Sabitlenmiş Tweet

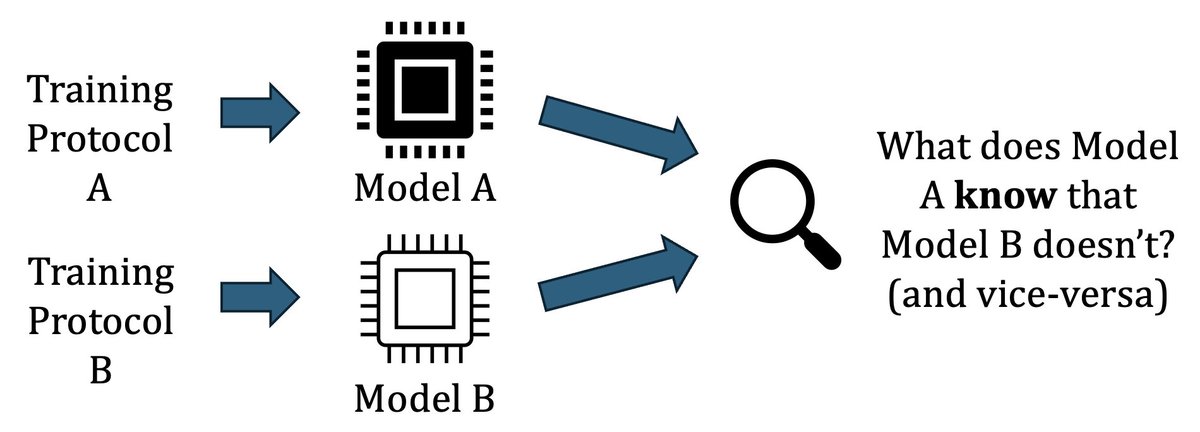
🤓 How do LVLM/LMMMs reason about space and time?
This was the central question of our #ICLR2016 paper, “Linear Mechanisms For Spatiotemporal Reasoning In Vision Language Models”. I’m very excited to finally share it:D 🥳🥳
A thread: [1/7]

English