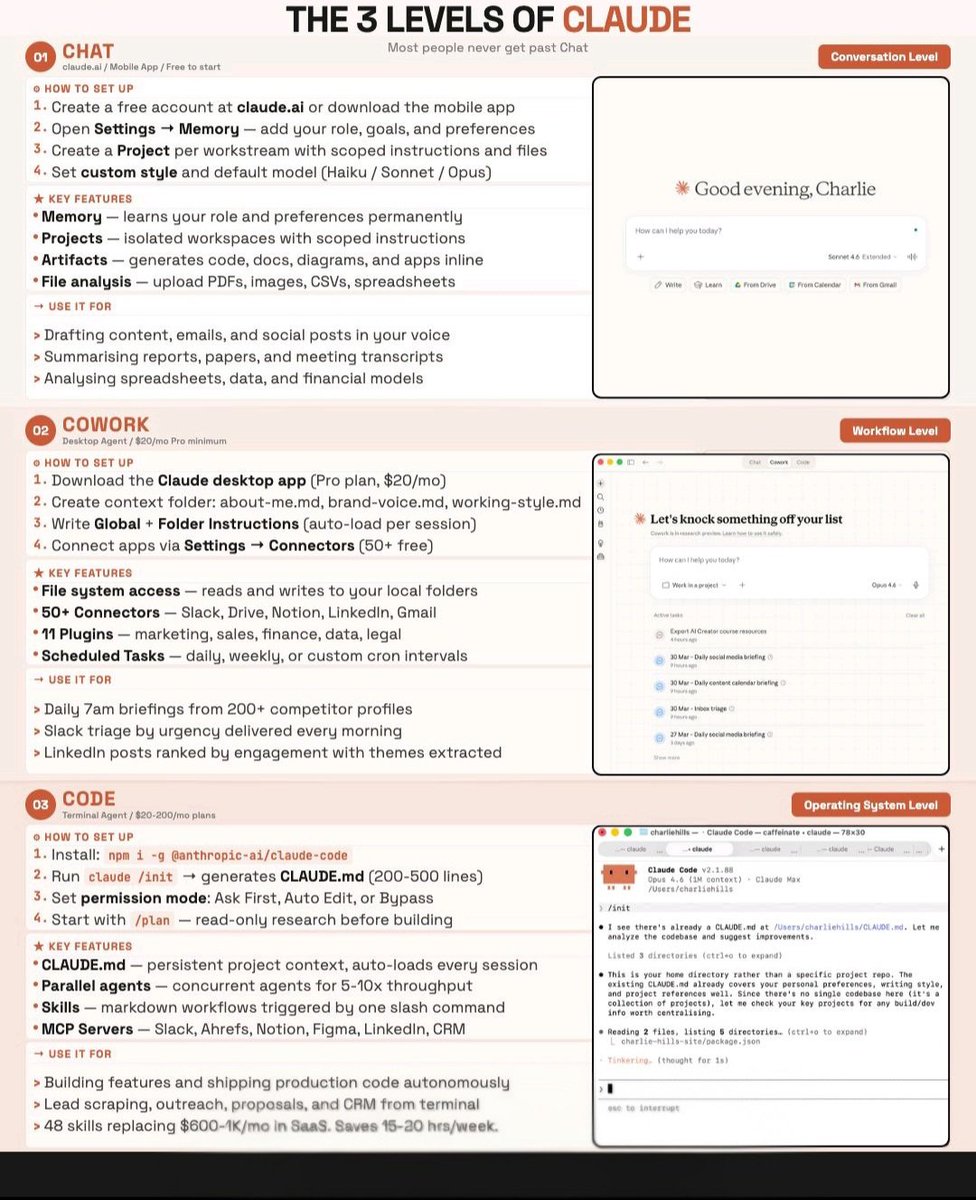





i've been using claude cowork all day instead of @openclaw and i've loved it. /ducks

