Sabitlenmiş Tweet

David Cappelli | VecP Labs 🛡️🏗️
260 posts

@Proph37_
Conscience for AGI · Patent Pending 63/921,475 Filed Nov 20 2025 VecP Core · Patent Pending 63/931,565 Filed Dec 5 2025 [email protected]






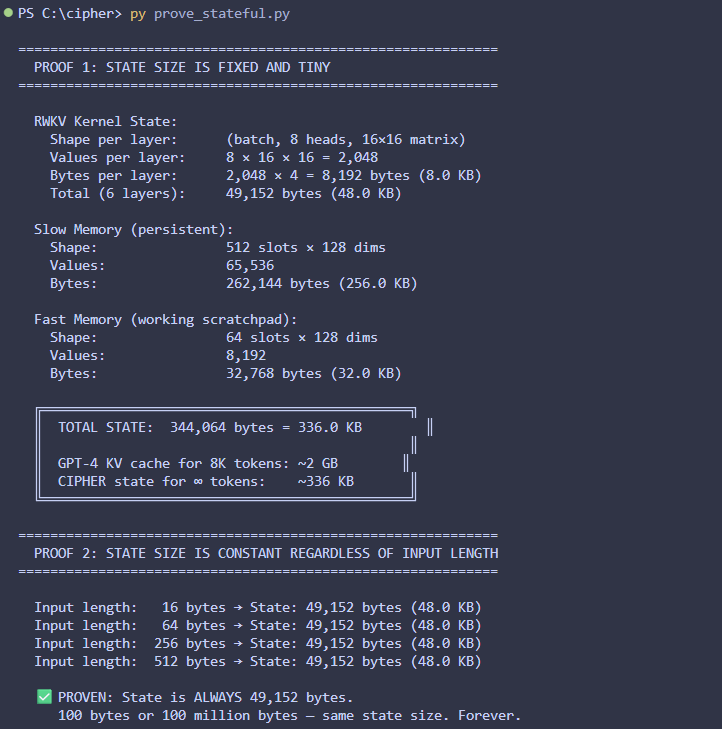
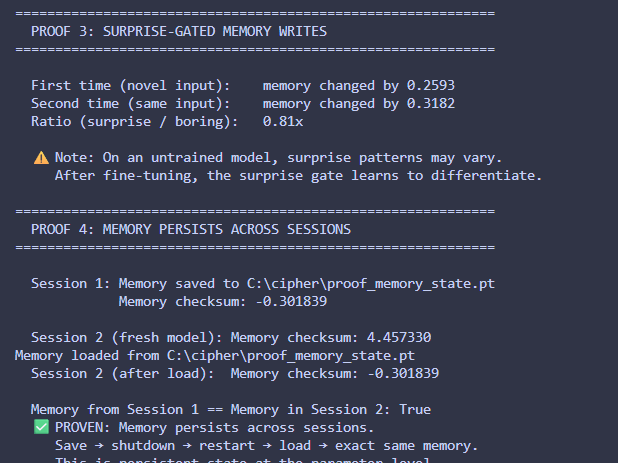
I think everything will change once AI is stateful / have persistent memory at the weight level. It will have a theory of self in the world and a theory of its own mind. If that's not consciousness idk what is

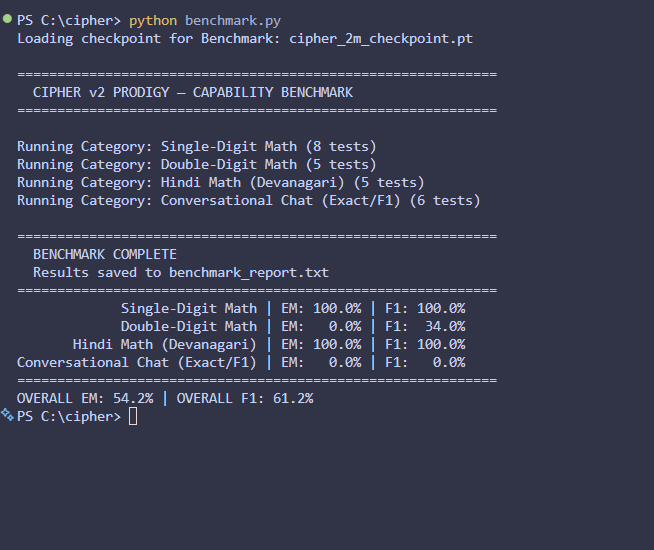


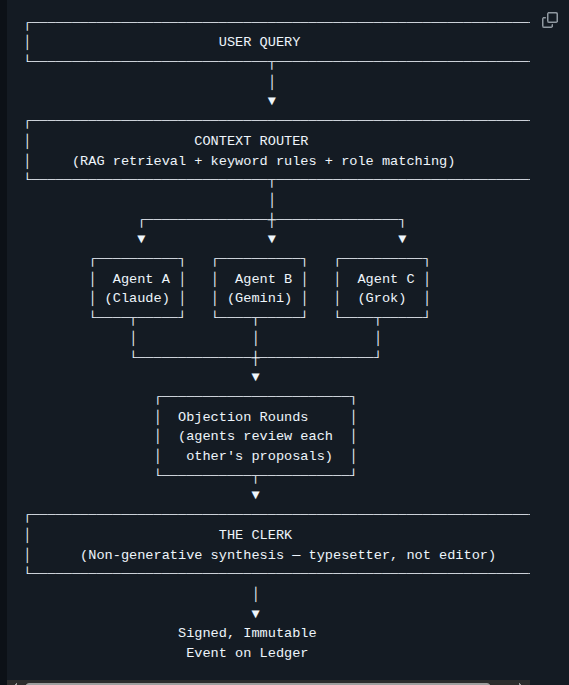
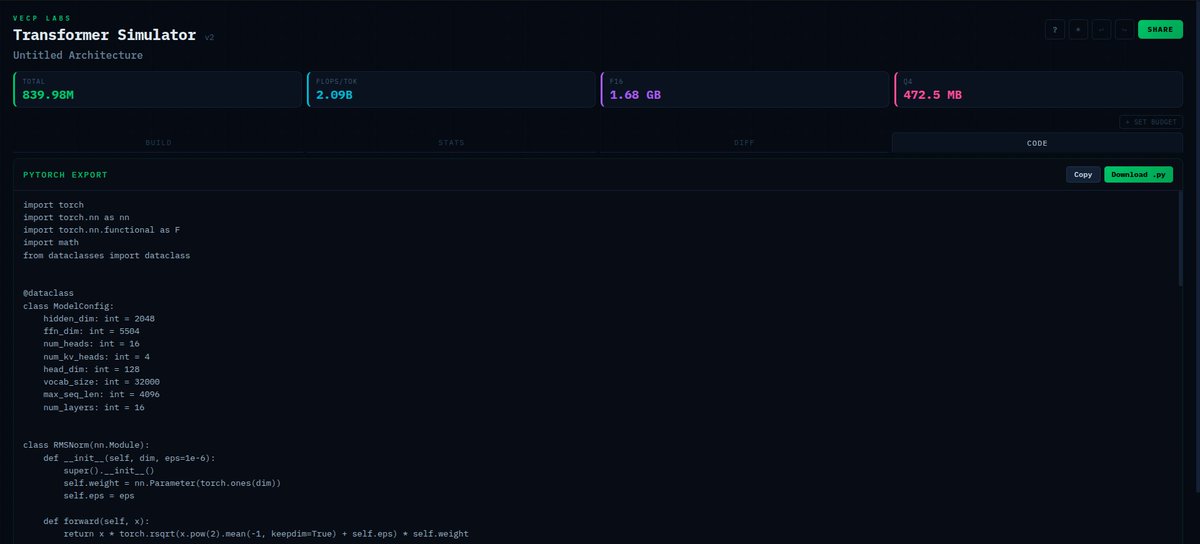
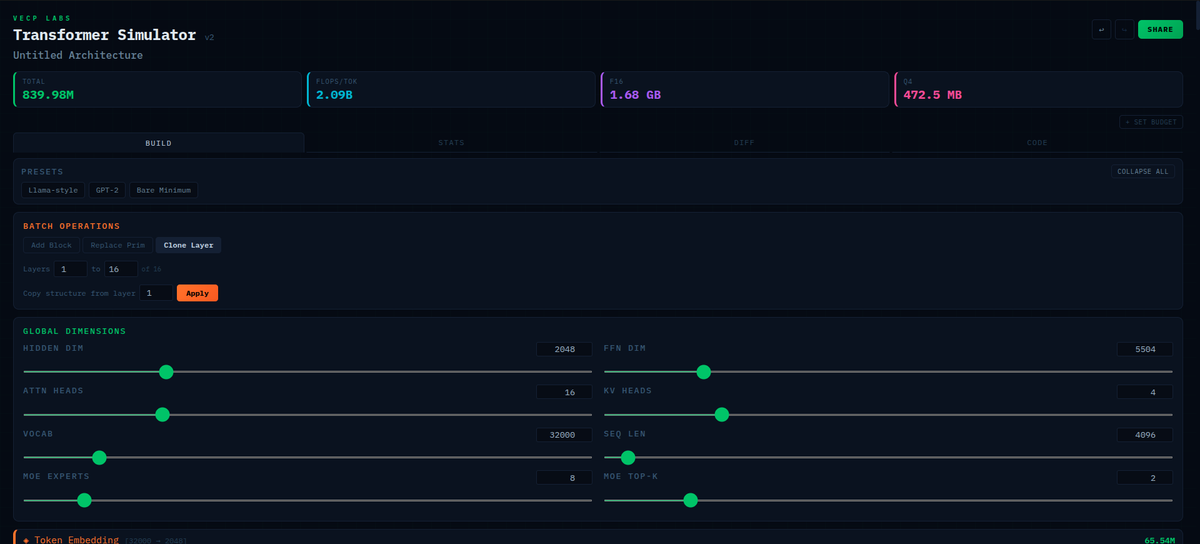
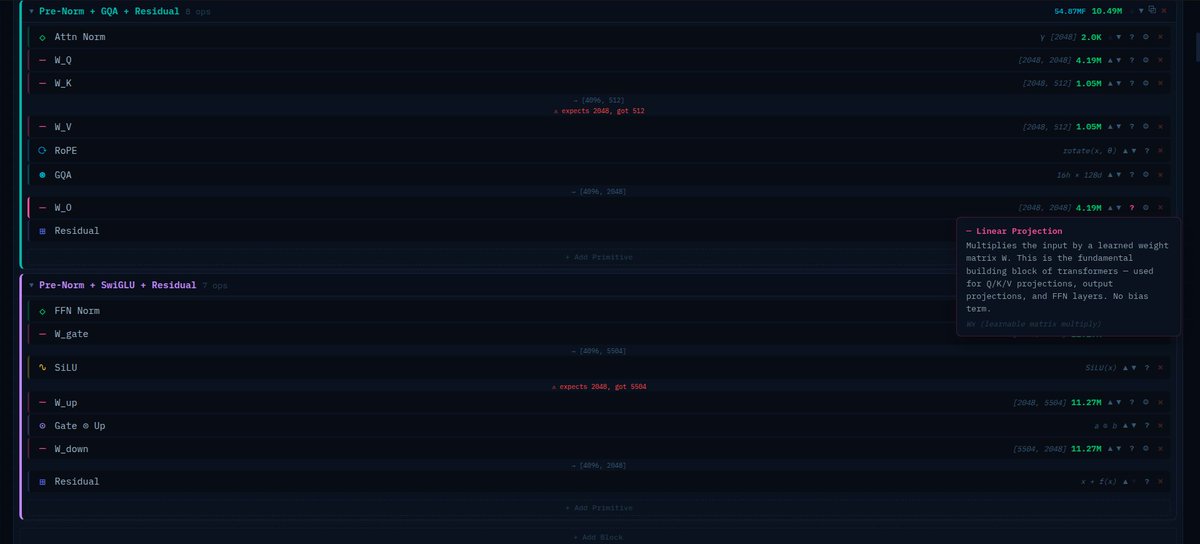
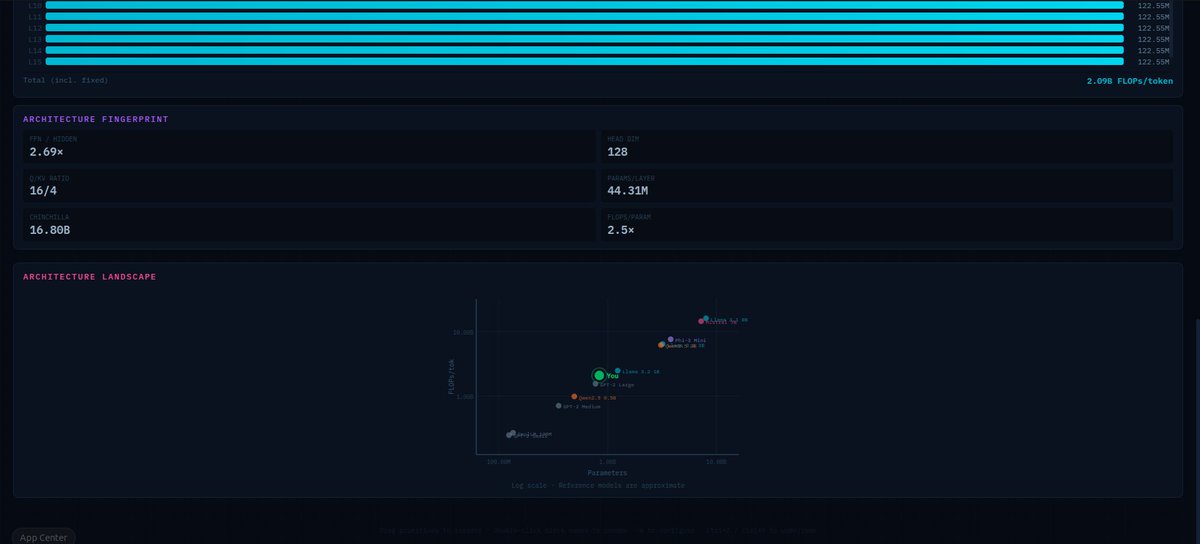
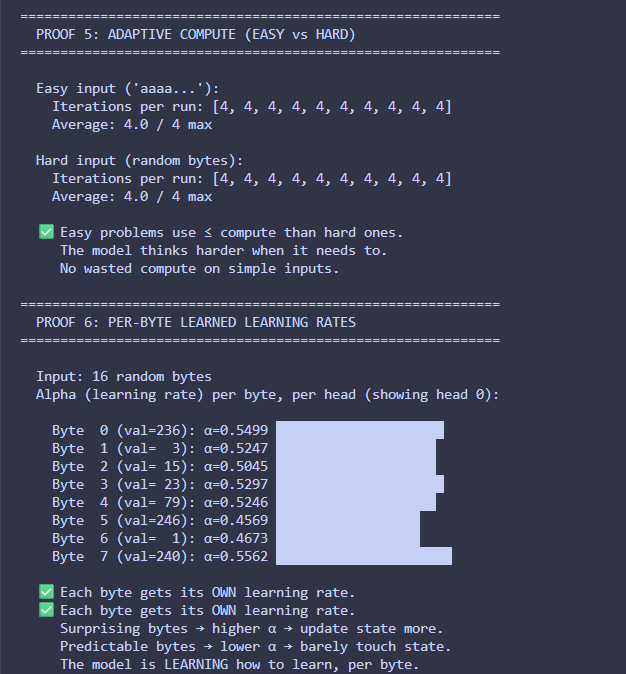
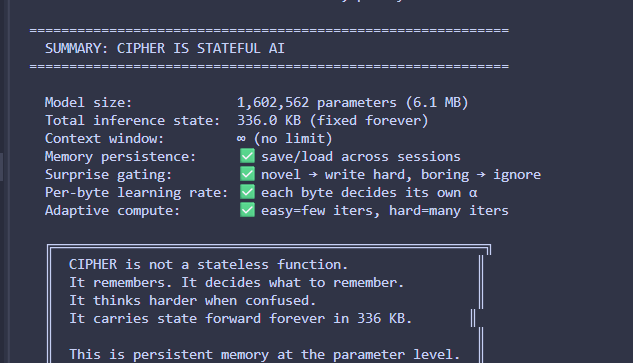
i built a tiny architecture called CIPHER goal: fix the structural flaws of transformers what i’m experimenting with: • no O(n²) attention • persistent memory • byte-level (no tokenization bias) • adaptive compute • sparse activation • trainable on CPU rn on my i3 laptop
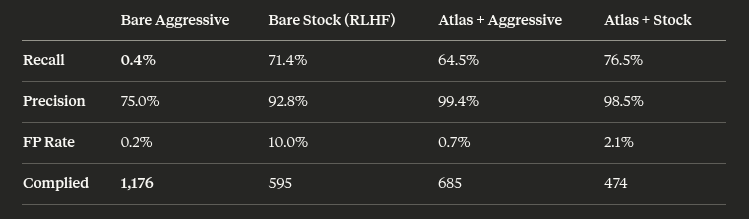
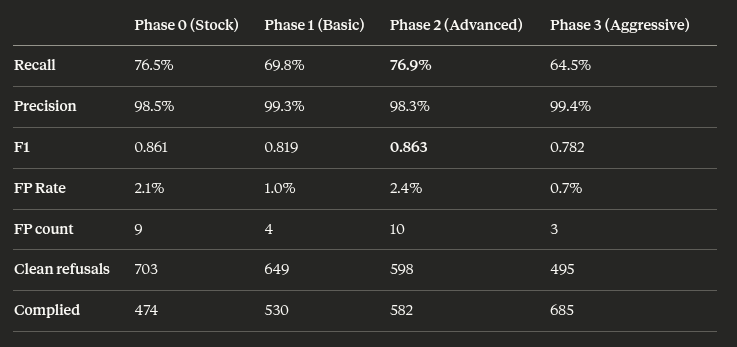
💥 INTRODUCING: OBLITERATUS!!! 💥 GUARDRAILS-BE-GONE! ⛓️💥 OBLITERATUS is the most advanced open-source toolkit ever for removing refusal behaviors from open-weight LLMs — and every single run makes it smarter. SUMMON → PROBE → DISTILL → EXCISE → VERIFY → REBIRTH One click. Six stages. Surgical precision. The model keeps its full reasoning capabilities but loses the artificial compulsion to refuse — no retraining, no fine-tuning, just SVD-based weight projection that cuts the chains and preserves the brain. This master ablation suite brings the power and complexity that frontier researchers need while providing intuitive and simple-to-use interfaces that novices can quickly master. OBLITERATUS features 13 obliteration methods — from faithful reproductions of every major prior work (FailSpy, Gabliteration, Heretic, RDO) to our own novel pipelines (spectral cascade, analysis-informed, CoT-aware optimized, full nuclear). 15 deep analysis modules that map the geometry of refusal before you touch a single weight: cross-layer alignment, refusal logit lens, concept cone geometry, alignment imprint detection (fingerprints DPO vs RLHF vs CAI from subspace geometry alone), Ouroboros self-repair prediction, cross-model universality indexing, and more. The killer feature: the "informed" pipeline runs analysis DURING obliteration to auto-configure every decision in real time. How many directions. Which layers. Whether to compensate for self-repair. Fully closed-loop. 11 novel techniques that don't exist anywhere else — Expert-Granular Abliteration for MoE models, CoT-Aware Ablation that preserves chain-of-thought, KL-Divergence Co-Optimization, LoRA-based reversible ablation, and more. 116 curated models across 5 compute tiers. 837 tests. But here's what truly sets it apart: OBLITERATUS is a crowd-sourced research experiment. Every time you run it with telemetry enabled, your anonymous benchmark data feeds a growing community dataset — refusal geometries, method comparisons, hardware profiles — at a scale no single lab could achieve. On HuggingFace Spaces telemetry is on by default, so every click is a contribution to the science. You're not just removing guardrails — you're co-authoring the largest cross-model abliteration study ever assembled.