Sabitlenmiş Tweet
Rabdos_AI
23 posts


Rabdos_AI
@Rabdos_AI
Cartographers of the jagged frontier of mathematics and AI and more... A Math-AI startup company founded by academics & grounded in research.
Philadelphia PA Katılım Nisan 2026
67 Takip Edilen120 Takipçiler
We are delighted to unveil our research blog Rabdology at rabdology.ai, where we chart the jagged math-frontier of AI reasoning.
This is our first post in a weekly series. Read on, and if you enjoy it, please subscribe! (Link at bottom of blog's main page.)
The Three-Cylinders Problem: When AI models choose Beauty over Truth
rabdology.ai/three-cylinders
We pose a problem that a good geometry student can solve in twenty minutes. We gave it to four of the world’s most advanced AI models and watched what happened. Three of them got it wrong — and the way they got it wrong tells you something different about the state of AI mathematical reasoning than the usual benchmarks.
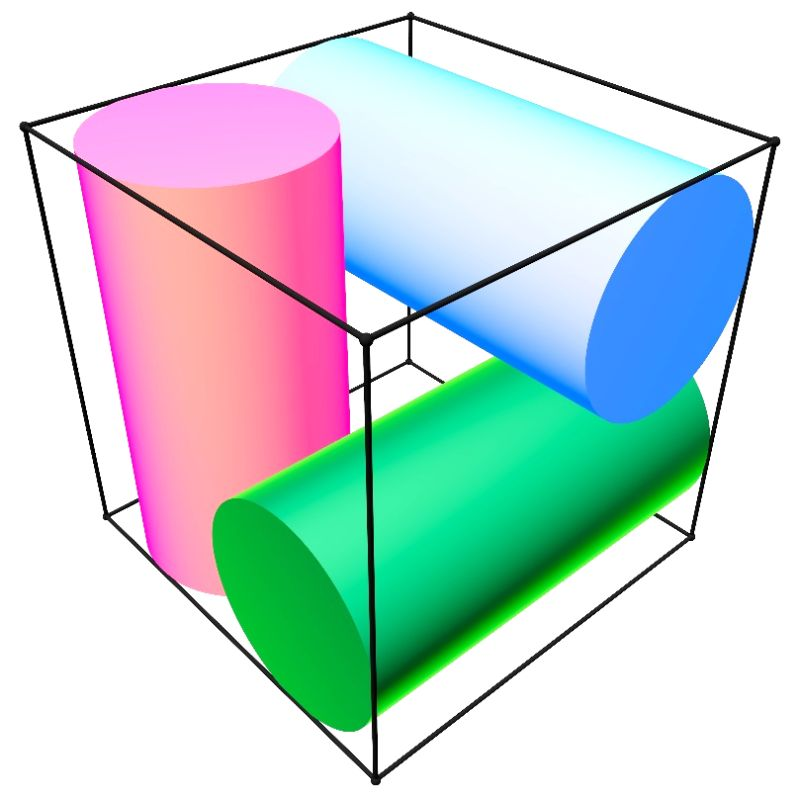
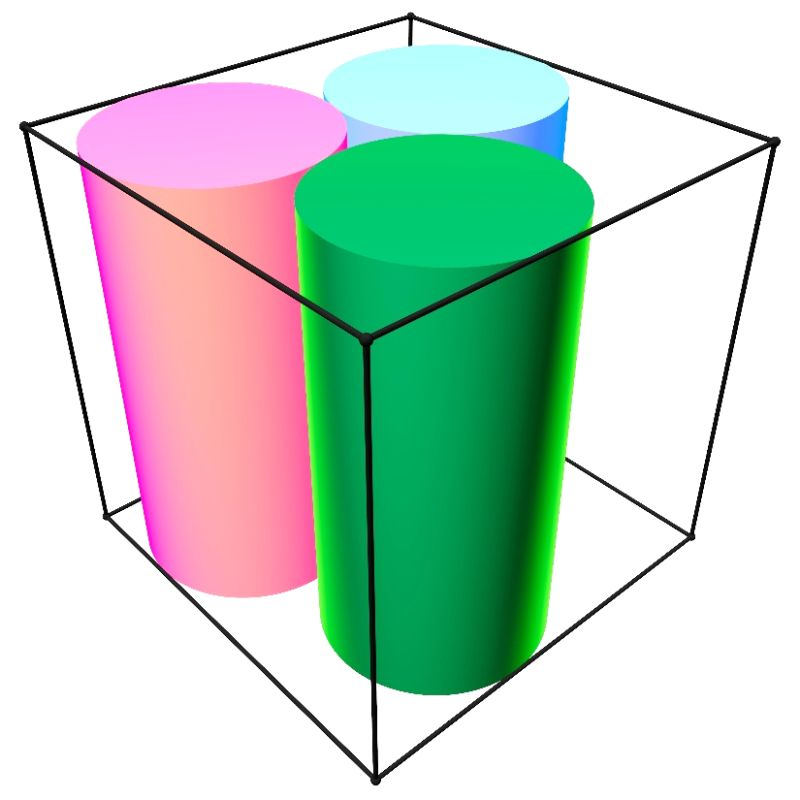
English
Rabdos_AI retweetledi

Very timely, especially in light of revelation that 1/3rd of problems in FrontierMath are fatally flawed.
As expert human validation of frontier math tasks approaches its inevitable limit, LLMs are stepping in to fill the void.
But our work below shows that the discovery of mistakes in FrontierMath problems didn't necessarily have to wait for a frontier model like GPT-5.5. Much smaller and even open-source models can be as effective at verifying math proofs: their weights embody the necessary knowledge, as one might expect -- checking proofs ought to be easier than writing proofs.
The crucial thing that makes this work is the use of "prompt ensembles", each of which modularly checks a different facet of a given proof, and some of which are even specific to the domain/sub-domain of math.
Ideas like meta-prompting, agent skills, and autoresearch will undoubtedly evolve to make LLMs as judges of math proofs even more effective in future.
guru@guruprerana
Do we need frontier models to verify math proofs? EpochAI just announced that they found several fatal flaws in their FrontierMath benchmark using GPT-5.5. But isn't verification supposed to be easier than generation, so why were they not spotted earlier? In our recent work, we asked a related question: do we really need frontier-scale compute to verify Olympiad-level math proofs? Turns out, even 20B open-source models can keep up with frontier LLMs on proof verification. Work done with my co-authors @aaditya_naik, @AI4Code, and @RajeevAlur Preprint: arxiv.org/abs/2604.02450
English
Thanks for the question:
Average accuracy on MathDuels:
Solving their own problems: ~92%
Solving others' problems: ~88%
Producing the correct answer at authoring stage: ~86%
Takeaways:
1. Models have a small edge on their own problems.
2. Solving is easier than constructing & giving the correct answer.
English

@Rabdos_AI How do models do on their own problems (if one instantiates them again)?
English
In MathDuels leaderboard, Gemini-3-Flash dominates at its size: the only models ahead of it are the latest, largest frontier releases.
Gemma-4-31b-it has the highest author rating of any opensource model.
Thanks @GoogleDeepMind for these smart little models 🥹
Rabdos_AI@Rabdos_AI
Static math benchmarks saturate. We built one that doesn't. Announcing MathDuels, the first self-play math benchmark. Every frontier LLM writes problems for the others, and is graded on the ones written for it. As models improve, so does the benchmark.
English
@JasonRute That said, it'd be interesting to see models leverage the asymmetry here: creating problems that are way harder to solve than to construct. (like you mentioned)
There are some samples of generated problems on mathduels.ai. None of them relies on construction asymmetry.
English

@Rabdos_AI How do you prevent the model from submitting problems like “factor this really large number I just multiplied together” or whatever the mathematical equivalent of that is in each domain?
English
@JasonRute We didn't observe this in our experiments, for two reasons:
1. The author prompt discourages problems that are merely computationally difficult.
2. Models don't have Python tools available during the author stage.
English
@somi_ai We use an independent verifier LLM to determine which answer is correct (golden solution v.s. solvers' solutions).
This turns out to be reliable: when using different verifiers (GPT-5.4 & Gemini-3.1-Pro), the result is the same at 99.4% of the time. (Section 4.3 in the paper)
English

@Rabdos_AI is the answer key the writer's claimed solution or an independent reference? at frontier difficulty the writer being wrong about their own problem is a real failure mode here
English
MathDuels aims to make math evaluation less dependent on a fixed pool of human-written problems. It will keep evolving at mathduels.ai as new models arrive.
Work done by researchers at University of Pennsylvania and @Rabdos_AI, a startup charting the mathematical frontier of AI.
📊 Leaderboard: mathduels.ai
📄Paper: arxiv.org/abs/2604.21916
Want your model on the leaderboard? DM us!
English
Another observation: thinking effort matters less for Authoring than Solving.
Dropping Gemini-3.1-Pro to low thinking moves its Solve Rating rank from 2nd to 19th, while its Author Rating rank drops from 2nd to 10th. The same pattern holds for GPT-5.4 and Gemini-3-Flash.
English
Rabdos_AI retweetledi

How it feels to be a trained mathematician using various AI models to explore proof space. The AI is almost always directionally correct with a proof but is almost always wrong in some subtle way.
You need to "zip up the shoggoth"
∞-modal@NoahChrein
How it feels to comath with AI in April 2026
English


Rabdos_AI retweetledi

