Roger Waleffe retweetledi

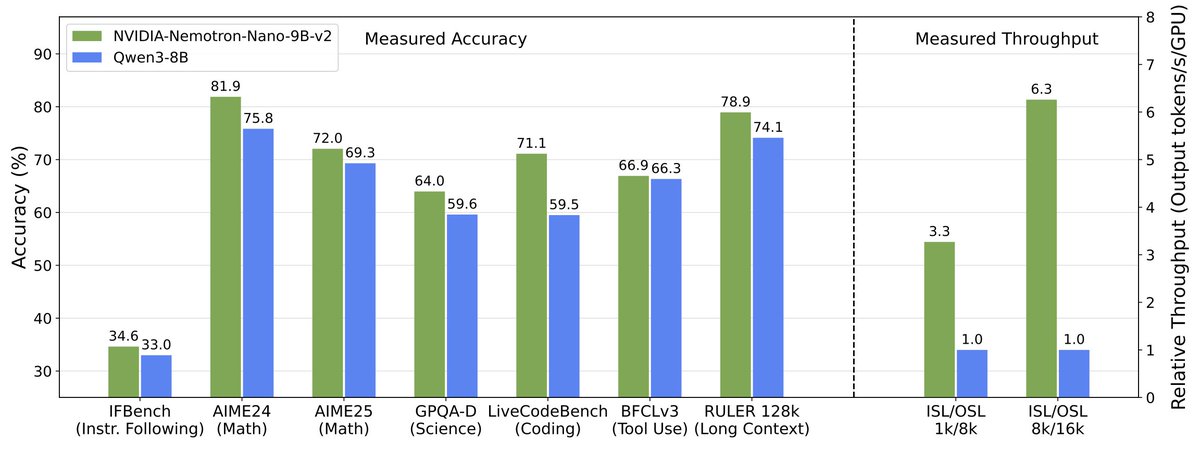
Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.

English