Lance Martin retweetledi

Lance Martin
1.3K posts


@RLanceMartin
MTS @anthropicai


Patching these vulnerabilities will make us safer. But the software industry will need to adapt to the volume of vulnerabilities that models like Claude Mythos Preview will be able to find. We discuss this in our initial update on Project Glasswing: anthropic.com/research/glass…




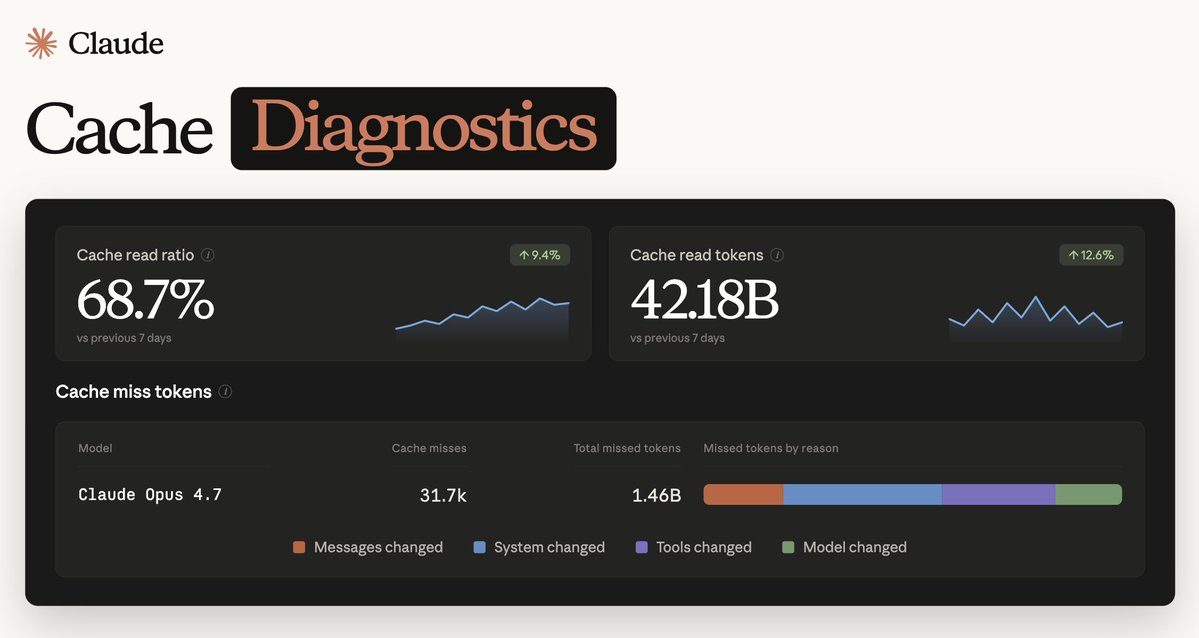
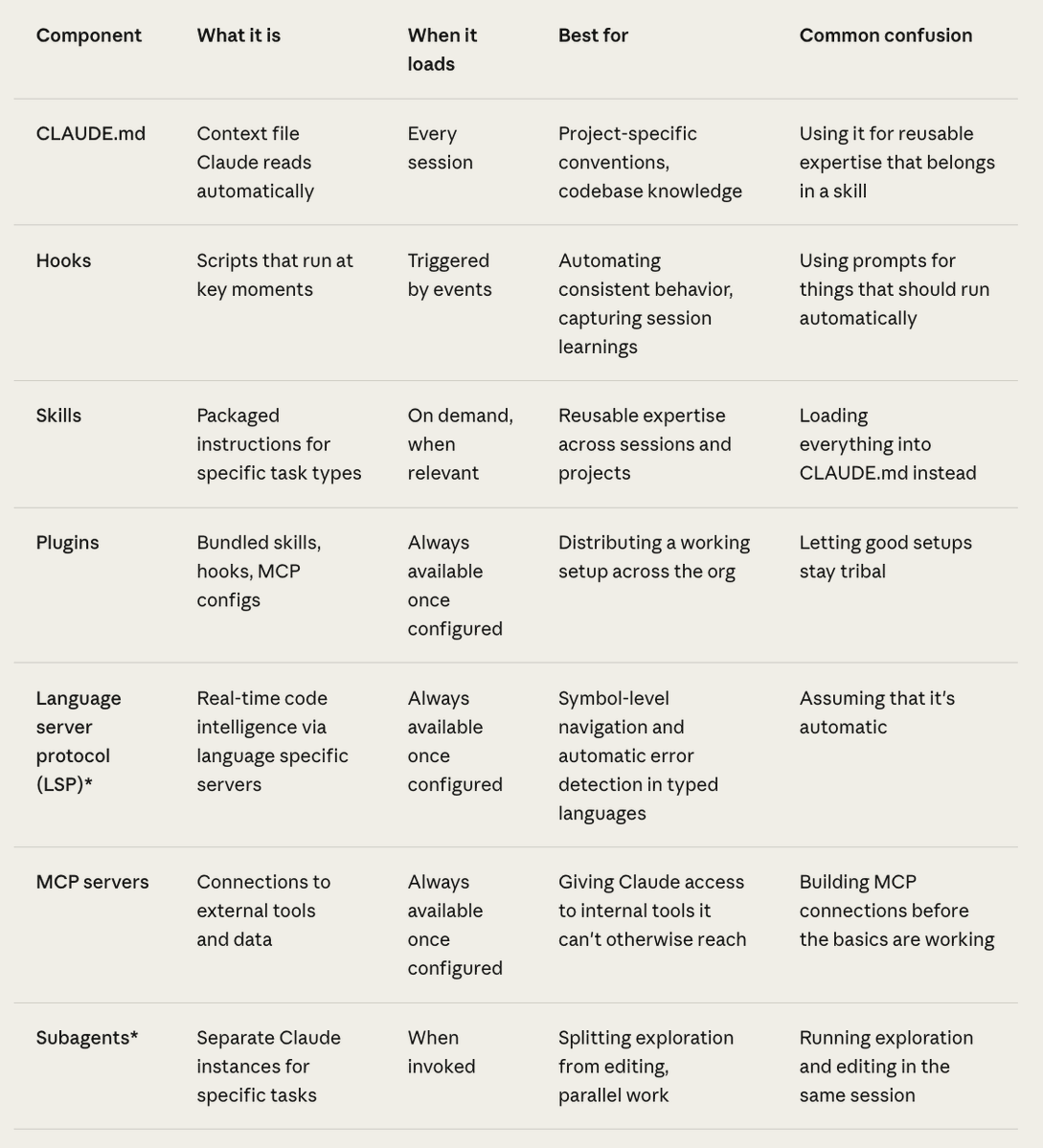
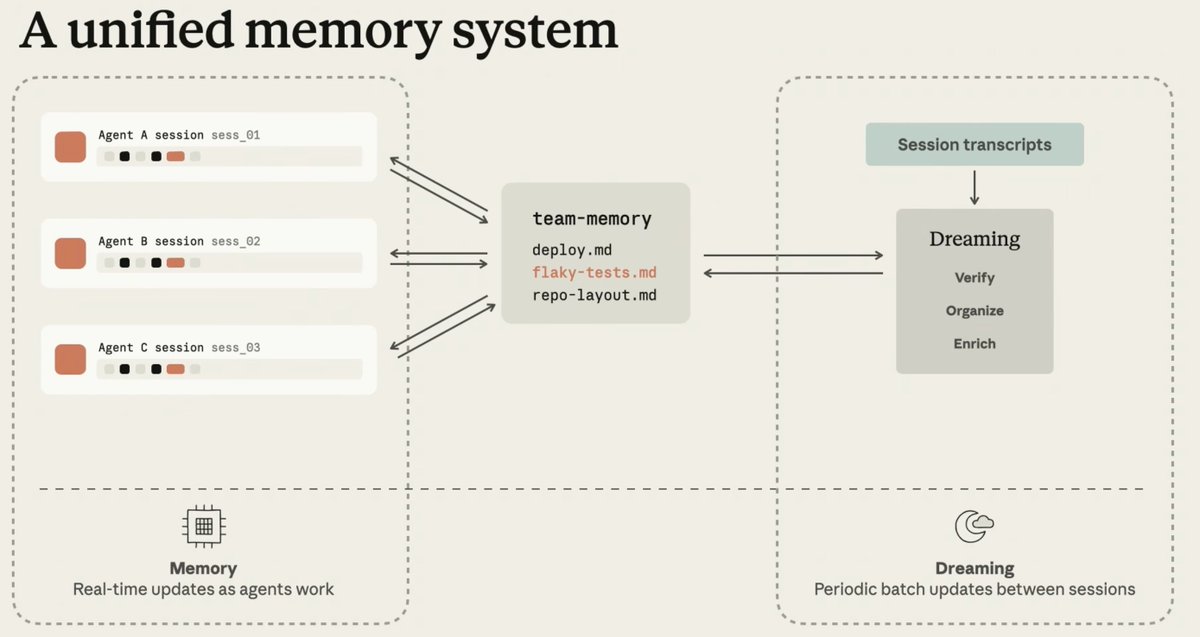
Claude Code ships with a built-in skill for working with the Claude Platform. Useful for model migrations, using API features (e.g., prompt caching), or onboarding to newer APIs like Claude Managed Agents.