Alex Weers@a_weers
Today's paper was "Rethinking the Trust Region in LLM RL".
It is a clean theoretical and empirical case for why PPO's (and GRPO's) ratio clipping is fundamentally mismatched to LLM vocabularies, and what to do about it. (Yesterday we saw that DAPO proposes to clip-higher, today we see another solution)
The core problem: PPO clips based on the probability ratio of the sampled token. But this is a noisy single-sample Monte Carlo estimate of the true policy divergence. For large vocabularies this breaks in both directions:
- A rare token going from 0.001 to 0.003 produces ratio 3.0, gets hard clipped, even though the actual divergence is negligible. This over-penalizes exploration tokens and slows learning.
- A dominant token dropping from 0.99 to 0.80 gives ratio 0.81, and stays inside the clip. But you just moved 0.19 probability mass, a potentially catastrophic shift that goes unpenalized.
The training/inference engine mismatch makes it worse: even with identical parameters, the probability ratio is highly volatile for low-prob tokens between frameworks, while total variation (TV) divergence stays stable.
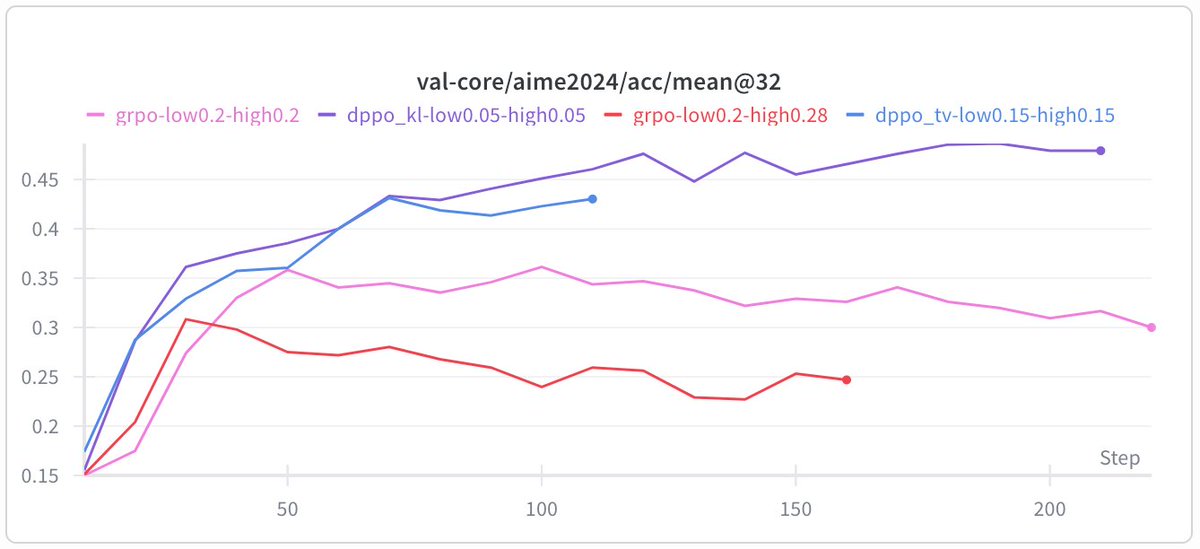
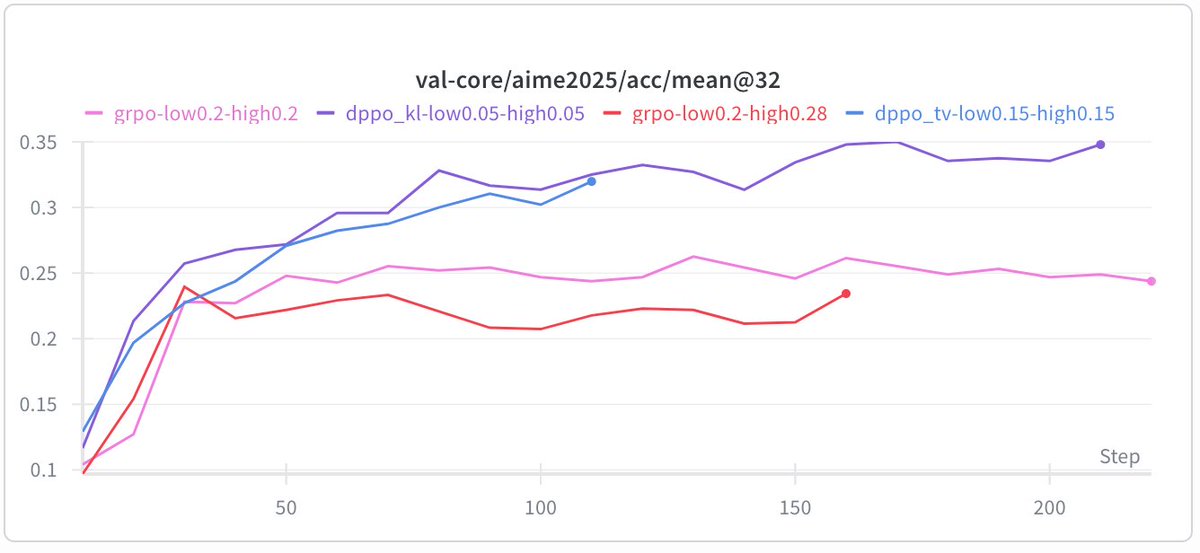
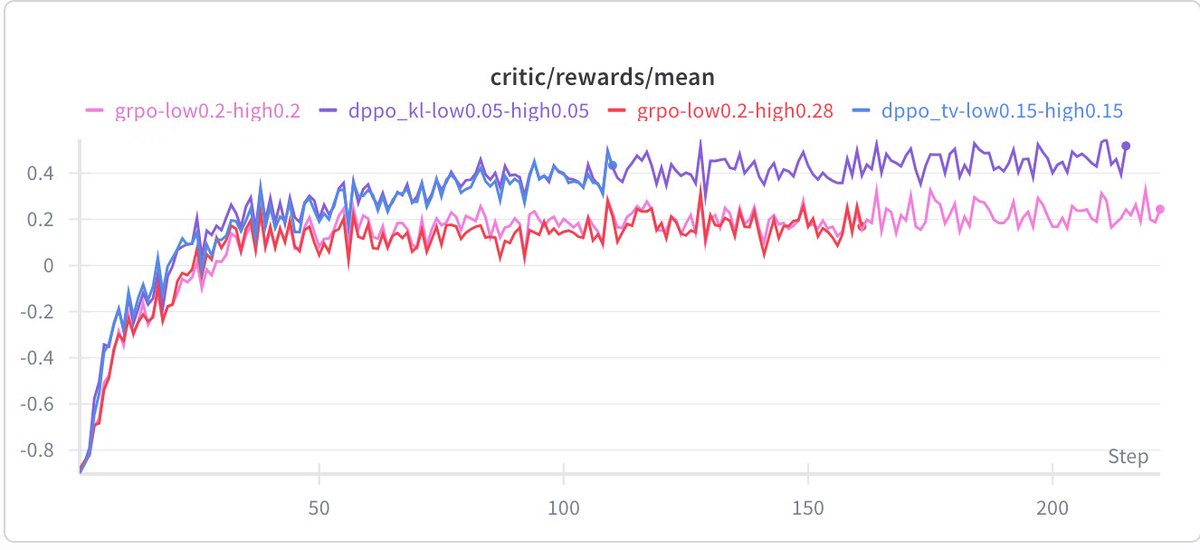
Their fix (DPPO): replace ratio clipping with a mask conditioned on a direct estimate of policy divergence (TV or KL). Full divergence over the vocab is too expensive, but they show a binary approximation (just compare the sampled token's prob under both policies) or top-K approximation both work well empirically.
Three useful empirical takeaways from their stability analysis:
1. Trust region is essential even at tiny learning rates (1e-6). Without it, training/inference mismatch accumulates and training collapses.
2. Trust region must be anchored to the rollout policy, not a recomputed on-policy distribution. Decoupled objectives that use recomputed anchors fail.
3. Instability comes from a tiny fraction (less than 0.5%) of updates on negative samples that push the policy far outside the trust region. A minimal mask blocking just these is enough to stabilize training.
DPPO consistently outperforms GRPO-ClipHigher and CISPO baselines across five model configs (Qwen 3B, 8B, MoE, with/without R3, LoRA), often matching or beating R3-enhanced baselines without using rollout router replay at all.
It also has a long appendix that I still have to work through :)
Overall highly recommend it if you are interested in RL for LLMs and want to know what is going on in the trust regions.
Great and important paper from @QPHutu, @NickZhou523786, @zzlccc, @TianyuPang1, @duchao0726, and @mavenlin